 penghuima
commented
3 years ago
penghuima
commented
3 years ago 这篇文章的主要贡献有两点
- 以云服务供应商的角度,对FaaS工作负载特征进行了描述,并提供了Azure Functions 数据集
- 提出一个混合直方图策略(Hybrid Histogram Policy)来为每个应用程序设置Pre-warming window 和Keep-alive window 窗口时间,通过这两个可配置的阈值在管理冷启动和资源成本之间取得了平衡。
FaaS Workloads Characterization
三个重要观察结论
- 绝大多数应用程序调用很不频繁,18%的应用程序负责所有调用的99.6%,18%的应用程序平均每分钟至多调用一次。因此如果按照传统策略,保持每个函数固定的keep-alive时间(eg,10分钟)云服务提供商需要付出昂贵的内存代价。
- 绝大多数函数的执行时间很短,只有几秒,其中75%的函数最长执行时间为10秒。而且函数执行时间与冷启动函数所需的时间在同一个量级(OOM,order of magnitude)。因此,减少冷启动次数或大幅提高冷启动速度至关重要。
- 许多应用程序的函数调用到达过程变化很大,对数据所有应用程序而言,有40%的应用程序的IAT(inter-arrival time) 的CV大于1,因此预测应用程序下一个调用很具有挑战性。
Functions, Applications, and Triggers
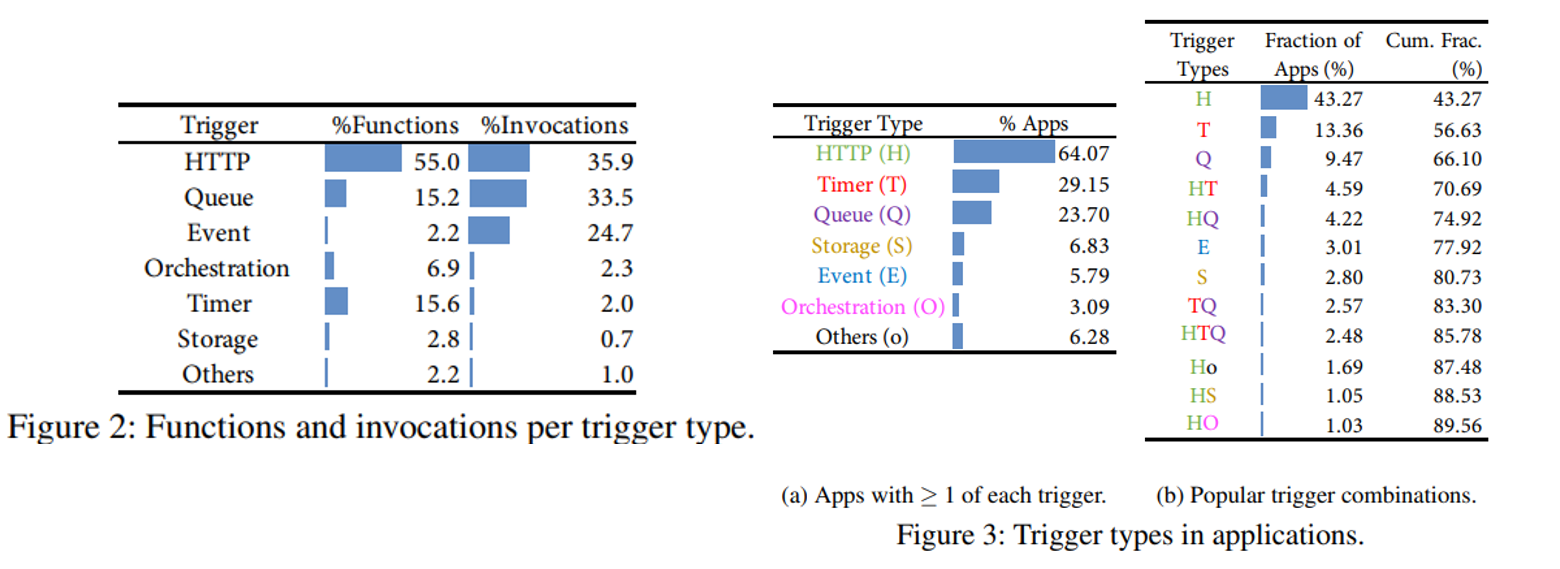 图2显示了每种触发器类型下所有函数以及所有调用的比例,图中可以看出在调用比例上 HTTP、Queue、Event这三类触发器总占比94%,在Azure Function中有35.9%的函数调用触发是HTTP类型。
图2显示了每种触发器类型下所有函数以及所有调用的比例,图中可以看出在调用比例上 HTTP、Queue、Event这三类触发器总占比94%,在Azure Function中有35.9%的函数调用触发是HTTP类型。
图3a显示了应用程序由许多不同类型的触发器组合而成,图3b根据触发器组合模式对应用程序进行了分区。
Invocation Patterns
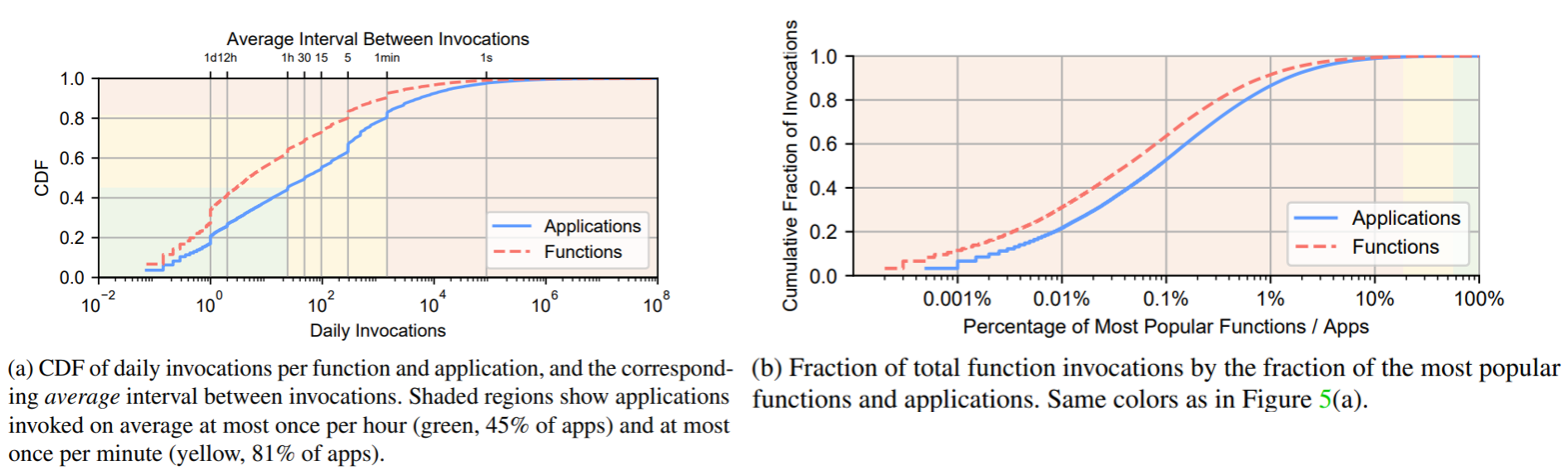
图 5a 展示了平均每天应用程序/函数调用次数的 CDF(应用程序的调用次数是其它自身所有函数调用总和),从横坐标可以看出不同 app/函数在调用次数上相差超过8 个数量级,而且绝大多数 app 和函数调用次数都很低,45%的应用程序每小时被调用一次或更少(对应于图5a中的绿色阴影部分),81% 的应用程序每分钟被调用一下或更少。这表明,相比于总执行计费时间,keep alive 的代价其实很高。
图 5b 则展示最受欢迎的函数/应用的累积调用比例,橙色阴影区域中的应用最受欢迎的,占比18.6%,平均每分钟至少被调用一次,但它们却占所有函数调用的99.6%。图5a和图5b的颜色具有相同的代表意义。
Inter-arrival time(IAT) variability
IAT:到达间隔时间,两次函数调用的到达间隔
用 CV 衡量该指标,CV 为标准偏差除以平均值。因此如果是一个定时任务,那么 CV = 0,如果人为产生的调用
符合泊松到达过程,则CV=1。
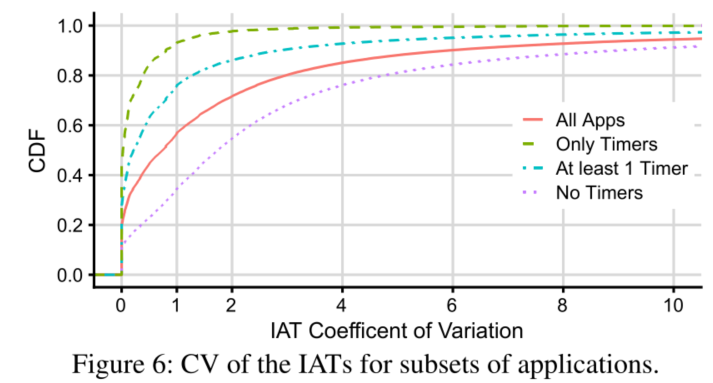
图6说明真实的 IAT 分布比简单的周期分布和指数分布(无记忆分布)要复杂得多。例如在仅有定时器触发器的应用程序中(绿色曲线),竟只有50%的CV=0,对于至少有一个定时器的应用,这个比例低于 30%,具有不同周期的多个定时器将增加 CV 值。而10% 没有定时器的应用程序的 CV 接近0,这意味着它们是相当周期性的,应该是可预测的。另一方面,只有一小部分应用的 CV 值接近于 1,这意味着简单的泊松到达不是常态。这些结果表明,有相当一部分应用程序应该具有相当可预测的 IAT,即使它们没有定时器触发器。同时,对于许多应用来说,预测 IAT 并不是一件小事。
Function Execution Times
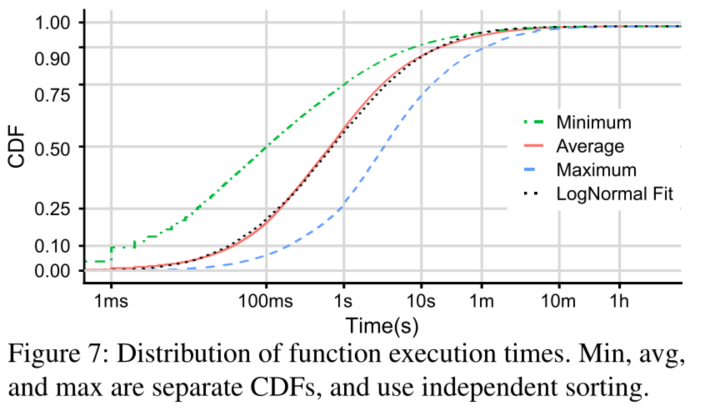
50% 的函数平均执行时间小于1s,50% 的函数最大执行时间短于 ∼3s;90% 的函数最多花 60s,96% 的函数平均花不到 60s。而且函数执行时间与冷启动函数所需的时间在同一个量级,因此减少冷启动次数或大幅提高冷启动速度至关重要。
Trade between cold starts and memory wasted
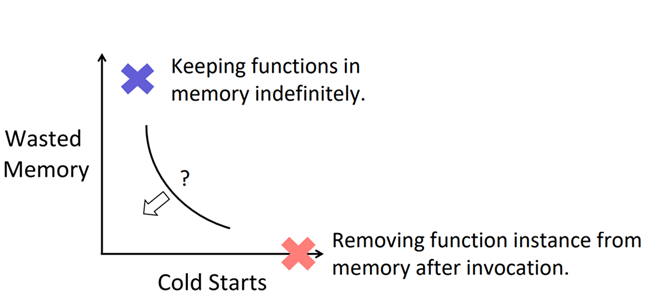
如果一直将函数镜像内容保存在内存中,这样无疑会避免冷启动问题,但付出的代价太昂贵,服务提供商是无法接受的,如果一旦函数执行完毕,就将函数卸载,移出内存,很显然又会出现冷启动问题,因此需要在冷启动和内存消耗之间作一个平衡。
已知云服务提供商的策略如下:
Amazon Lambda:Fixed 10-minute keep-alive
Azure Functions:Fixed 20-minute keep-alive
OpenWhisk:Fixed 10-minute keep-alive
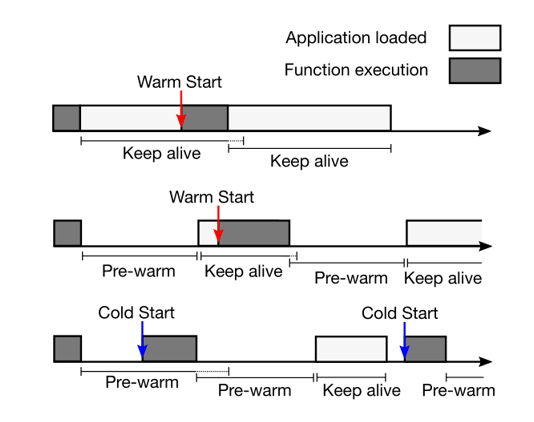
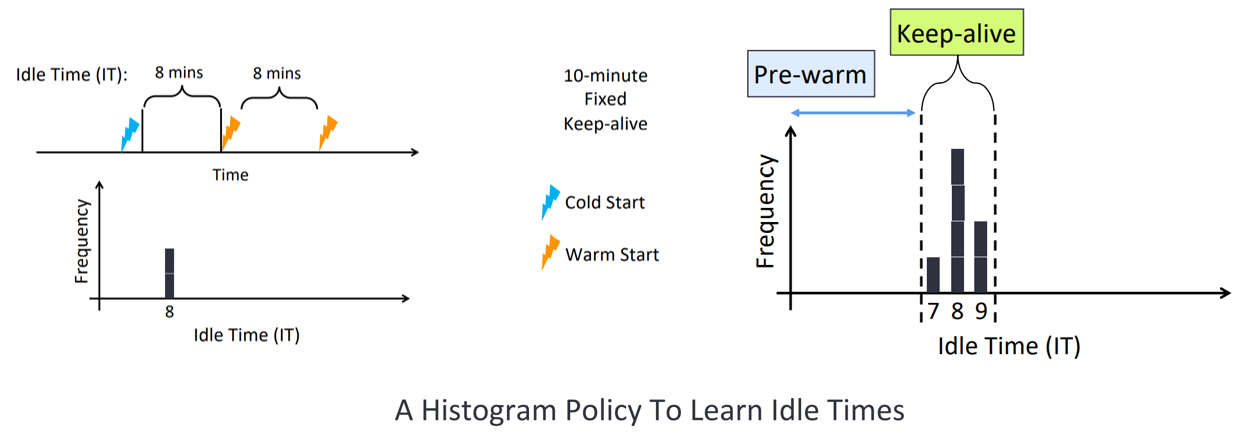
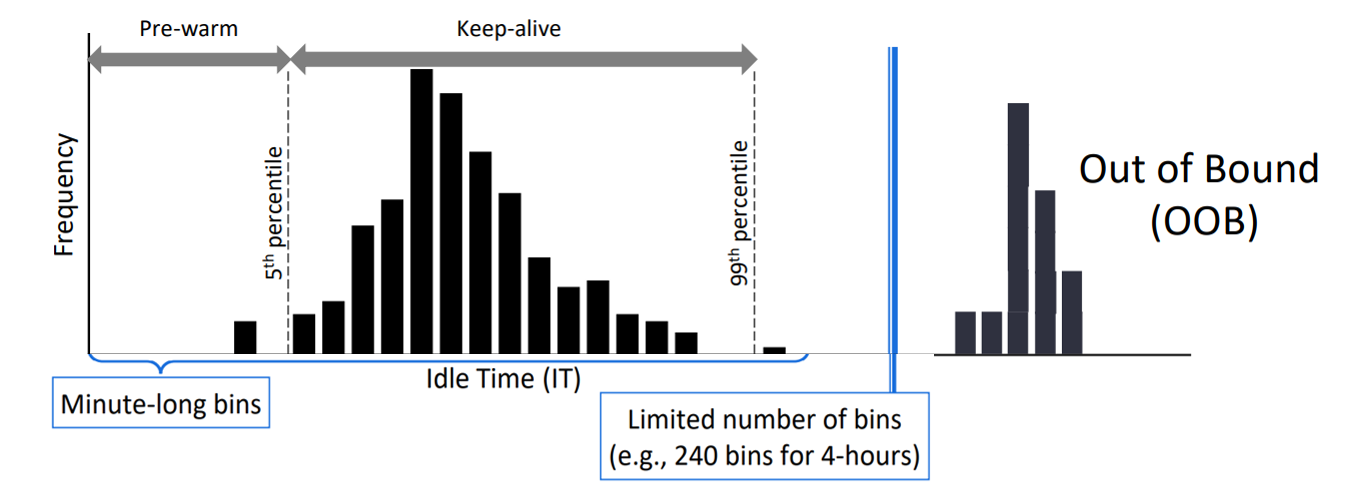
pdf、ppt、以及演讲视频 https://www.usenix.org/conference/atc20/presentation/shahrad