 yourh
commented
4 years ago
yourh
commented
4 years ago Any one help?
Open yourh opened 5 years ago
yourh
commented
4 years ago Any one help?
 fmassa
commented
4 years ago
fmassa
commented
4 years ago Can you provide a minimal script reproducing the issue? Without further information it is very hard for us to try spotting where the problem might be.
yourh
commented
4 years ago @fmassa Here is a minimal script, thanks a lot.
import torch
import torch.nn as nn
from torch.nn.parallel.data_parallel import _get_device_index, replicate
class DataReplicate(nn.Module):
def __init__(self, module):
super(DataReplicate, self).__init__()
device_ids = list(range(torch.cuda.device_count()))
self.module = module
self.device_ids = list(map(lambda x: _get_device_index(x, True), device_ids))
def forward(self, inputs):
replicate(self.module, self.device_ids)
return inputs
class Network(nn.Module):
def __init__(self, k):
super(Network, self).__init__()
self.layer = nn.Linear(k, k)
def forward(self, inputs):
return inputs
if __name__ == '__main__':
dr = DataReplicate(Network(10000).cuda())
for _ in range(1000):
dr(torch.zeros(10)) pietern
commented
4 years ago
pietern
commented
4 years ago I compared 1.0.1 to my development version and get the following:
I modified the repro script with the following to take a proper measurement:
diff --git a/repro.py b/repro.py
index 4bd3d9c..3ae7195 100644
--- a/repro.py
+++ b/repro.py
@@ -1,3 +1,4 @@
+import time
import torch
import torch.nn as nn
from torch.nn.parallel.data_parallel import _get_device_index, replicate
@@ -26,5 +27,10 @@ class Network(nn.Module):
if __name__ == '__main__':
dr = DataReplicate(Network(10000).cuda())
+ torch.cuda.synchronize()
+ start = time.time()
for _ in range(1000):
dr(torch.zeros(10))
+ torch.cuda.synchronize()
+ stop = time.time()
+ print("Took: %.6f" % (stop - start))@yourh Can you update your repro script and confirm the measurements on your machine?
yourh
commented
4 years ago @pietern Thank you very much. I update the script and run it on my 8 GPUs machine and get the following:
I also run it on another 4 GPUs machine and get the following:
pietern
commented
4 years ago At 10000x10000 floats we're talking about 400MB of data that you're replicating 1000 times, for a total of 400GB of data being copied from GPU 0 to the other GPUs. On my machine, I have 2 GPUs that are connected with 4x bonded NVLinks for a theoretical peak bandwidth of 64GB/sec (unidirectional, see https://en.wikipedia.org/wiki/NVLink):
$ nvidia-smi topo -m
GPU0 GPU1 mlx5_0 CPU Affinity
GPU0 X NV4 SYS 20-39,60-79
GPU1 NV4 X SYS 20-39,60-79
mlx5_0 SYS SYS XThe 7.18s number I posted earlier amounts to ~55GB/sec, which is close enough to make sense.
Can you post back the topology you're using?
The screenshot you included in the earlier post shows you're using 8x GTX 1080 Ti cards, which are presumably connected over PCIe. The max bandwidth between cards is about 14 GB/sec. You can do the math and see that the numbers you post for 1.0.1 are close to peak.
I suspect that the reason for the crappy numbers on 1.3 is related to some sort of regression in NCCL, which is used to implement the replicate function (it performs a local broadcast of the parameters of the primary module). In PyTorch 1.0.1 we used NCCL 2.3.7 and in PyTorch 1.3 we used NCCL 2.4.8.
@sjeaugey @addyladdy Does this type of regression ring any bells? I don't see the regression on a machine with NVLink and the regression is clear on a machine with PCIe.
yourh
commented
4 years ago @pietern The topology is as following:
$nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity
GPU0 X PIX PHB PHB SYS SYS SYS SYS 0-11,24-35
GPU1 PIX X PHB PHB SYS SYS SYS SYS 0-11,24-35
GPU2 PHB PHB X PIX SYS SYS SYS SYS 0-11,24-35
GPU3 PHB PHB PIX X SYS SYS SYS SYS 0-11,24-35
GPU4 SYS SYS SYS SYS X PIX PHB PHB 12-23,36-47
GPU5 SYS SYS SYS SYS PIX X PHB PHB 12-23,36-47
GPU6 SYS SYS SYS SYS PHB PHB X PIX 12-23,36-47
GPU7 SYS SYS SYS SYS PHB PHB PIX X 12-23,36-47
https://github.com/pytorch/pytorch/issues/28212#issue-508340762
I run nn.DataParallel with only replicate operation and found that is much slower in v1.3. For v1.0, the GPU util is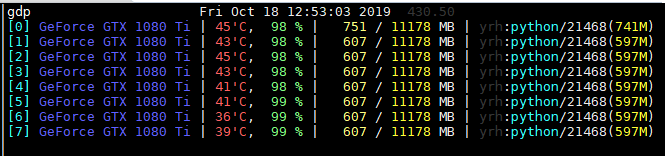
and for v1.3 is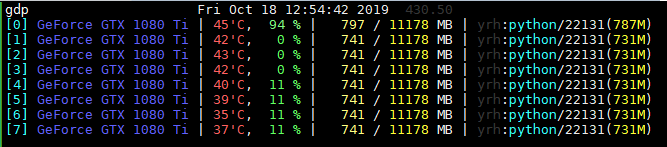
cc @VitalyFedyunin @ngimel @mruberry