 banesullivan
commented
4 years ago
banesullivan
commented
4 years ago PyVista (and VTK to my knowledge) can only render textures by point-based UV coordinates. So, you need that vt array to map back to the v vertices 1-to-1. Without knowing which vertices are repeated and the order of vt with respect to those, I can't think of a way to do this beside interpolating.
Also, can you share a pv.Report()? meshio very much complains about the mesh you shared for me.... so I wrote my own custom parser to demonstrate.
Here is a way to do this by interpolating the cell texture coordinates to the vertices:
import pyvista as pv
import numpy as np
import pandas as pd
shirts_path = './models/shirts_simple.obj'
img_file = './models/up_dog.jpg'
tex = pv.read_texture(img_file)
#### Manually parse the OBJ file because meshio complains
raw_data = pd.read_csv(shirts_path, header=None, comment="#",
delim_whitespace=True, names=["type", "a", "b", "c"])
groups = raw_data.groupby("type")
v = groups.get_group("v")
f = groups.get_group("f")
vt = groups.get_group("vt")[["a", "b"]].values.astype(float)
vertices = v[["a", "b", "c"]].astype(float).values
fa = np.array([(int(x[0]), int(x[1]), int(x[2])) for x in f["a"].str.split("/")])
fb = np.array([(int(x[0]), int(x[1]), int(x[2])) for x in f["b"].str.split("/")])
fc = np.array([(int(x[0]), int(x[1]), int(x[2])) for x in f["c"].str.split("/")])
faces = np.c_[fa[:,0], fb[:,0], fc[:,0]] - 1 # subtract 1
#### End manual parsing
# Create the mesh
cells = np.c_[np.full(len(faces), 3), faces]
mesh = pv.PolyData(vertices, cells)
# Generate the tcoords on the faces
ctcoords = np.c_[fa[:,1], fb[:,1], fc[:,1]] - 1 # subtract 1
ui, vi = ctcoords[:,0], ctcoords[:,1]
cuv = np.c_[vt[:,0][ui], vt[:,1][vi]]
mesh.cell_arrays["Texture Coordinates"] = cuv
# Interpolate the cell-based tcoords to the points
remesh = mesh.cell_data_to_point_data()
# Register the array as texture coords
remesh.t_coords = remesh.point_arrays["Texture Coordinates"]
# Plot it up, yo!
remesh.plot(texture=tex, notebook=0)And the texture renders on the mesh:

However, since the texture coordinates were interpolated, I suspect this is causing some distortion of the texture along the seam:


 wangfudong
wangfudong


 sharoseali
sharoseali
Description
Dear Pyvista-Team,
Thank you for your amazing contributions ! I have found a problem of applying textures with multi 2D uv maps:
I have an obj file in a standard Wavefront .obj format, looks like this:
mtllib upper.mtl v 0.087744 0.280746 0.026054 v 0.096368 0.290851 0.008842 v 0.092829 0.298936 0.000274 v 0.088663 0.290136 0.014576 v 0.088268 0.255024 0.054397 ...... vt 0.298072 0.661321 vt 0.300275 0.666815 vt 0.297550 0.665329 vt 0.295570 0.664305 vt 0.295251 0.660191 ...... g upper usemtl UPPER f 2039/1/2039 2/2/2 2042/3/2042 f 2042/3/2042 4/4/4 2041/5/2041 f 2041/5/2041 1/6/1 2039/1/2039 f 2039/1/2039 2042/3/2042 2041/5/2041 f 2042/3/2042 2/2/2 2040/7/2040 ......
It has 8168 verts and 16116 faces. Since the uv map of this 3D object (in fact, it is a shirt) is divided into two parts, front and back, each vert lying on the seam between the front and back will have 2 corresponding uv parameters in the uv map; thus, it has 8399 uv parameters ( i.e., the field 'vt' is 8399x2), which is more than 8168. The shirts and its uv maps look like this, opened with blender 2.83,
In the .mtl file, I have attached an texture image,
And then, I can open the whole obj file with texture image by some 3D tools, like CloudCompare,
However, I can not use Pyvista to visualize it. I used python3.6 and Pyvista 0.25.3.
The output looks strange,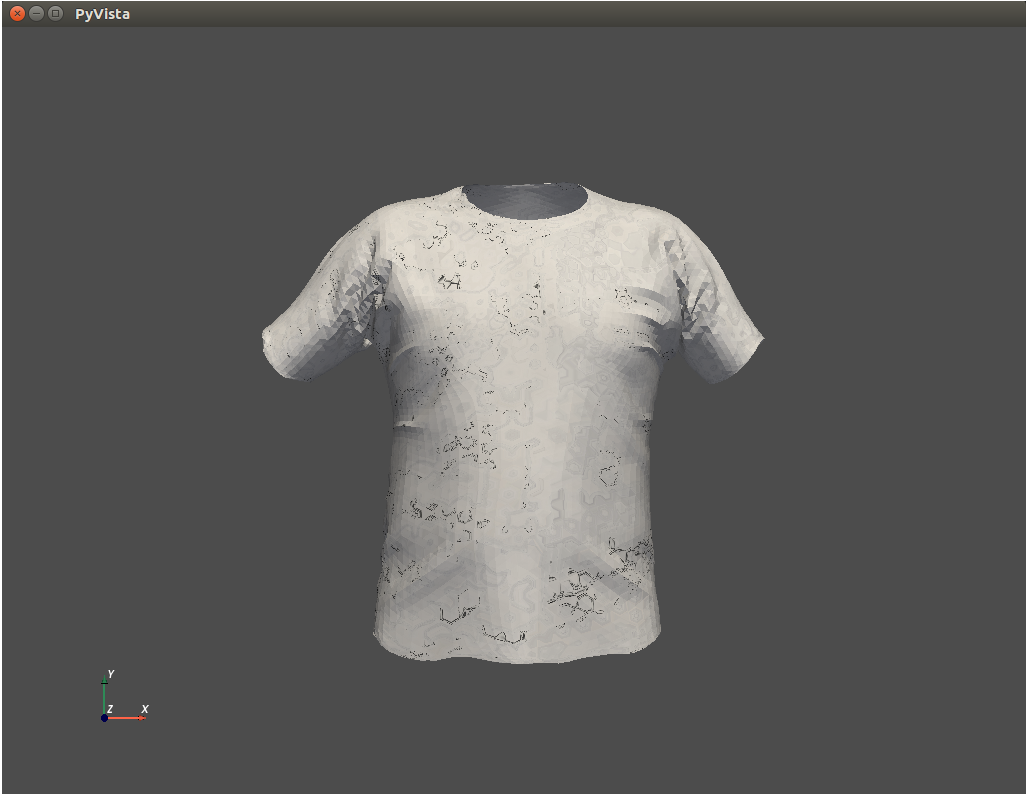
I guess there are two reasons resulting in this bad case, 1) the fields 'v' and 'vt' are not one-to-one corresponding, 2) the vert_ids and vt_ids are differently ordered in the filed 'f', for example, "f 2039/1/2039 2/2/2 2042/3/2042" means that the triangle face has vertex ids (2039, 2, 2042), while the vt ids are (1, 2, 3). When I use mesh=pyvista.read_meshio() to load the obj file, the mesh.cells only contains vert_ids, like (2039, 2, 2042), and the visulizer use these ids to render the texture image onto the obj model, rather than use the vt ids, like (1, 2, 3).
Example Data
I have uploaded the .obj/.mtl files and texture image in the models.zip folder. models.zip