 ranahanocka
commented
4 years ago
ranahanocka
commented
4 years ago Hi,
you can do it with tensorboard. Install tensorboard and tensorboardX. Then run tensorboard --logdir runs and click http://localhost:6006.
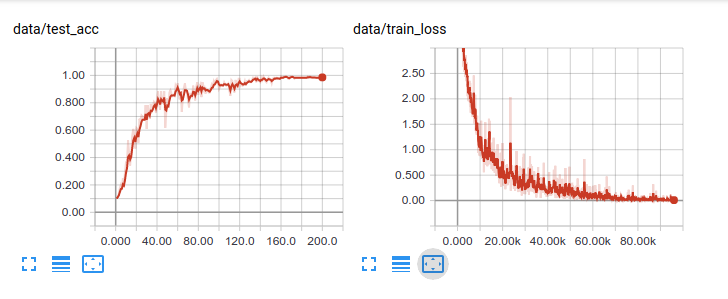
The plots for SHREC classification look like this:
 claell
claell
I'd like to plot the progress of the training and validation progress (train / test accuracy and loss) over the epochs. Is that easily achievable?