 hadley
commented
6 years ago
hadley
commented
6 years ago I wonder if we could include a standard docsearch .json in the built site?
Closed jayhesselberth closed 6 years ago
hadley
commented
6 years ago I wonder if we could include a standard docsearch .json in the built site?
 s-pace
commented
6 years ago
s-pace
commented
6 years ago 👋 @jayhesselberth @hadley
For such, would be glad to help your tool!
We could even fine tune it a bit in order to create the best pattern from a config POV (e.g. remove see-also external links, licences ...).
 jayhesselberth
commented
6 years ago
jayhesselberth
commented
6 years ago I'll put something together to build a suggested docsearch JSON.
s-pace
commented
6 years ago Nice @jayhesselberth,
Could you also try to:
.docSearch) or wrap the interference content in a specific class (e.g. notDocContent) like see also or table of content?Thanks
 batpigandme
commented
6 years ago
batpigandme
commented
6 years ago 🎉 Oh, awesome! @s-pace, @jayhesselberth I think you just made it infinitely easier for me to adapt this to bookdown. So, here, an emoji of a trophy: 🏆. I know, it's very prestigious, and you'll probably hang it on your walls.
jayhesselberth
commented
6 years ago @s-pace Can you provide some insight into the relationship between the lvl0, lvl1, text selectors and how search results are displayed? I couldn't find in the docs where this is explicitly spelled out.
For example, consider the search on http://pkgdown.r-lib.org. If you search for "build", you get 5 entries back. But the information per entry is redundant. I.e. Each search result is the same information displayed 3 different ways (Build articles, Build articles, Build articles). Do you have a suggestion to eliminate the redundancy?

s-pace
commented
6 years ago @jayhesselberth
Those selectors defined a specific records structure. They are representing the extracted data thanks to a specific algorithm. They are also used in order to fine tune the algolia ranking formula.
You have repetition there because the result you are highlighting must have an empty text level and only the lvl0 set.
The search UI is open source and available here. I don't think you need to dig too much in this part.
Mostly the highest part is the lvl0, the left one is lvl1 while the nested title is a breadcrumb of the other levels.
For example:

lvl0=Configuring the search results lvl1=DocSearch Options lvl2=handleSelected text=We already bind...
hadley
commented
6 years ago I think we should probably consider search from the ground-up, and then think about how to generate optimal output for docsearch. I think the place to start with the reference and the articles. For these two categories, we can generate a simple sitemap using topic_index and article_index. That gives a whitelist of files to search.
Next we need to think about how the page structure should map to docsearch's levels. For function reference, it seems like the function title should be lvl0, and then the function name lvl1 and then the section headers can be lvl2. We could map definition terms to lvl3, since that would add useful granularity for usage and results. We may want to consider customising the display of the search because docsearch assumes a documentation structure common found in languages that use message-passing OO, i.e. you have a single page that documents a bunch of methods, often with fairly small fragments. R's documentation is different since it is organised around functions (possibly generic), and the amount of documentation for an individual tends to be much higher. Articles are simpler: the title will be lvl0, <h1>s will be lvl1, <h2>s lvl2, and so on. All pages should already have a <div> with class contents that we can use to weed-out the sidebar etc.
hadley
commented
6 years ago Oh arguments are placed in a table - we might want to consider mapping \describe to a table in general.
hadley
commented
6 years ago I was thinking we might need different selectors for articles and reference, but I think this will do nicely:
"selectors": {
"lvl0": ".contents h1",
"lvl1": ".contents h2",
"lvl2": ".contents h3, .contents th, .contents dt",
"lvl3": ".contents h4",
"lvl4": ".contents h5",
"text": ".contents p, .contents li, .usage, .articles .contents .pre"
}It looks like there's a bit of inconsistency with the .page-header div; we should make sure it's either consistently inside of the .contents div or before it.
hadley
commented
6 years ago And we should have a standard selector that we can use to exclude results (e.g. "see also") from search.
hadley
commented
6 years ago Hmmm, we might want to consider indexing pre in articles, since that will show function usage.
hadley
commented
6 years ago @s-pace is docsearch ok with the text form of the sitemap protocol? Or does it need to be xml?
s-pace
commented
6 years ago 👋 @hadley
So far sitemap must be xml. They must be compliant with this standard
Most of the time we don't recommend to index code-like element since it introduces some noise.
We can even use specific classes (with no style). It might be easier to integrate in a html POV.
hadley
commented
6 years ago @s-pace that standard includes other formats: https://www.sitemaps.org/protocol.html#otherformats, so technically I am in compliance 😉
hadley
commented
6 years ago Here's the latest appearance (searching for "extra" on pkgdown)
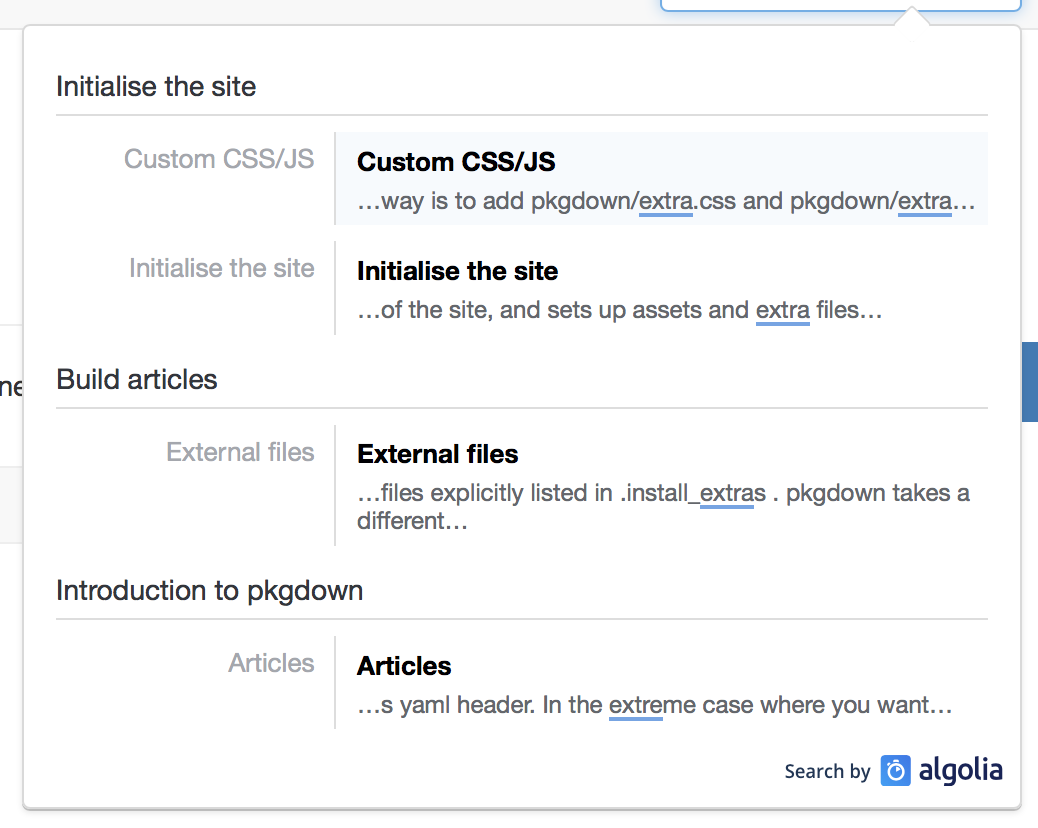
I think we need to include the alias/article name somewhere (perhaps in the lvl0?). We also need consider the default styling: few hits are going to use lvl2 headings (only in parameter search) so we get the lvl1 heading shown in two places.
s-pace
commented
6 years ago 👋 @hadley,
I have tried to use your xml sitemap from our scrapper and it works well 👏. Let's use this one then.
I have tried to check on the result pages but I couldn't find what do you mean by alias/article name? We pick up every header. Could you show us a screenshot of which part you meant?
Regarding the "duplicate titles" when no lvl2 are set, we could think about adding a default value or what would you like to display instead? We highly recommend to have at least 3 different levels set.
jayhesselberth
commented
6 years ago For reference pages, I think we selectors like this, once #604 is done and there is something like <meta func-name="init_site()"> implemented. Note that h2 is demoted here.
"selectors": {
"lvl0": ".title, .page-header h1",
"lvl1": ".meta func-name",
"lvl2": ".contents h2",
"lvl3": ".contents h3, .contents table th",
"lvl4": ".contents h4",
"lvl5": ".contents h5",
"text": ".contents p, .contents li, .usage"
}
@s-pace the alias/article name does not currently exist on the page, which is why you can't see it 😉
There's no real way to have three levels of with R documentation as it's constructed in a different way to the other languages you are used to dealing with. R is primarily a functional programming language, so each function tends to have it's own documentation page, and it really only makes sense to have one level of headings underneath that.
@jayhesselberth I think we'll also need something in the lvl1 position for articles.
hadley
commented
6 years ago Documentation "name" now included in .name, which is hidden with css.
jayhesselberth
commented
6 years ago We can also hide one of the levels in the search results by modifying the algolia CSS. I think this is what they did in the docusaurus search results.
s-pace
commented
6 years ago @hadley Thank you for the heads up.
You can otherwise use the active element from your navbar-nav as lvl0.
@jayhesselberth you can use tags and selectors_key if you want to enhance the scope of your config.
hadley
commented
6 years ago Let's try using the "filename" as lvl1:
{
"index_name": "pkgdown",
"start_urls": "http://pkgdown.r-lib.org",
"sitemap_urls": "http://pkgdown.r-lib.org/sitemap.xml",
"selectors": {
"lvl0": ".contents h1",
"lvl1": ".contents .name",
"lvl2": ".contents h2",
"lvl3": ".contents h3, .contents th, .contents dt",
"lvl4": ".contents h4",
"text": ".contents p, .contents li, .usage, .template-article .contents .pre"
},
"selectors_exclude": ".dont-index"
}For the reference part, you could use the section data type as a hidden object within the page. e.g. http://valr.hesselberthlab.org/reference/index.html
s-pace
commented
6 years ago Quick feedback.
selectors_exclude, start_urls and sitemap_urls should be an arrayhadley
commented
6 years ago Can we just provide a site map instead of a start url? I think we only want to index the pages listed in the sitemap.
s-pace
commented
6 years ago Yes you can.
The url of start_urls (or their attribute url for more advanced object) behave as regex on the sitemap. You will have to put a regex that isn't available from a http request POV.
Otherwise you can use sitemap_urls_regexs and sitemap_urls together.
hadley
commented
6 years ago Like "start_urls" = ["http://pkgdown.r-lib.org/DOESNTEXIST"] ?
hadley
commented
6 years ago And maybe set "force_sitemap_urls_crawling" = "true" ?
jayhesselberth
commented
6 years ago It looks like you can just use the base URL for start_urls. E.g. see this config.
s-pace
commented
6 years ago "start_urls" = ["http://pkgdown.r-lib.org/DOESNTEXIST"] ?
If you use a sitemap and you want to use tags, extra_attributes or specific selectors_key you should do something like
"start_urls": [
{
"url": "http://pkgdown.r-lib.org/reference/",
"variables": {
"tags": [
"reference"
]
},
"selectors_key": "reference"
}
],And maybe set "force_sitemap_urls_crawling" = "true" ?
This parameter is only involving sitemap_urls & sitemap_urls_regexs. It is there to say that the URL from the sitemap don't have to respect the stop_urls. It shouldn't be used here
It looks like you can just use the base URL for start_urls. E.g. see this config.
You can use that indeed.
s-pace
commented
6 years ago Please wrap the whole following element by .dont-index:
 Since we currently have:
Since we currently have:
 REF
REF
s-pace
commented
6 years ago .contents dt should be in the text selector:
 Otherwise you will not have a good hierarchy like that:
Otherwise you will not have a good hierarchy like that:
 We will build to records one for
We will build to records one for .contents th and another for .contents dt without any text attribute
(The time of appearance matters)
@jayhesselberth @hadley
jayhesselberth
commented
6 years ago @s-pace thanks, moving .contents dt to the text selector does improve the granularity of display.
hadley
commented
6 years ago Isn't that <td> not <dt>?
jayhesselberth
commented
6 years ago Yep should be <dt>. Gah! <td>
s-pace
commented
6 years ago Actually since your td is wrapping a p element you shouldn't put it
s-pace
commented
6 years ago @hadley Could you PR the pkgdown like configs once it is live? Since we have some new pkgdown requests, we would like to update all of them in the same way. Thanks and 👏
There are now a few docsearch configs for pkgdown sites, and they all have somewhat different scrape parameters. This could probably be made more consistent by optimizing css ids/classes for scraping.
https://github.com/algolia/docsearch-configs/blob/master/configs/valr.json https://github.com/algolia/docsearch-configs/blob/master/configs/pkgdown.json https://github.com/algolia/docsearch-configs/blob/master/configs/mlr.json
I wonder if the Docsearch team should be made aware that several pkgdown sites may be submitted? I think they tweak each of these manually which could be a waste of time; you might be able to provide them with a standard scrape json.