 pemami4911
commented
7 years ago
pemami4911
commented
7 years ago Hey, thanks for the comments. I am currently in the process of getting results for experiments on the Travelling Salesman Problem, and in the process I've been improving the code quite a bit. As soon as I get some reasonable results that are comparable to those from the paper, I'll make a more detailed write-up (probably a blog post!). This was quite difficult to implement from scratch lol.
To do that, you'd just have to write a script that loads the model from a checkpoint (I have this code written in trainer.py, see line 112) and then takes the input string of numbers and passes it to the model, basically following the code I wrote in trainer.py for evaluating the model from line 250 onwards. Line 285 is an example of how to get the final result out.
 unnir
unnir ricgama
ricgama


 yhyu13
yhyu13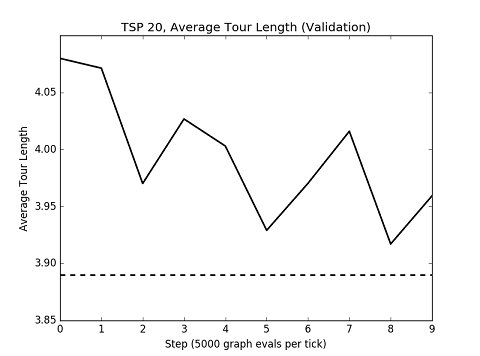
 quheng54
quheng54
Hi,
first thank you for your repo!
I just want to ask you, is there a source from where I can understand more about the architecture of your work, besides the mentioned paper? I mean, maybe you wrote a blog post about your algorithm or something like this.
Kind regards, Paddy
update:
Also, could you please tell how I can reuse the model which I've trained. I mean I finished the training and want to apply it for sorting a list, f.e.:
And the output would be a sorted list: