 xuziyue1998
commented
2 years ago
xuziyue1998
commented
2 years ago 另外,论文提到 we select two representative dimensions of similar to and plot the corresponding straight lines 此处的维度选择有什么特别的办法,还是随便取的? 谢谢!
Open xuziyue1998 opened 2 years ago
xuziyue1998
commented
2 years ago 另外,论文提到 we select two representative dimensions of similar to and plot the corresponding straight lines 此处的维度选择有什么特别的办法,还是随便取的? 谢谢!
xuziyue1998
commented
2 years ago 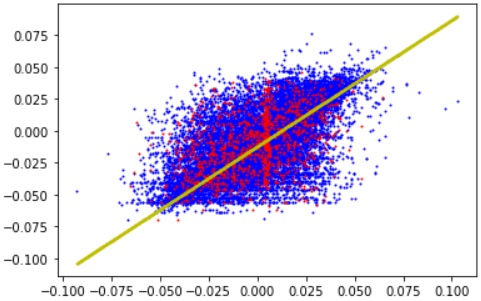
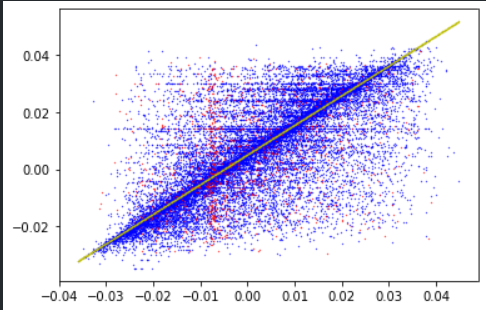
 pengyanhui
commented
2 years ago
pengyanhui
commented
2 years ago 代码我找不到了,由于代码比较简单,当时就直接在一台服务器上写了,跑完也没备份。 不过你这个是正常的。是由WN数据集的实体类型单一(只有一种)所致,实体数量庞大,每个实体涉及的关系很多,每个关系又涉及很多实体,优化时不同关系的直线之间会“抢夺”相关联的“点”,所以优化到完美是很难的。 但是直线的斜率和截距又比较符合预期,那“散乱的点”是如何优化出“良好的直线”呢? 其实,点看似非常散乱,实际上大部分点(我记得应该有90%左右)是分布在直线附近的,远离直线的点其实是非常少的,只是由于基数太大,这些少数的点画到图上也使图看起来散乱。你的第二张图中这种现象就比较明显,直线附近点比较密集。 为了把直线比较清晰地展现出来,我是选取了分布比较好的维度,并隐去了那些少数的散乱点。其实你也可以发现,涉及实体越多的关系,画出来的图越散,就是基数太大,以至于“少数”也成了“大量”。
xuziyue1998
commented
2 years ago 明白了,非常感谢!
可以公开一下论文中作图的代码吗?