 rabernat
commented
6 years ago
rabernat
commented
6 years ago Here is an alternative, more "cloudy" way this might work:
- We develop a CLI that allow us to upload netcdf files, e.g
pangeo-upload-dataset --bucket path/to/bucket -chunks time:1,depth:1 *.nc - Each netcdf file is stored in a temporary bucket
- Some sort of load-balanced pool of workers waits for each individual upload to complete and then kicks off a job that
- transcodes the netcdf file to zarr
- deletes the temporary file
In this case, we would end up with many zarr stores, just like we have many netcdf files. We would need an open_multizarr function in xarray to simplify automatic concatenation of such stores.
 mrocklin
mrocklin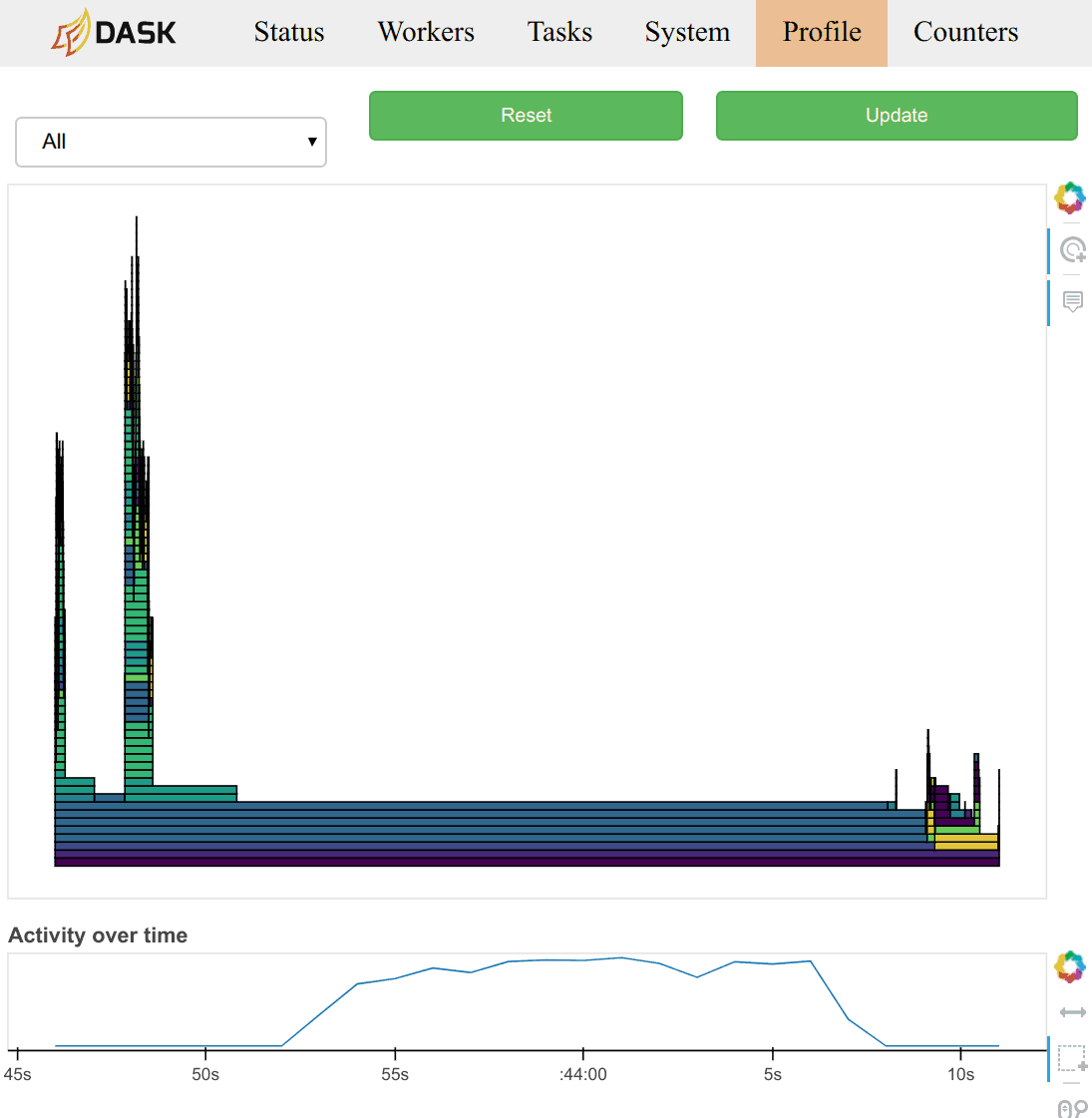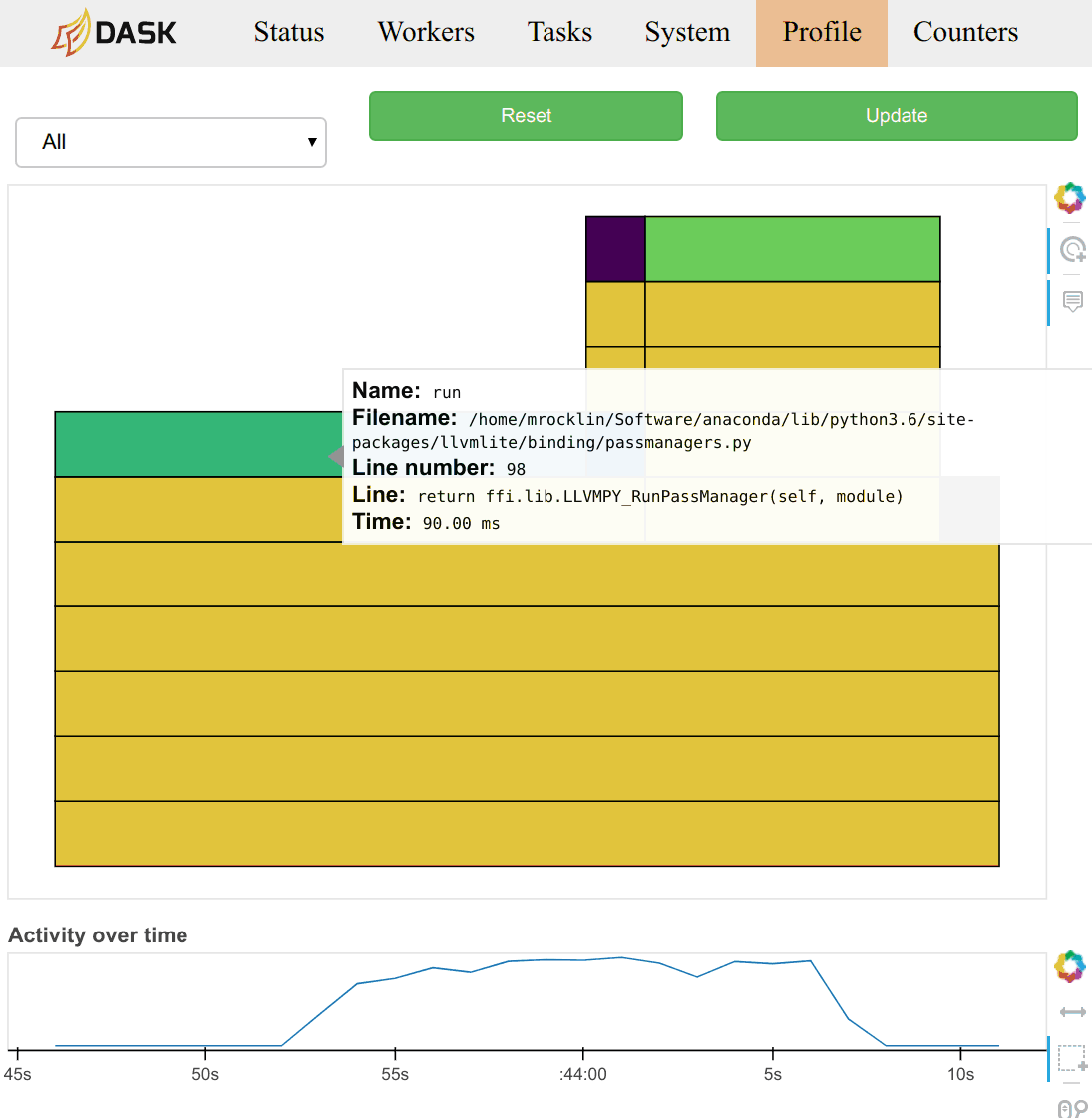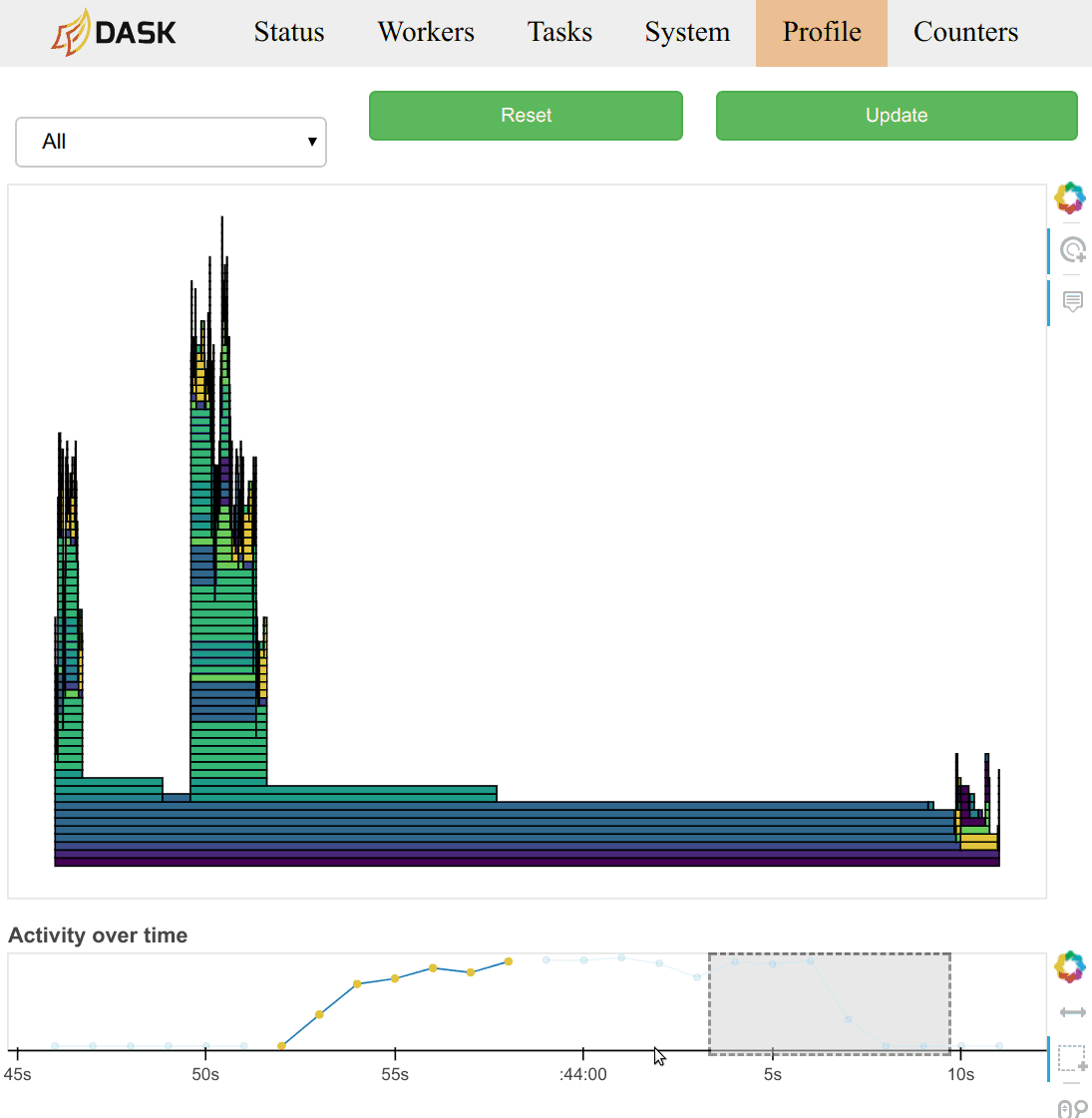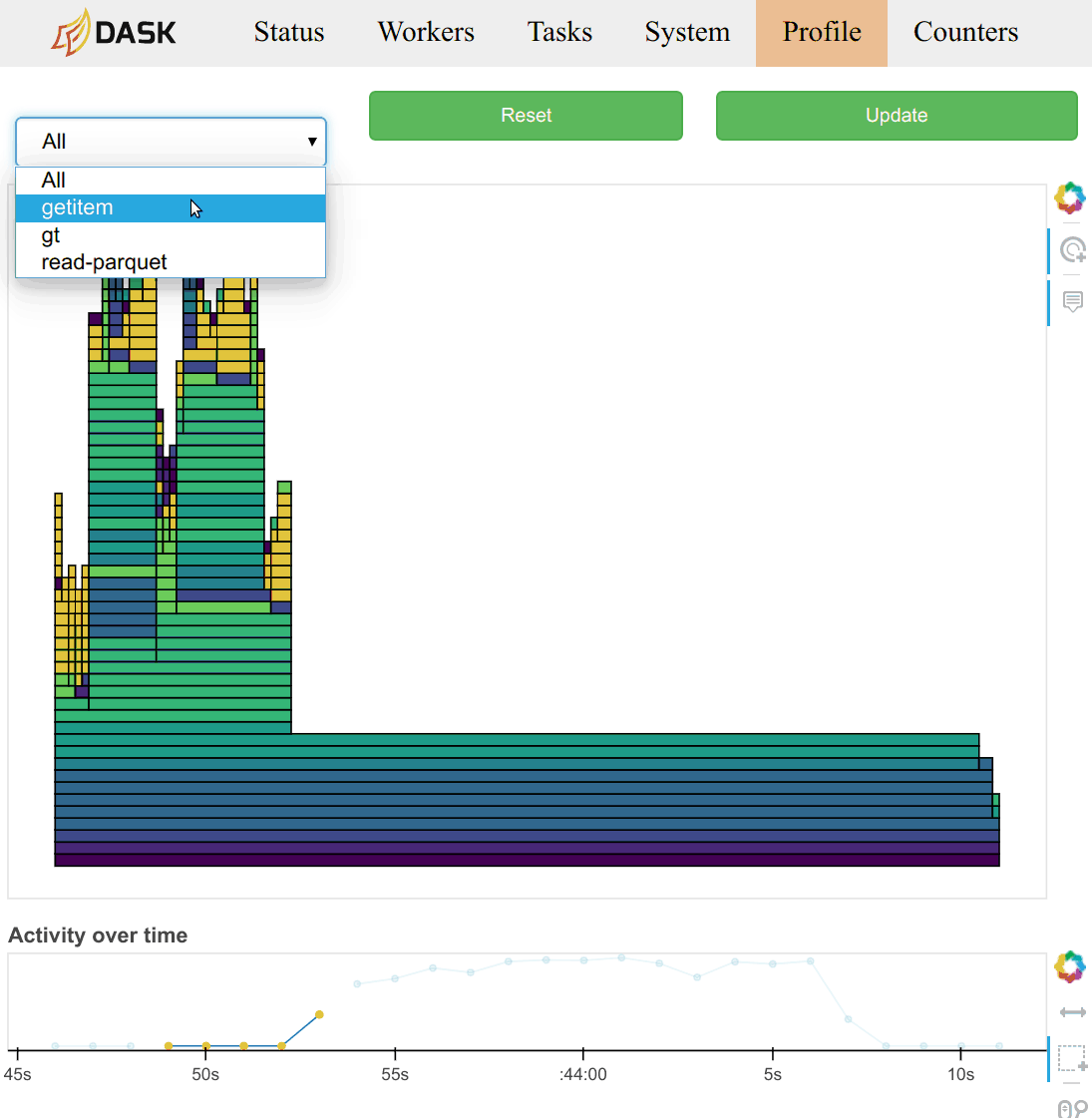
 jhamman
jhamman
 alimanfoo
alimanfoo martindurant
martindurant
I am currently transferring a pretty large dataset (~11 TB) from a local server to gcs. Here is an abridged version basic workflow:
Each chunk in the dataset has 2700 x 3600 elements (about 75 MB), and there are 292000 total chunks in the dataset.
I am doing this through dask.distributed using a single, multi-threaded worker (24 threads). I am watching the progress through the dashboard.
Once I call
to_zarr, it takes a long time before anything happens (about 1 hour). I can't figure out what dask is doing during this time. At some point the client errors with the following exception:tornado.application - ERROR - Future <tornado.concurrent.Future object at 0x7fe371f58a58> exception was never retrieved. Nevertheless, the computation eventually hits the scheduler, and I can watch its progress.I can see that there are over 1 million tasks. Most of the time is being spent in tasks called
open_dataset-concatenateandstore-concatenate. There are 315360 of each task, and each takes about ~20s. Doing the math, at this rate it will take a couple of days to upload the data, this is slower than scp by a factor of 2-5.I'm not sure if it's possible to do better. Just raising this issue to start a discussion.
A command line utility to import netcdf directly to gcs/zarr would be a very useful tool to have.