 mjourdan
commented
6 years ago
mjourdan
commented
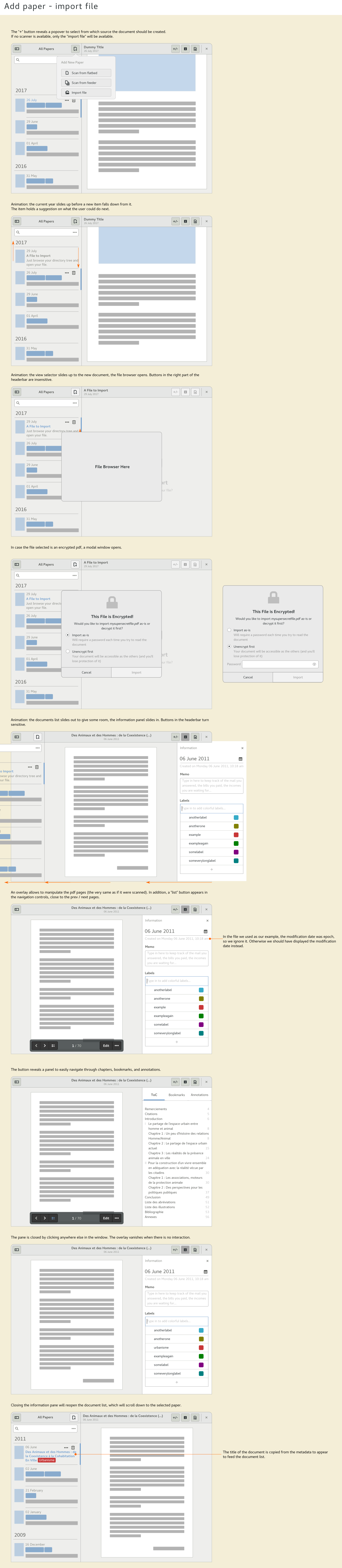
6 years ago Please find experimental wireframes to import pdf. This should cover all of the issues above (except #244).
Open mjourdan opened 6 years ago
mjourdan
commented
6 years ago Please find experimental wireframes to import pdf. This should cover all of the issues above (except #244).
 jflesch
commented
6 years ago
jflesch
commented
6 years ago Hm, regarding unencrypted PDF files, I don't feel at ease with asking password every time the user wants to open it. Looks like a nice source of bugs :/
jflesch
commented
6 years ago However, the password could be stored unencrypted besides the PDF files (in which case, it's up to the user to secure all their papers).
 tido-
commented
6 years ago
tido-
commented
6 years ago If you face a complex problem, break it down into smaller pieces, leave exceptions away (encrypted) file. Same is true for "Allow pdf manipulation" leave exceptions away. Instead of adding complex features for just a few, I would focus on functionality that is valuable for many.
To extract metadata with phyton https://pypi.python.org/pypi/pdfminer3k last Version 1.3.1 – 2016/11/05. Something like this could help to enrich the import of a PDF with proper metadata. As you wrote it is tricky to read that out, what are the hurdles to overcome? Date, if US- or European-format, does it differ? Title, keywords or table of content - if the PDF is just the container for a scanned document, how would this turn out?
Edit: was late yesterday, edited my post.
{kind=link}
(This ticket is here to keep track of all pdf related issue)
Description
We have a number of ticket to improve the UX while dealing with pdf documents. The goal is to make paperwork a more-than-decent document reader.
Issues
Importing pdf:
Supporting pdf's basic features:
Later: