 snasovich
commented
10 months ago
snasovich
commented
10 months ago Per @jakefhyde to fix this we will need to switch to using Steve (v1) APIs from currently used Norman (v3) - or even to native k8s - both are pretty big undertakings so this may take a while to address especially since the immediate issue is now addressed on rancher/rancher since 2.7.5+.
 a-blender
a-blender boldynnetwork
boldynnetwork riuvshyn
riuvshyn weiyentan
weiyentan
Important: Please see https://github.com/rancher/terraform-provider-rancher2/issues/993#issuecomment-1611922983 on the status of this issue following completed investigations.
Rancher Server Setup
Information about the Cluster
RKE2 v1.23.9+rke2r1running on AWSrancher/rancher2version1.24.1cluster configuration:
``` { "kubernetesVersion": "v1.23.9+rke2r1", "rkeConfig": { "upgradeStrategy": { "controlPlaneConcurrency": "1", "controlPlaneDrainOptions": { "enabled": false, "force": false, "ignoreDaemonSets": true, "IgnoreErrors": false, "deleteEmptyDirData": true, "disableEviction": false, "gracePeriod": 0, "timeout": 10800, "skipWaitForDeleteTimeoutSeconds": 600, "preDrainHooks": null, "postDrainHooks": null }, "workerConcurrency": "10%", "workerDrainOptions": { "enabled": false, "force": false, "ignoreDaemonSets": true, "IgnoreErrors": false, "deleteEmptyDirData": true, "disableEviction": false, "gracePeriod": 0, "timeout": 10800, "skipWaitForDeleteTimeoutSeconds": 600, "preDrainHooks": null, "postDrainHooks": null } }, "chartValues": null, "machineGlobalConfig": { "cloud-provider-name": "aws", "cluster-cidr": "100.64.0.0/13", "cluster-dns": "100.64.0.10", "cluster-domain": "cluster.local", "cni": "none", "disable": [ "rke2-ingress-nginx", "rke2-metrics-server", "rke2-canal" ], "disable-cloud-controller": false, "kube-apiserver-arg": [ "allow-privileged=true", "anonymous-auth=false", "feature-gates=CustomCPUCFSQuotaPeriod=true", "api-audiences=https://Additional info:
additional_manifestDescribe the bug Occasionally simple cluster configuration change for example change lables in manifests passed via
additional_manifestapplied with terraform provider causing managed RKE2 cluster to destroy.terraform plan looks similar to this:
Terraform Plan output
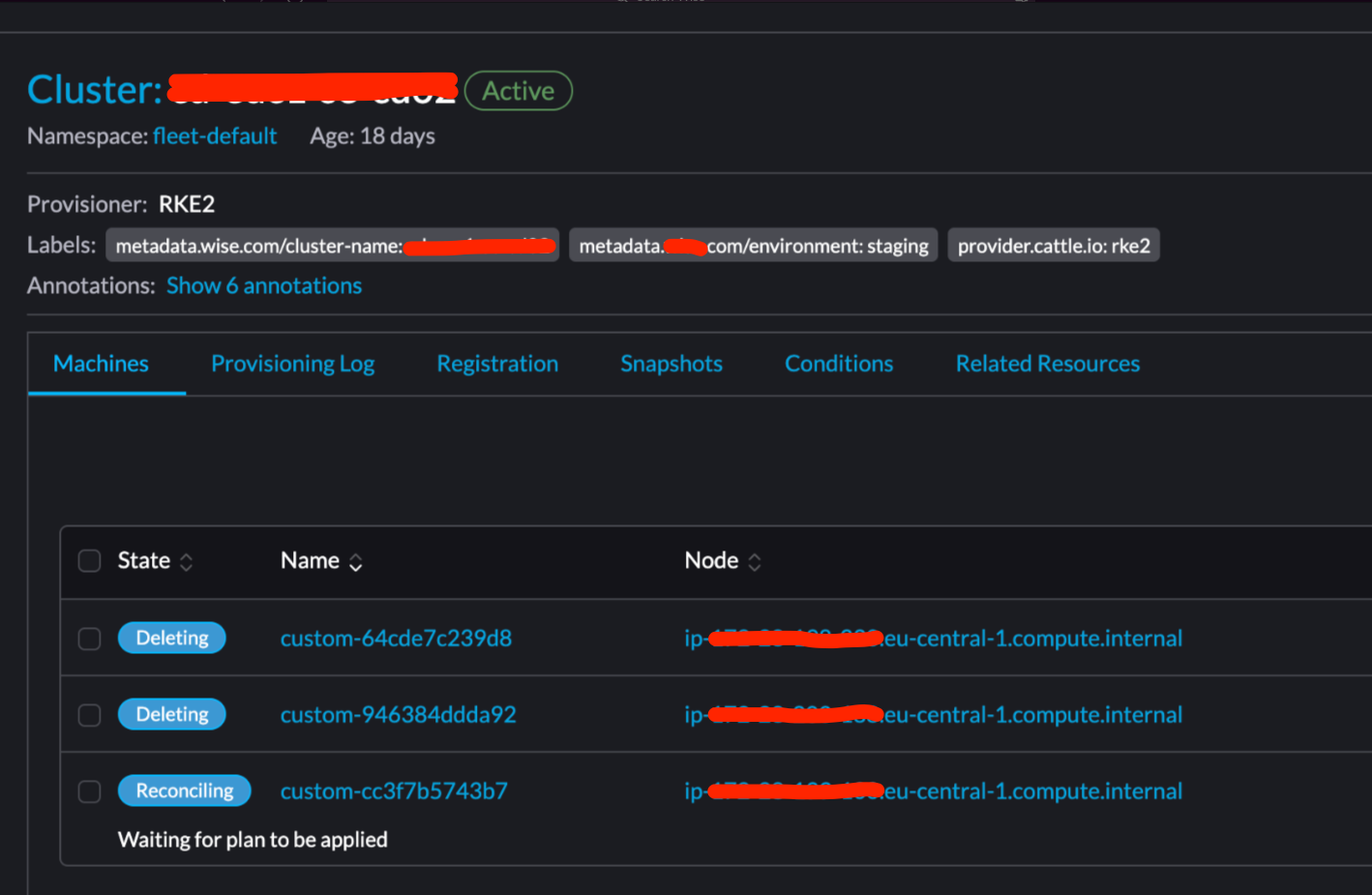
``` Terraform will perform the following actions: # module.cluster.rancher2_cluster_v2.this will be updated in-place ~ resource "rancher2_cluster_v2" "this" { id = "fleet-default/o11y-euc1-se-main01" name = "o11y-euc1-se-main01" # (10 unchanged attributes hidden) ~ rke_config { ~ additional_manifest = <<-EOT --- apiVersion: v1 kind: Namespace metadata: labels: - test: test + test1: test1 name: my-namespace EOT } } ```Sometimes once change like this is applied rancher immediately trying to delete that managed cluster for some reason. On UI it looks like this:
Rancher UI screenshot:
Rancher logs:
rancher logs:
``` 2022/09/08 08:58:30 [DEBUG] [planner] rkecluster fleet-default/On RKE2 bootstrap node in
rke2-serverlogs we can see this:rke2-server logs on bootstrap node
``` Sep 07 11:41:57 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:41:57Z" level=info msg="Removing name=ip-yyy-yy-yy-yyy.eu-central-1.compute.internal-ee7ac07c id=1846382134098187668 address=172.28.74.196 from etcd" Sep 07 11:41:57 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:41:57Z" level=info msg="Removing name=ip-zzz-zz-zz-zzz.eu-central-1.compute.internal-bc3f1edb id=12710303601531451479 address=172.28.70.189 from etcd" Sep 07 11:42:10 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:42:10Z" level=info msg="Stopped tunnel to zzz.zz.zz.zzz:9345" Sep 07 11:42:10 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:42:10Z" level=info msg="Stopped tunnel to yyy.yy.yy.yyy:9345" Sep 07 11:42:10 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:42:10Z" level=info msg="Proxy done" err="context canceled" url="wss://yyy.yy.yy.yyy:9345/v1-rke2/connect" Sep 07 11:42:10 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:42:10Z" level=info msg="Proxy done" err="context canceled" url="wss://zzz.zz.zz.zzz:9345/v1-rke2/connect" ```To Reproduce Unfortunately I can't reproduce this reliably but this happens very often. Steps I am using to reproduce this issue:
additional_manifestfor RKE2 clusterResult Occasionally managed cluster gets deleted by rancher.
Expected Result Change is actually applied and clusters is not deleted.
I did some tests that does exactly the same change (modify
additional_manifest) bypassing terraform by calling rancher API directly and that never caused cluster deletion for 2k+ iterations. While using terraform provider some times it takes up to 10 attempts to reproduce this issue.I am happy to provide any other info to investigate this further. This is causing massive outages for my clusters as they are just getting destroyed.