 arnaudroques
commented
6 years ago
arnaudroques
commented
6 years ago Hi, Well you are 100% right, it was definitely a bad decision. The only excuse we have is that it was a looong time ago and at that time the encoding used was not supposed to ever become public.
The bad news is that we cannot change this "legacy" encoding anymore because it's widely used by so many tools.
The good news is that we are currently thinking about extending the encoding by adding a single character header in front of the URL.
So here is our proposal about the new format:
If you intend to use Deflate compression:
1) Encoded in UTF-8 2) Compressed using Deflate algorithm 3) Reencoded in ASCII using Base 64 Encoding with URL and Filename Safe Alphabet ( https://tools.ietf.org/html/rfc3548 ) without padding character 4) Add an extra "0" header character
If you intend to use Brotli compression:
1) Encoded in UTF-8 2) Compressed using Brotli algorithm 3) Reencoded in ASCII using Base 64 Encoding with URL and Filename Safe Alphabet ( https://tools.ietf.org/html/rfc3548 ) without padding character 4) Add an extra "1" header character
This way, the decoder could safely decode "legacy" encoding (because "legacy" never starts by "0" or "1") and regular Base64 encoding using the initial character header. It also allows future extensions by using other character header.
Note that this is only a proposal and currently not implemented. It also slightly differs from what is explained on http://plantuml.com/text-encoding
What do you think about it ?
 kcolton
kcolton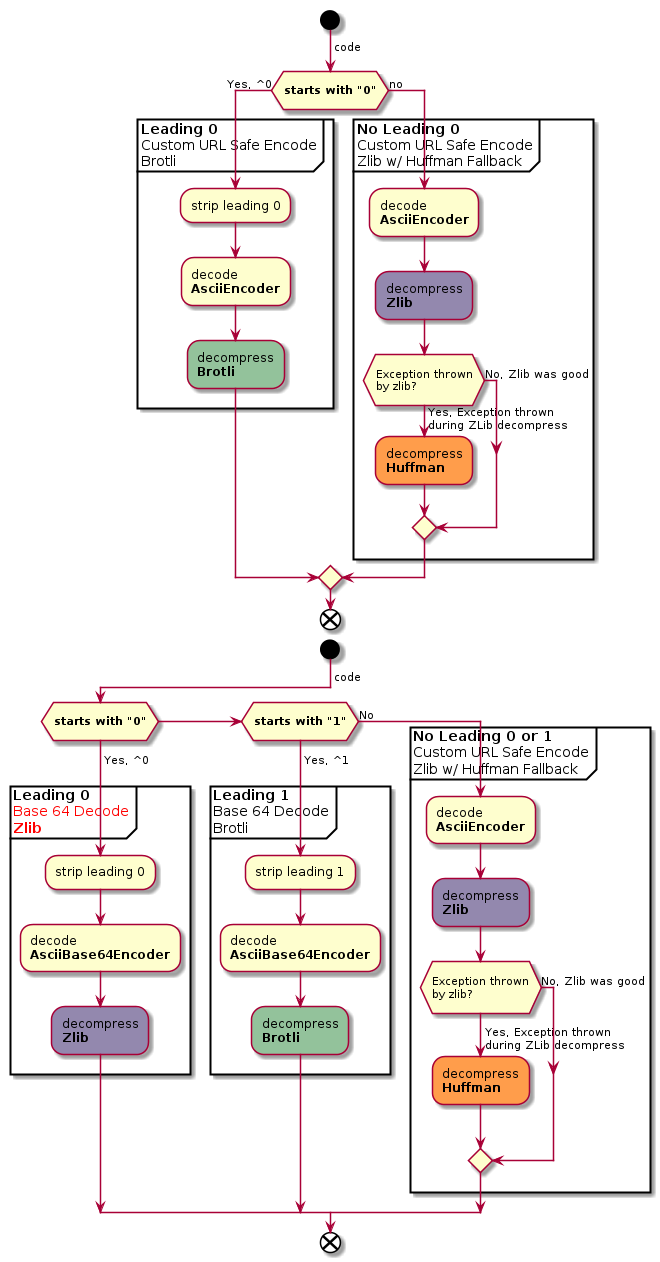
 trothwell
trothwell mpcjanssen
mpcjanssen ggrossetie
ggrossetie da-kami
da-kami
 maksugr
maksugr
Hi there,
I was wondering if there was a particular reason that
AsciiEncoderdoes not just use standard base 64 encoding. Are there important benefits over standard b64 encoding?The use case where this is problematic is in trying to create a new client (particularly one that is not Java) that constructs properly formed URLs to send to a PlantUML server.
Having to essentially copy, paste and translate the Java code (or the PHP or JS version available in the docs) into Python.
Isn't it just much easier to say the encoded format is:
That transformation can be implemented in almost every language using off the shelf components and not having to potentially re-implement encoding, add the entire jar, or make a subprocess call, just to generate the encoded string.