 SpicyLemon
commented
1 month ago
SpicyLemon
commented
1 month ago Related to #1824
Closed SpicyLemon closed 3 weeks ago
SpicyLemon
commented
1 month ago Related to #1824
 iramiller
commented
1 month ago
iramiller
commented
1 month ago Based on input from @scirner22 we should set timeout_commit to 3500ms for pio-mainnet-1 as this value looks like it would conservatively pull the network into alignment around our desired 4s block time. There are still outliers that are causing additional consensus rounds which is what is really pulling our block times up currently however the hope is with further standardization we will see more uniform performance. We are likely to want to further adjust this value in future software upgrades based on network performance.
SpicyLemon
commented
1 month ago I feel like there's more to this than just the timeout_commit field.
All of this is from v1.19.1.
Disclaimer: I thought about removing the values from the stuff in this comment, because I don't want them to be viewed as suggestions or taken to be at all correct or accurate. I only left them here to show what type of field each is. I don't know where I got them and I don't actually run any nodes using these config values.
Here's the consensus section from the config file:
#######################################################
### Consensus Configuration Options ###
#######################################################
[consensus]
wal_file = "data/cs.wal/wal"
# How long we wait for a proposal block before prevoting nil
timeout_propose = "3s"
# How much timeout_propose increases with each round
timeout_propose_delta = "500ms"
# How long we wait after receiving +2/3 prevotes for “anything” (ie. not a single block or nil)
timeout_prevote = "1s"
# How much the timeout_prevote increases with each round
timeout_prevote_delta = "500ms"
# How long we wait after receiving +2/3 precommits for “anything” (ie. not a single block or nil)
timeout_precommit = "1s"
# How much the timeout_precommit increases with each round
timeout_precommit_delta = "500ms"
# How long we wait after committing a block, before starting on the new
# height (this gives us a chance to receive some more precommits, even
# though we already have +2/3).
timeout_commit = "4.3s"
# How many blocks to look back to check existence of the node's consensus votes before joining consensus
# When non-zero, the node will panic upon restart
# if the same consensus key was used to sign {double_sign_check_height} last blocks.
# So, validators should stop the state machine, wait for some blocks, and then restart the state machine to avoid panic.
double_sign_check_height = 0
# Make progress as soon as we have all the precommits (as if TimeoutCommit = 0)
skip_timeout_commit = false
# EmptyBlocks mode and possible interval between empty blocks
create_empty_blocks = true
create_empty_blocks_interval = "0s"
# Reactor sleep duration parameters
peer_gossip_sleep_duration = "100ms"
peer_query_maj23_sleep_duration = "2s"Here they are again in a more concise list (output of provenanced config get consensus).
consensus.create_empty_blocks=true
consensus.create_empty_blocks_interval="0s"
consensus.double_sign_check_height=0
consensus.peer_gossip_sleep_duration="100ms"
consensus.peer_query_maj23_sleep_duration="2s"
consensus.skip_timeout_commit=false
consensus.timeout_commit="4.3s"
consensus.timeout_precommit="1s"
consensus.timeout_precommit_delta="500ms"
consensus.timeout_prevote="1s"
consensus.timeout_prevote_delta="500ms"
consensus.timeout_propose="3s"
consensus.timeout_propose_delta="500ms"
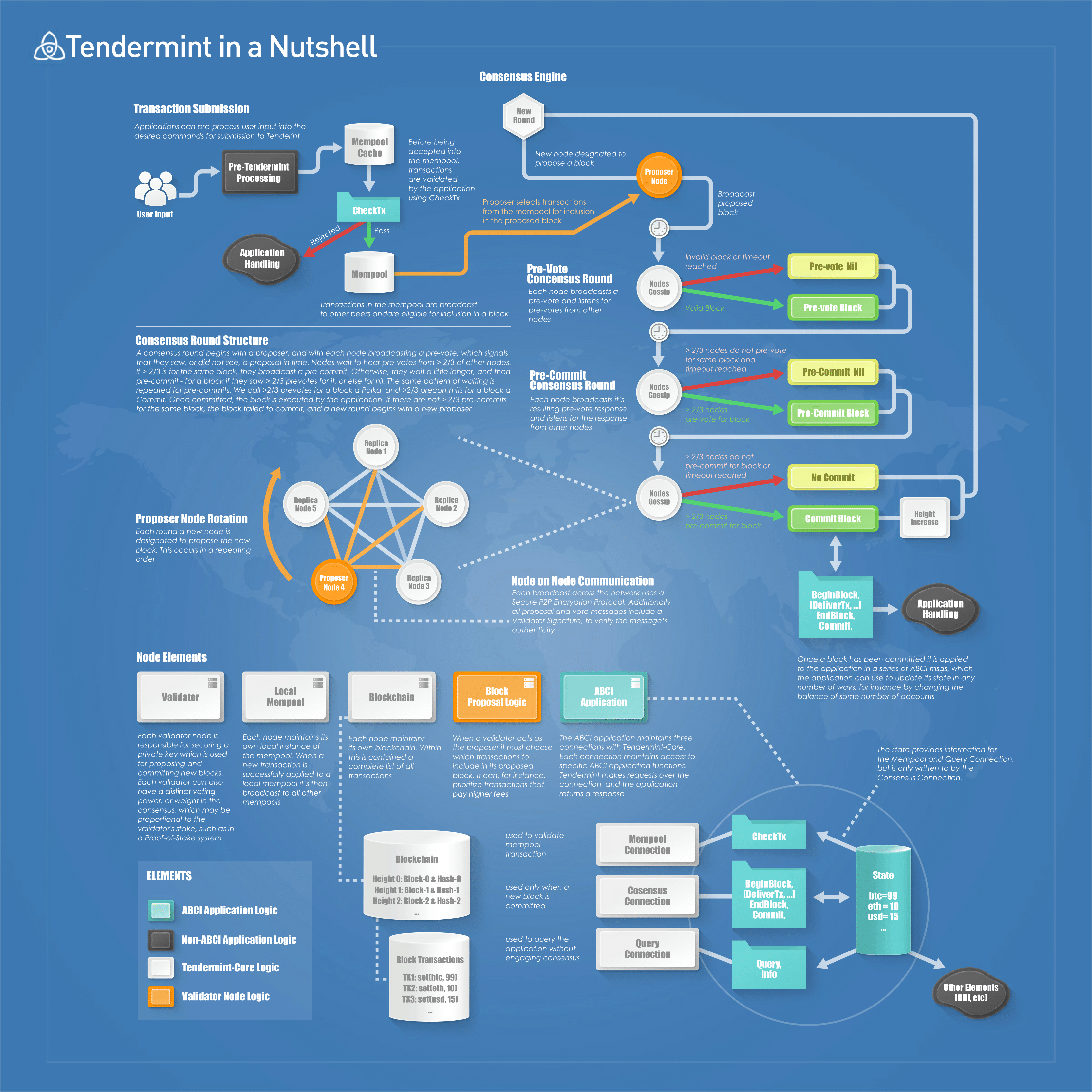
consensus.wal_file="data/cs.wal/wal"I found a nice graphic of the block lifecycle. It doesn't mention the timeout config stuff, but it shouldn't be too hard to see where each applies.
Source: https://docs.ipc.space/specifications/cometbft -> https://docs.tendermint.com/v0.34/assets/img/tm-transaction-flow.258ca020.png
iramiller
commented
1 month ago sure ... we can force set all the consensus configuration parameters if we want to ... I am not sure why they ever allowed nodes to modify these settings on their own to begin with vs setting them in the genesis/protocol config.
For reference these are the defaults for Osmosis (since I had them at hand)
timeout_propose = "3s"
timeout_propose_delta = "500ms"
timeout_prevote = "1s"
timeout_prevote_delta = "500ms"
timeout_precommit = "1s"
timeout_precommit_delta = "500ms"
timeout_commit = "5s"
double_sign_check_height = 0
skip_timeout_commit = false
create_empty_blocks = true
create_empty_blocks_interval = "0s"
peer_gossip_sleep_duration = "100ms"
peer_query_maj23_sleep_duration = "2s"Of note the only one that is different here from what you have above is the timeout_commit which we are proposing to standardize above. This is a value we have messed with over time so it is the most likely to be varied across our network.
SpicyLemon
commented
1 month ago Looking at that chart, I wonder if we should look at increasing timeout_propose.
If we had stats on what's actually causing the extra rounds, we could better react here.
timeout_propose so nodes have a better chance of receiving the proposed block.timeout_prevote. That's the amount of time to wait AFTER getting +2/3 of the pre-votes (nil or not), before giving up on pre-votes and moving on with what it's got.timeout_precommit. That's the amount of time to wait AFTER getting +2/3 of the pre-commits (nil or not), before giving up on pre-commits and the proposed block.In that graphic, I'm not entirely sure what timeout_commit governs, though. The timeout_commit comment states:
How long we wait after committing a block, before starting on the new height (this gives us a chance to receive some more precommits, even though we already have +2/3).
That makes it sound like timeout_commit is the minimum amount of time from the commitment of one block to the commitment of the next block. I.e. the entire loop, not counting the amount of time it takes to actually commit all the data, and possibly covering multiple trips around the loop when more than one round is needed for a block. But "before starting on the new height" could mean many things; it specifically states it can help gather extra pre-commits, so it more than likely covers that part of the loop. And it's also possible that "after committing a block" isn't 100% technically accurate. I.e. maybe it actually starts at the start of a round or at some other point in the loop that isn't mentioned on that graphic.
Here's my take on how the round lifecycle happens:
timeout_propose and start waiting for pre-votes and the proposed next block.timeout_prevote.timeout_precommit.timeout_commit. This will carry over into the next round(s).That's my interpretation of the process based on that graphic and the config file comments and could easily be all sorts of wrong. For example, maybe step 13 also involves waiting for the commit timer to expire. Or maybe the commit timer starts with step 1. There's lots of ways I can be wrong.
iramiller
commented
1 month ago It seems likely that the proposers are not getting votes to meet the majority (i.e. it is being rejected) and the previous proposer runs again. We are seeing round 2 in the failure cases. Dashboard showing rounds here
SpicyLemon
commented
1 month ago Here's another lifecycle diagram that might be useful, but again, I'm not sure how timeout_commit factors into it.
Source: https://docs.tendermint.com/v0.34/introduction/what-is-tendermint.html#consensus-overview
SpicyLemon
commented
1 month ago It seems likely that the proposers are not getting votes to meet the majority (i.e. it is being rejected) and the previous proposer runs again. We are seeing round 2 in the failure cases. Dashboard showing rounds here
The docs make it sound like it's supposed to pick a different proposer for each round, but maybe that's not always the case.
From what I can tell, the timeout_commit is a minimum amount of time between blocks, but the other timeout config fields are maximum waiting times. I.e. the timer from timeout_commit is always run down to zero, but the timers for the others might be cancelled early if certain conditions are met.
I'm sure that standardizing timeout_commit on all the nodes will help. As you pointed out, we've changed our recommendation on it many times (and the default is 1s). If a node has a low value here, it might commit the proposed block and start a new round well before other nodes. So it could be waiting for the next block proposal for a second or two before the proposer even starts putting together the next proposal. That'd make it more likely to not get the proposal in time and broadcast a nil pre-vote and cause that round to fail.
While writing this, I was considering a timeout_commit of 1s (or less), but that scares me a bit. The last time I fired up a node and had it catch up, it seemed like I was hitting a rate limiter somewhere. I don't know if it's something baked into the SDK's catch-up stuff, or if it's something with how the servers are configured (that are running the nodes). Basically, it'd get a chunk of blocks, then wait a bit, and get a chunk more. But it wasn't averaging much more than a block a second. We need to make sure that we can always replay blocks to catch up faster than we're creating new blocks.
SpicyLemon
commented
1 month ago I'll start putting together the PR to basically hard-code the timeout_commit.
I was thinking it'd be really cool if we could store this stuff in state (updatable through gov prop), but in order to get to the point where we'd be able to read them from state, we would have already created a bunch of the stuff that uses the config values, and I highly doubt there's a way to inform all that stuff of changes to their config.
iramiller
commented
1 month ago Pretty sure I saw something coming in SDK52 or similar that is moving this stuff into consensus params on chain… so a temporary forced config might make sense here.
{kind=link}
Summary
There's several
consensustiming fields in the config file (inconfig.toml) that we'd like to standardize across nodes.Problem Definition
We see a lot of sporadic block times and it's possibly related to various
consensus.settings which each node can define for itself.Proposal
There's a couple things we can do depending on how much effort we want to put in.
For Admin Use