 ZeroIntensity
commented
1 month ago
ZeroIntensity
commented
1 month ago Generally, performance changes like this add too much complexity to the code to be desirable -- there's also nothing stopping you from just using your implementation on your own. With that being said, maybe this is a good idea, but I think this needs to be discussed on DPO.
cc @Eclips4, as you're now an AST expert :)
 picnixz
picnixz Stanley5249
Stanley5249 JelleZijlstra
JelleZijlstra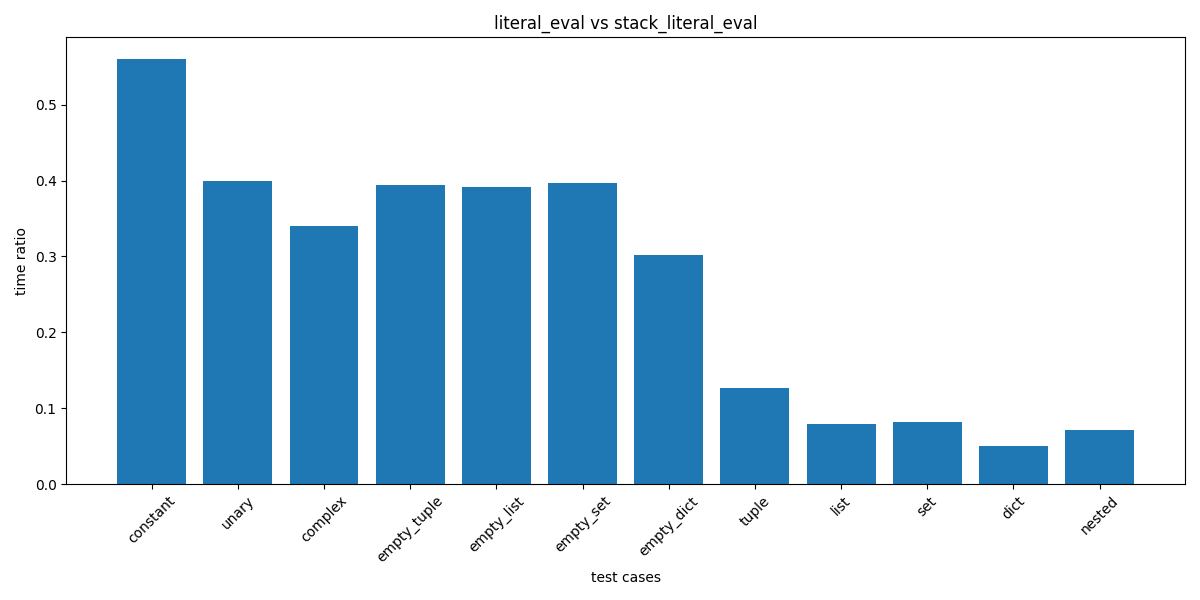
Feature or enhancement
Proposal
I have implemented a stack-based version of
ast.literal_evaland conducted benchmarks to compare its performance with the existing implementation. The results indicate that the stack-based version may improve performance on non-nested expressions, although it is slightly slower on nested expressions.Benchmark Results
The benchmarks were conducted on an Intel(R) Core(TM) Ultra 9 185H. Below are the results comparing
ast.literal_evalandstack_literal_eval:Question
I wonder if this change is desirable?
Code
See here.
Related Issue
This work is related to the closed issue #75934.
Has this already been discussed elsewhere?
This is a minor feature, which does not need previous discussion elsewhere
Links to previous discussion of this feature:
No response