 JonathanWenger
commented
4 years ago
JonathanWenger
commented
4 years ago Having BlockDiagonal as a LinearOperator seems very convenient but is there a difference in efficiency or is this just an alias for the implemented Kronecker(A=Identity(num_copies), B=block)?
 pnkraemer
pnkraemer
 nathanaelbosch
nathanaelbosch I suppose that even if it is only "as" fast, the reduced storage may make this useful anyways. For e.g. EKF0, though, as long as the prior is of this form, the covariances are of this form (I think I am able to show this) in which case I expect the speedup to be significant. For EKF1 this will not always be the case as it depends on the form of the jacobian. .
I suppose that even if it is only "as" fast, the reduced storage may make this useful anyways. For e.g. EKF0, though, as long as the prior is of this form, the covariances are of this form (I think I am able to show this) in which case I expect the speedup to be significant. For EKF1 this will not always be the case as it depends on the form of the jacobian. .
We've known about this for a while now, I think it's time to at least make it an official feature-request. A solution is not urgent, though.
Matrices which are used in
ODEPriorare, more often than not, of the formnp.kron(mat1, mat2)usually evennp.kron(np.eye(dim), mat). This allocation eats too much storage and has a slow MVM.I propose to use a data structure such as for instance
BlockDiagonalwhich only storesmatanddimand implements fast matrix-vector products:For projection matrices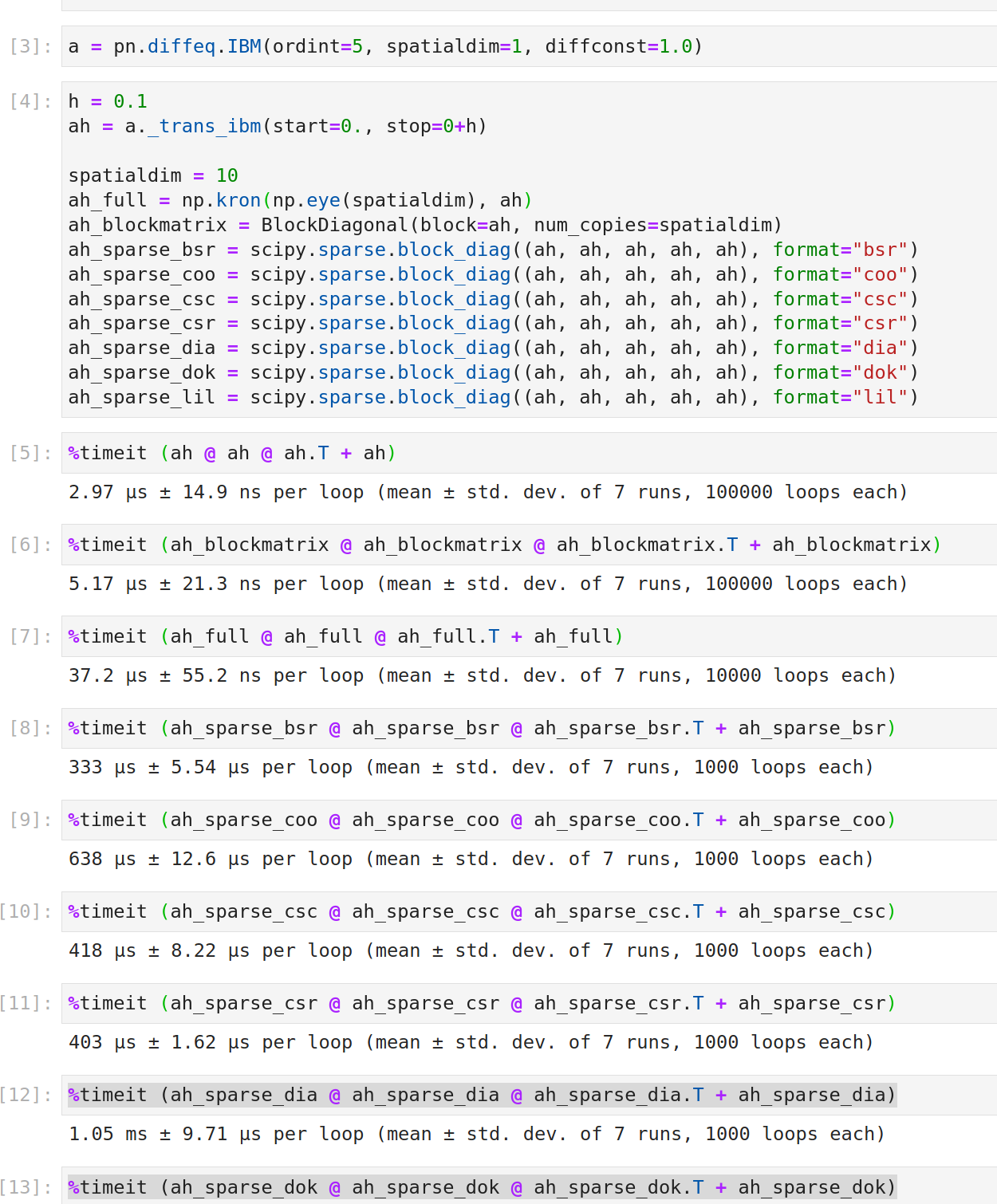
odeprior.proj2coord(), one could even go one step further and implement slicing into matmul (which I have not drafted yet). It would make the code equally readable (in my opinion; it would still useproj @ cov @ proj.T), the step to a more general kronecker productnp.kron(mat1, mat2)would remain a simple extension (using e.g. (A \otimes B)(C \otimes D)=(A \otimes C)(B \otimes D); almost all involved matrices have this kronecker structure)) and the memory footprint as well as the speed would improve significantly (see below)Affected files would be
prior.pyandivp2filter.pywhich would need to replace the respective outputs by the data structure. Occasionally,np.linalg.solve()andnp.linalg.cholesky()calls inivpfiltsmooth.pyandgaussfiltsmooth.pywould have to be replaced. It could be a smart choice to subclass fromlinops.LinearOperatorfor interface reasons.