 snakers4
commented
4 years ago
snakers4
commented
4 years ago TLDR - I just used plain vanilla transformer layer in my model as a decoder, to avoid extra fiddling with BERT code and tried your brand new quantization tutorial
Hope this helps and you can replicate my error!
 mrshenli
mrshenli suryapa1
suryapa1 zhangguanheng66
zhangguanheng66 juliocspires
juliocspires vkuzo
vkuzo hetpandya
hetpandya z-a-f
z-a-f andrewor14
andrewor14
🐛 Bug
https://github.com/pytorch/pytorch/issues/32590#issuecomment-579261982
TLDR
To Reproduce
Steps to reproduce the behavior:
I just use the same invokation as in the tutorial Should work, because your transformer and huggingface should consist of Linear layers mostly!
Expected behavior
The model loses "weight" (this happens)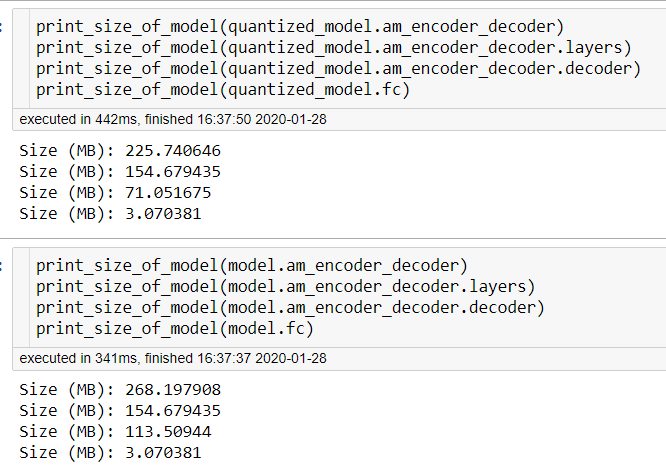
You are able to run it
Environment
conda,pip, source): I use this imagedocker pull pytorch/pytorch:1.4-cuda10.1-cudnn7-develcuda10.1-cudnn7-develnn.transformersAdditional context
When I run the model, I get this bug (I run on CPU)
Also, this may be relevant - my
forwardlook like thisThe problem seems to be with this function
Do I understand correctly, that it should go away if this function is replaced by nn.module version? Or is there any other way to apply a quick monkey path until 1.5 is released?
cc @jerryzh168 @jianyuh @dzhulgakov @raghuramank100 @jamesr66a