piEsposito
commented
4 years ago
piEsposito
commented
4 years ago Hello Lukas, If you have a network with weight as the same shape as the variational layer you are using from blitz, you can, of course, set the blitz mu of the weights as that deterministic one, using built-in torch methods.
You can also train a frozen model and then unfreeze it (using the mu as something alike to weight priors). On that case, you may want to set your rho init parameter as small as you can, so you can reduce the variance of your model and calibrate it on the variational training.
 LukasWFurtner
LukasWFurtner
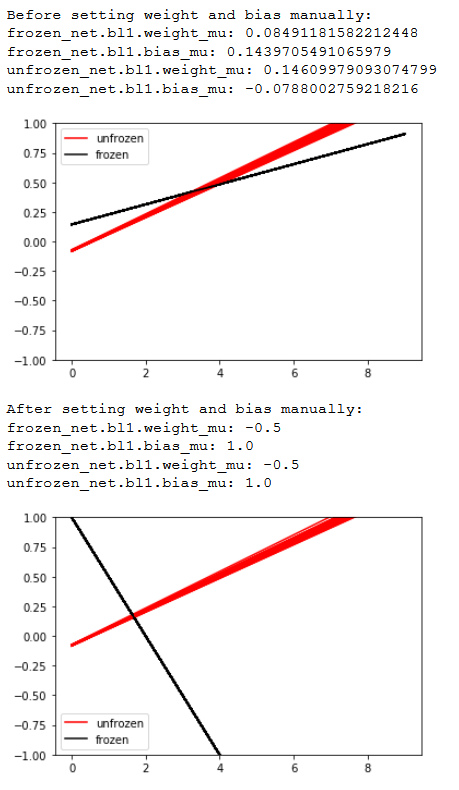{kind=link}
Hi, is there a possibility to initialize the mu´s of a net that is using blitz layers with the parameters of its deterministic equivalent? To get a better understanding I build a net with only one weight and one bias, thus the weight can be interpreted as the slope and the bias as the intercept of a linear function. However, setting the mu of the bias and weight seems to only work for a frozen model.