 Tpt
commented
3 years ago
Tpt
commented
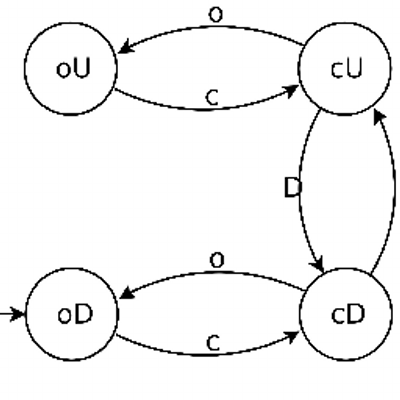
3 years ago Thank you for this bug report! I should have indeed added support for surrogate pairs. I have just implemented them and released a v0.1.1 version. Your test now passes. Thank you again!
 bmeck
bmeck
JSON uses 2 byte hex encoding for unicode escapes. This can cause lone surrogate problems in UTF-8 encodings that need 4 bytes ( see https://unicode-example-characters.glitch.me/ ). For example:
🔥 can be encoded as "\ud83d\udd25". 🚸🚯 can be encoded as "\ud83d\udeb8\ud83d\udeaf".
Currently attempting to decode these results in errors: