 sigmavirus24
commented
6 years ago
sigmavirus24
commented
6 years ago Please provide us with the output of
python -m requests.helpIf that is unavailable on your version of Requests please provide some basic information about your system (Python version, operating system, etc).
 Munroc
Munroc nateprewitt
nateprewitt initbar
initbar leoszn
leoszn Badiboy
Badiboy jotunskij
jotunskij pawel-lmcb
pawel-lmcb BarryThrill
BarryThrill popjxc
popjxc tallona
tallona PedanticHacker
PedanticHacker MuhammadAliShahzad
MuhammadAliShahzad far-rainbow
far-rainbow ghost
ghost guyskk
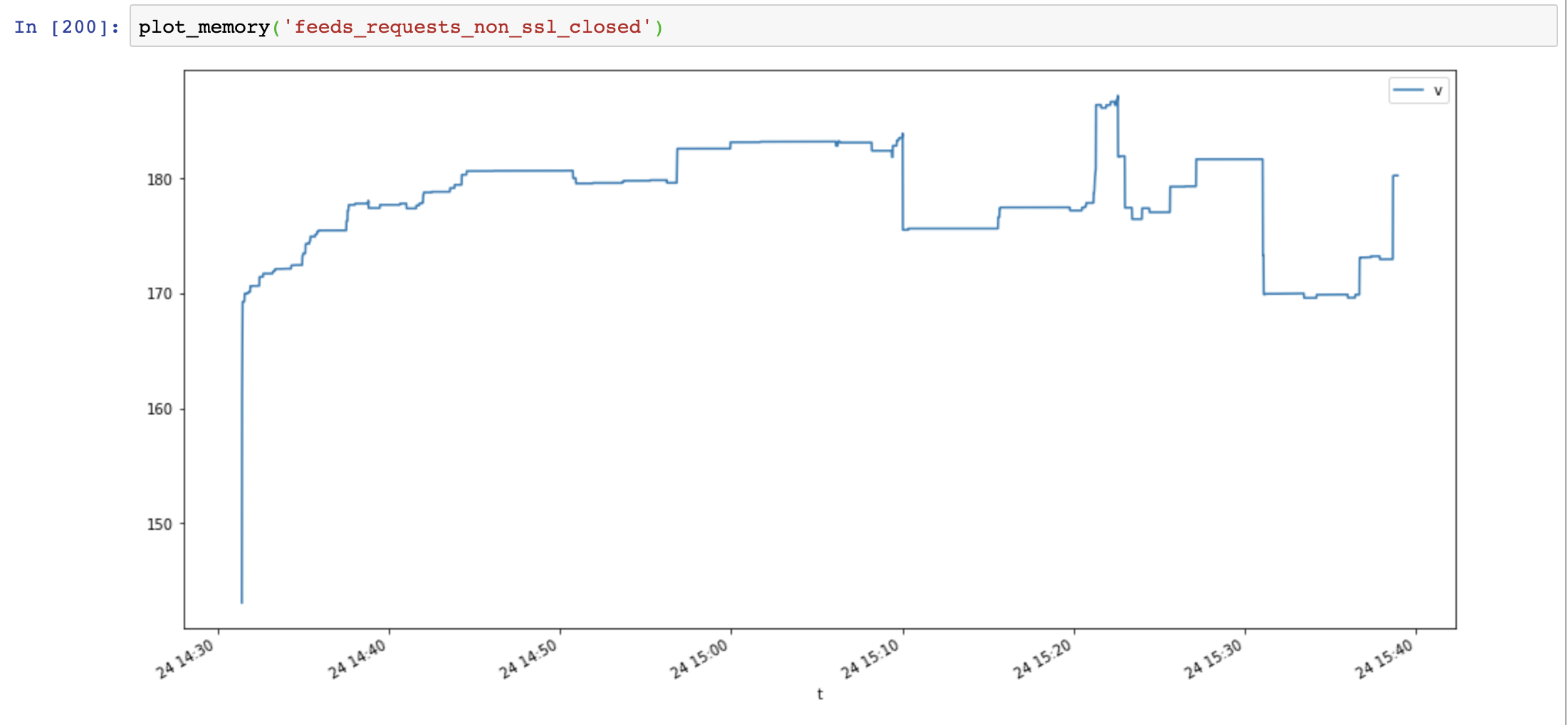
guyskk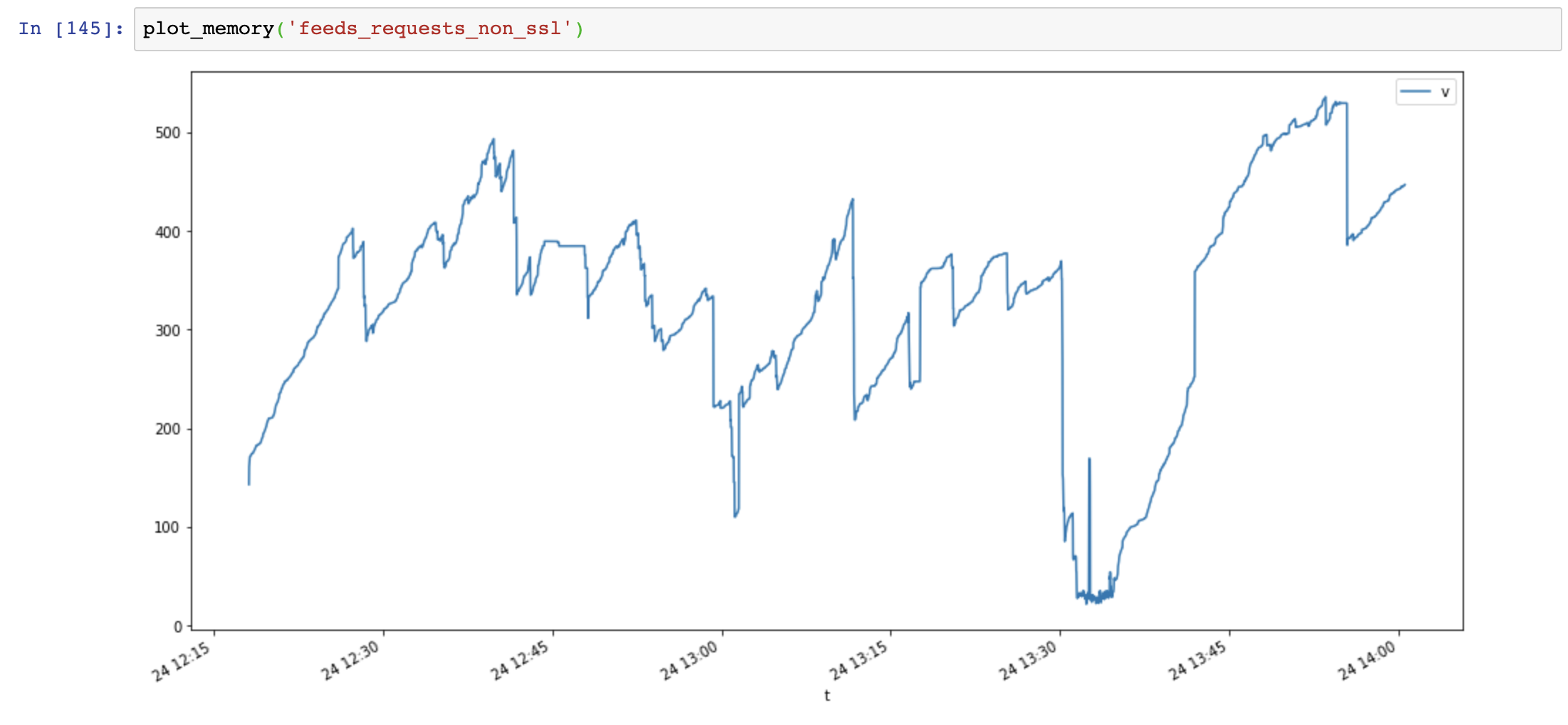






 VeNoMouS
VeNoMouS andre487
andre487 constantind
constantind teodoryantcheff
teodoryantcheff
Summary.
Expected Result
Program running normally
Actual Result
Program consuming all ram till stops working
Reproduction Steps
Pseudocode:
System Information