 popcornmix
commented
11 years ago
popcornmix
commented
11 years ago If a workaround in the driver makes it work better for the majority of users, then sure it should be included. Do you have a suitable patch?
Closed rewolff closed 7 years ago
popcornmix
commented
11 years ago If a workaround in the driver makes it work better for the majority of users, then sure it should be included. Do you have a suitable patch?
 rewolff
commented
11 years ago
rewolff
commented
11 years ago No. Not yet.
1) I have not delved into the I2C driver yet. Around a year ago, I had plans to write it myself but before I got around to it, someone else had written it. So someone who already knows this driver might be better equipped to do this as a five minute project. It would take me at least several hours to get to know the driver. 2) It pays to first discuss it if you (and maybe others) agree that a fix/workaround is warranted. 3) I just wanted to document this as a "todo" we shouldn't forget it.... 4) Maybe someone would suggest a different workaround.
Speaking about workarounds: The workaround could also be triggered by the SDA line still being low when we are trying to initiate a new transaction. That is clearly a "problem" situation.
The "it goes wrong" case might be rare for "normal" cases. Many people will have a hardware-i2c module on the I2C-bus. Back when I2C was invented "10us" might have been a "very short" timeframe for some chips to handle the requests, so clock stretching was necessary. Nowadays any hardware I2C implementation should be able to handle "fast I2C" up to even faster.
This combines with the way the atmel guys implemented their async modules. Instead of having the module run on the externally provided clock (i2c-slave or SPI-slave), the module still runs on the processor clock. And it synchronizes all incoming signals by passing them through a bunch of filpflops. Good hardware design. The alternative is IMHO better: run the module off the external clock, and synchronize when the data passes to the other (cpu-) clock domain. This would for example allow the SPI module to function at 20MHz, even though the CPU runs at only 8.
Anyway. Enough hardware rambling.
Suggested workaround: Issue an extra clock cycle when at the beginning of a transaction the SDA line is still low. (it should start out high to be able to issue a "start" condition).
popcornmix
commented
11 years ago Firstly, I know little about I2C. I have spoken to Gert and others about workarounds.
There are two problems with I2C known about:
For 1, Gert's view is there is no foolproof workaround. If I2C slave doesn't support clock stretching you are fine. If I2C clock stretches by a bounded amount, then lowering the I2C clock frequency can avoid the problem Switching to a bit banging driver for slaves that don't fall in the previous cases is a safe workaround.
I don't know if your proposal will work. I'd be interested to hear if it reduces the problem, or fixes it completely.
Gert says he has a desciption of the bug that he'll try and get released.
For 2, in the GPU I2C driver we have some code working around a problem with state machine:
/***********************************************************
* Name: i2c_actual_read
*
* Arguments:
* const I2C_PERIPH_SETUP_T *periph_setup,
const uint32_t sub_address,
const uint32_t data_to_read_in_bytes,
void *data
*
* Description: Routine to actually transfer data to the I2C peripheral
*
* Returns: int == 0 is success, all other values are failures
*
***********************************************************/
static int32_t i2c_actual_read( const I2C_PERIPH_SETUP_T *periph_setup,
const I2C_USER_T *user,
const uint32_t sub_address,
const uint32_t read_nbytes,
void *data,
const int using_interrupt)
{
int32_t rc = -1; /* Fail by default */
int32_t status = 0;
int32_t nbytes;
uint32_t sub;
uint8_t* read_data = (uint8_t*)data;
uint32_t data_read = 0;
if( NULL != periph_setup && NULL != data ) {
// confirm that the latch is held for this transaction
assert( i2c_state.periph_latch[ periph_setup->port ] != rtos_latch_unlocked() );
// -> START
// -> Slave device address | WRITE
// <- Ack
// -> Sub address
// <- Ack
// -> Sub address
// <- Ack
// -> ReSTART
// -> Slave device address | READ
// <- Ack
// <- Data[0]
// -> Ack
// <- Data[1]
// -> nAck
// -> STOP
I2CC_x( periph_setup->port ) = I2CC_EN | I2CC_CLEAR; /* Enable I2C and clear FIFO */
I2CS_x( periph_setup->port ) = I2CS_ERR | I2CS_DONE | I2CS_CLKT; /* clear ERROR and DONE bits */
I2CA_x( periph_setup->port ) = periph_setup->device_address;
sub = sub_address;
nbytes = periph_setup->sub_address_size_in_bytes;
if( 0 == nbytes ) {
/* No subaddress to send - just issue the read */
} else {
/*
See i2c.v: The I2C peripheral samples the values for rw_bit and xfer_count in the IDLE state if start is set.
We want to generate a ReSTART not a STOP at the end of the TX phase. In order to do that we must
ensure the state machine goes RACK1 -> RACK2 -> SRSTRT1 (not RACK1 -> RACK2 -> SSTOP1).
So, in the RACK2 state when (TX) xfer_count==0 we must therefore have already set, ready to be sampled:
READ ; rw_bit <= I2CC bit 0 -- must be "read"
ST; start <= I2CC bit 7 -- must be "Go" in order to not issue STOP
DLEN; xfer_count <= I2CDLEN -- must be equal to our read amount
The plan to do this is:
1. Start the sub-add]ress write, but don't let it finish (keep xfer_count > 0)
2. Populate READ, DLEN and ST in preparation for ReSTART read sequence
3. Let TX finish (write the rest of the data)
4. Read back data as it arrives
*/
assert( nbytes <= 16 );
I2CDLEN_x( periph_setup->port ) = nbytes;
I2CC_x( periph_setup->port ) |= I2CC_EN | I2CC_START; /* Begin, latch the WRITE and TX xfer_count values */
/* Wait for us to leave the idle state */
while( 0 == ( I2CS_x(periph_setup->port) & (I2CS_TA|I2CS_ERR) ) ) {
_nop();
}
}
/* Now we can set up the parameters for the read - they don't get considered until the TX xfer_count==0 */
I2CDLEN_x( periph_setup->port ) = read_nbytes;
I2CC_x( periph_setup->port ) |= I2CC_EN | I2CC_START | I2CC_READ;
/* Let the TX complete by providing the sub-address */
while( nbytes-- ) {
I2CFIFO_x( periph_setup->port ) = sub & 0xFF; /* No need to check FIFO fullness as sub-address <= 16 bytes long */
sub >>= 8;
}
/* We now care that the transmit portion has completed; the FIFO is shared and we mustn't read out
any of the data we were planning on writing to the slave! */
/* Wait for peripheral to get to IDLE or one of the two RX states - this way we *know* TX has completed or hit an error */
{
uint32_t state;
bool_t state_transition_complete;
bool_t error_detected;
do {
state = (I2CS_x( periph_setup->port ) & 0xf0000000) >> 28;
state_transition_complete = ((state == 0) || (state == 4) || (state == 5));
error_detected = (I2CS_x(periph_setup->port) & (I2CS_ERR | I2CS_CLKT)) != 0;
} while(!state_transition_complete && !error_detected);
if (error_detected) {
/* Clean up, and disable I2C */
I2CC_x( periph_setup->port ) &= ~(I2CC_INTD | I2CC_INTR);
I2CC_x( periph_setup->port ) &= ~(I2CC_START | I2CC_READ);
I2CS_x( periph_setup->port ) = I2CS_CLKT | I2CS_ERR | I2CS_DONE;
I2CC_x( periph_setup->port ) |= I2CC_CLEAR;
I2CC_x( periph_setup->port ) = 0;
return -1;
}
}
if (using_interrupt)
{
/* Wait for interrupt to complete. */
i2c_state.active_buffer[periph_setup->port] = data;
i2c_state.active_buffer_length[periph_setup->port] = read_nbytes;
i2c_state.active_buffer_offset[periph_setup->port] = 0;
i2c_state.pending_transfer[periph_setup->port] = I2C_PENDING_TRANSFER_READ;
RTOS_LATCH_T latch = rtos_latch_locked();
i2c_state.pending_latch[periph_setup->port] = &latch;
/* Enable interrupt. */
I2CC_x( periph_setup->port ) |= I2CC_INTD | I2CC_INTR;
rtos_latch_get (&latch);
i2c_state.pending_latch[periph_setup->port] = NULL;
data_read = i2c_state.active_buffer_offset[periph_setup->port];
rc = (data_read == read_nbytes) ? 0 : -1;
}
else
{
uint32_t time_now = 0;
/* Loop until we've read all our data or failed. */
while( 0 == ( I2CS_x(periph_setup->port) & (I2CS_TA|I2CS_ERR|I2CS_DONE) ) ) {
_nop();
}
/* Wait for some data to arrive - we should wait, at most, I2C_TIMEOUT_IN_USECS for data to arrive every time we start waiting */
time_now = i2c_state.systimer_driver->get_time_in_usecs( i2c_state.systimer_handle );
while( ((i2c_state.systimer_driver->get_time_in_usecs( i2c_state.systimer_handle ) - time_now) < I2C_TIMEOUT_IN_USECS)
&& ( data_read < read_nbytes )
&& !(I2CS_x( periph_setup->port ) & I2CS_ERR) )
{
if (I2CS_x( periph_setup->port ) & I2CS_RXD)
{
read_data[ data_read ] = I2CFIFO_x( periph_setup->port );
data_read++;
time_now = i2c_state.systimer_driver->get_time_in_usecs( i2c_state.systimer_handle );
}
}
if( (data_read != read_nbytes) /* Did we read all the data we asked for? */
|| ( (read_nbytes - data_read) != I2CDLEN_x( periph_setup->port ) ) /* Has DLEN decremented? */
|| ( 0 != (I2CS_x( periph_setup->port ) & I2CS_ERR) ) ) { /* Are there any errors? */
rc = -1;
} else {
while( I2CS_DONE != (I2CS_x(periph_setup->port) & I2CS_DONE) ); /* Wait for the peripheral */
rc = 0;
}
}
/* Clean up, and disable I2C */
I2CC_x( periph_setup->port ) &= ~(I2CC_INTD | I2CC_INTR);
if(I2CS_x( periph_setup->port ) & I2CS_ERR) {
//Wait for it to be idle
while(I2CS_x( periph_setup->port ) & I2CS_TA)
_nop();
}
I2CS_x( periph_setup->port ) = I2CS_ERR | I2CS_DONE;
//Finally disable the I2C
I2CC_x( periph_setup->port ) = 0x0;
}
if( !user->skip_asserts ) {
assert( rc >= 0 );
_nop();
}
return rc;
} I'm not sure if people are hitting this issue, but the pasted could may be helpful if you are.
rewolff
commented
11 years ago It is not possible to completely eradicate this hardware bug.
When it happens, the master and slave disagree on the number of clock cycles. Therefore, the data, as interpreted by the slave and the data as the master (= raspberry pi = driver/application) intended differ. You might be writing a completely bogus value in a register somewhere. Highly annoying.
My suggested workaround would at least cause the next transaction to work. The impact would be halved: only one transaction botched instead of two. It would not eliminate the problem.
If I2C slave doesn't support clock stretching you are fine.
If the I2C slave doesn't require clock stretching....
If I2C clock stretches by a bounded amount, then lowering the I2C clock frequency can avoid the problem
Yes. I have 10 devices "in the field" at one location. Apparently the clock frequency (RC clock) of three of the modules is different in such a way that they end up "done" with the clock stretching in exactly the wrong moment. Reducing the clock frequency fixed the problems for those modules.
If the clock stretching delay is NOT fixed, but, say, varies by more than 5 microseconds, there is a more or less statistical chance of hitting the problem. In my case the slave requires 0.25 microseconds of clock width. So clock stretching ends in the 5% of the time leading up to the clock changing moment for the BCM, then things go wrong. So, in this case, about 1 in 20 transfers would go wrong. (specs say min 250ns for a clock pulse. That in fact doesn't mean that it won't be seen if it is shorter. I think the chances of it being seen goes linearly from 100% at > 250ns to 0% at < 125ns. )
I've spent yesterday stretching the clock stretching period in such a way that it would fall around the 2.5 microsecond mark in the 5 microsecond window-of-opportunity. If I'd aim for the start of the window and my RC clock runs bit fast, I'd hit the "0" which triggers the bug. If I aim for 5, same thing. So now I'm aiming in the middle, away from the bad places. But change the I2C clock to 80kHz, and BAM, I'm aiming right for the sensitive spot... (and if it doesn't happen with 80kHz, it'll happen with some value between 80 and 100).
popcornmix
commented
11 years ago Here is Gert's description of the I2C bug: https://dl.dropbox.com/u/3669512/2835_I2C%20interface.pdf
rewolff
commented
11 years ago Haha! I have instrumented my test-board in exactly the same way. I've cut the SCL trace and mounted a 0.1" jumper connector on there. While not measuring there is a normal jumper there, or a female connector with a 100 ohm resistor when I am.
I don't think it only happens on the first clock. That would mean I could work around the problem by either NOT clock stretching at all (as most hardware I2C chips probably do), or by causing the clock stretch to last at least a full cycle.
I have instrumented my i2c slave code in such a way that I can cause the clock stretch to change by 0.5 microsecond increments. I can command it to change the clock stretch to XXX over I2C and then it works like that for 50 miliseconds before changing back to the default values. (in case it doesn't work we need it working again. This way I can quickly scan a whole range of values for these settings, while monitoring the SDA and SCL lines with a logic analyzer. Sending a "use delay XXX" and then sending a sting takes 25 miliseconds. THen incrementing a counter in the script and sending the "next delay" takes the shell script about 100ms. So I can scan 100 possible values in about 10 seconds.
I HAVE seen the bug happening on longer delays. So the theory: "it only happens on the first" is not correct.
As to the "super efficient" interrupt handler: Yes, I can do that too. The thing is: The clock stretching feature allows me to put the "handle this byte" code in the interrupt routine and not worry about it taking a few microseconds or a few miliseconds. In theory the clock stretching will make sure that the master waits for me to finish handling this byte before continuing with the next one. That plan is totally busted with the bug in the 2835. I now just cause clock stretching to stop, and then hope to finish handling the byte in the 70 microseconds that follow.
I have to "cycle count" to aim for the middle of the 5 microsecond half-clock for me to release the clock stretching. If I'd aim for the start (to cause a 4.9 microsecond clock-high-period) the clock on my slave might be running a few percent faster and cause the bug to trigger a half-cycle earlier. So both ends of the half-clock cycle are dangerous, I have to aim for a short, but valid enough clock cycle.
The change in the module is IMHO simple: When SCL is "driven high" (i.e. not driven at all), stop the I2C module master clock. This has the side effect of allowing much longer I2C buses because automatic clock stretching occurs when the bus capacitance is above spec.
 iz8mbw
commented
11 years ago
iz8mbw
commented
11 years ago This: http://comments.gmane.org/gmane.linux.kernel.rpi/268 and this: http://news.gmane.org/gmane.linux.kernel.rpi can help?
rewolff
commented
11 years ago Thanks for trying to help, iz8mbw, but those have nothing to do with this (hardware) bug.
I've measured my I2C clock and it comes out as 100kHz which the driver thinks it should be. The driver has a "clock source" object which it queries for the frequency and it uses that. I have not yet instrumented my driver to print out the frequency.
rewolff
commented
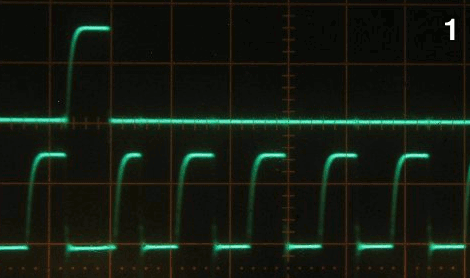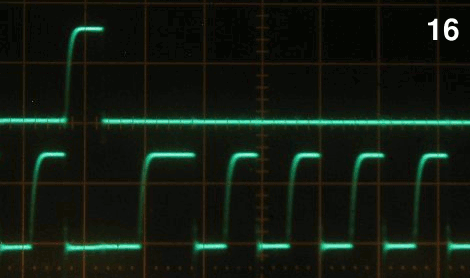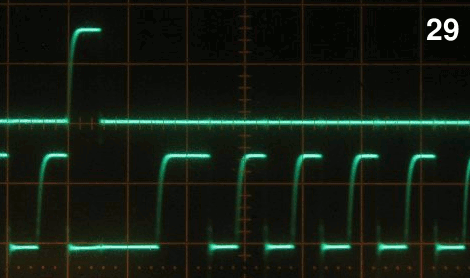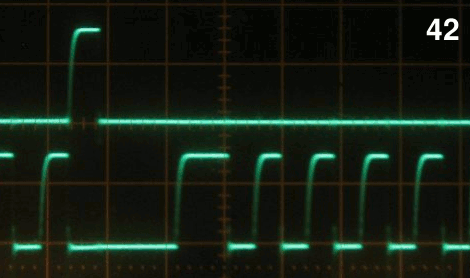
11 years ago Just for information for people who want to SEE the bug in action I have some "proof" in the form of a logic analsyer dump. Hmm I can attach images, but not the binary LA dump. That one is here: http://prive.bitwizard.nl/LA_with_bug_scan_50_to_100_microseconds_delay.bin.gz
In the image LA_with_bug_shot1.png you'll see the short burst of activity: "set delay to XXX" then a small burst that tries to write some 10 bytes, but it gets aborted due to a NACK. On the right you see a proper 10-byte-packet. The SDA line remains low until the next burst that is misaligned (all bits are shifted, and in my slave the "xth-byte-in-packet" counter has not been reset by the non-existant start condition at the start of that packet.
In the image LA_with_bug_shot2.png I've zoomed in to the section where the short pulse happens. This the longest pulse that I've seen go wrong: 290ns. (above datasheet-spec for the Atmel!)


 rfmerrill
commented
11 years ago
rfmerrill
commented
11 years ago Oh so THAT's where that came from!
I've got a project I'm trying to control with I2C from a raspberry pi and I'm honestly close to just giving up and either switching to a beagleboard or having the Pi talk to an FPGA via SPI which then does the I2C stuff.
rewolff
commented
11 years ago I have a board in the mail that should be able to do that (expected delivery: tomorrow). SPI connector, I2C connector. Would be a nice project to try with that board. Send me an email if you want to be kept informed.
Current situation: I'm seeing behaviour compatible with Gert's: "only the first cycle can go wrong" when the slave is an ATMEGA, and I'm seeing the bug in full force when the slave is one of my ATTINYs.
Here are the delays I tested:
 and the shortest SCL pulse observed during this test-session was 4.5 microseconds.
and the shortest SCL pulse observed during this test-session was 4.5 microseconds.
Now testing with the attiny slave, the tested delays for the ACK are:

and the minimum pulse width is 41ns (my measurement resolution):

Ah. Found it! It seems that clock stretching before the ACK of a byte is "dangerous" but clock stretching AFTER the ACK is ok.....
 markdootson
commented
11 years ago
markdootson
commented
11 years ago I and others are certainly hitting the repeated start issue. I have a userspace hack at http://cpansearch.perl.org/src/MDOOTSON/HiPi-0.26/BCM2835.xs in proc hipi_i2c_read_register_rs. This seems to work for the users who have reported trying it or incorporating the C code ( though that's only 5 people ), even though I had not figured out correctly how to determine that the TX stage had completed. I suppose I need to learn to compile kernel modules and run existing tests against code above.
 Ferroin
commented
11 years ago
Ferroin
commented
11 years ago Couldn't we just force the kernel to ignore the I2C hardware and use bitbanged GPIO-based I2C on the same pins? I would think the overhead for that would be more acceptable then the bugs in the hardware itself.
rewolff
commented
11 years ago What overhead do you expect? The current driver defaults to 100kHz clock. So reading 10 bytes from an i2c intertial sensor takes about 1ms. If you bitbang, you're likely to be churning CPU cycles all that time....
popcornmix
commented
11 years ago My preference would be for the driver to optionally support bitbanging i2c through a module parameter (or maybe a separate module if that is more convenient).
Many devices don't use clock stretching (or clock stretch by a bounded amount so can work correctly at reduced speed), so the hardware I2C driver is still preferable in those cases.
Ferroin
commented
11 years ago The kernel itself has a driver for bitbanged I2C on GPIO pins, this driver has much lower overhead than bitbangging from userspace, and exposes the same API as the hardware I2C drivers. My suggestion would be to compile both that driver and the hardware I2C driver as modules, then load the hardware driver by default.
popcornmix
commented
11 years ago @Ferroin Do you use the bitbanged I2C driver on Pi? What .config options have you added to build it? Any source patches? What do you do to choose the driver to use (modprobe? different /dev/ devices?)
Ferroin
commented
11 years ago Haven't used the driver on the Pi, but I have a friend who uses it successfully on a BeagleBoard. The config option is I2C_GPIO. If both that and the broadcom driver were configured as modules, choosing the driver would be as simple as loading the kernel module. The GPIO module does need parameters to tell it which GPIOs to use as SDA and SCL, I don't know what the parameters are, but based on the not very well documented source in dirvers/i2c/busses/i2c-gpio.c, it looks like the apropriate params are 'sda=X scl=Y' where X and Y are the pins you ant to use.
 kadamski
commented
11 years ago
kadamski
commented
11 years ago The i2c-gpio module itself does not provide any way to pass parameters to it. So you need another module that registers platform data and configures at least bus number, SDA and SCL pins. I've written proof of concept of such a module and it even worked on pins 0 and 1 but without i2c-bcm2708 loaded (pcf8574 was detected by i2cdetect, I was able to drive some LED with gpio-pcf857x module). But then I burned my pcf8574 when changing the pins (and I don't have any other i2c chips right now) so I couldn't really test it. Here's the code
popcornmix
commented
11 years ago @kadamsi Making sda_pin/scl_pin module parameters may be useful. As would a pull request. Can anyone confirm this works for them?
rewolff
commented
11 years ago That is less trivial than it looks: It expects to be passed a platformdata structure all the way.
On the other hand, the platform does not dictate which GPIOs you are going to use today, so putting in the work to change it does sound reasonable. (normally the platform data specifies: "How is /this/ computer wired". )
kadamski
commented
11 years ago @popcornmix
I'm planning to make them configurable, I just had not enough time yesterday. I would also like it to be able to create more than one bus at a time. Maybe in dynamic way, like GPIOS export and unexport sysfs files (but I'm not sure if it's possible to cleanly unexport such bus)? Oh, and I found another pcf8574 and could confirm that it worked well also on different GPIO pins when external pullup resistors are used. Unfortunately I don't have more sophisticated I²C devices to test. So are you interested in providing such module in default kernel tree?
popcornmix
commented
11 years ago @kadamski I don't have a setup to test modules like this. However any hardware features the chip provides (like I2C) should have kernel drivers to allow more people to use them. If the I2C hardware has bugs that will stop people using certain peripherals then a bitbanging alternative sounds worthwhile.
So, if you produce a new driver that looks harmless for people not using it (i.e. built as a module, and doesn't nothing until loaded), and there's some evidence (i.e. some confirming user reports) it is working correctly, then I'm happy to accept a PR.
 hkapanen
commented
8 years ago
hkapanen
commented
8 years ago Has the HW been fixed on BCM2837 (in RPi 3)?
rewolff
commented
8 years ago My guess is: no. But I probably don't have time to test this today.
 P33M
commented
8 years ago
P33M
commented
8 years ago BCM2837 I2C is unchanged.
hkapanen
commented
8 years ago That's unfortunate, but thanks for the info.
 markab
commented
8 years ago
markab
commented
8 years ago thats very annoying.
 RalphCorderoy
commented
8 years ago
RalphCorderoy
commented
8 years ago I agree. Does anyone have a link to BCM2837 errata, or similar, stating the problem still exists? Would be handy when we have to pass the news on. Or @P33M, perhaps you can be quoted as authoritative if you work for Broadcom?
 JamesH65
commented
8 years ago
JamesH65
commented
8 years ago He is authoritative, although doesn't work for Broadcom.
RalphCorderoy
commented
8 years ago That's good. But I've already Googled, and apart from P33M being M33P elsewhere, struggle to find an ID I can usefully pass on. Which is fine, but means he's not a great source to quote. :-) So an errata link would be handy.
popcornmix
commented
8 years ago @P33M works for Raspberry Pi. You can treat what he says as authoritative.
JamesH65
commented
8 years ago I don't think there is an errata list, probably should be. I've leave him to confirm his identity, or not!
On 15 March 2016 at 14:30, RalphCorderoy notifications@github.com wrote:
That's good. But I've already Googled, and apart from P33M being M33P elsewhere, struggle to find an ID I can usefully pass on. Which is fine, but means he's not a great source to quote. :-) So an errata link would be handy.
— You are receiving this because you commented. Reply to this email directly or view it on GitHub: https://github.com/raspberrypi/linux/issues/254#issuecomment-196845789
P33M
commented
8 years ago @RalphCorderoy I am an employee of Raspberry Pi (trading) Ltd. My answer is authoritative.
RalphCorderoy
commented
8 years ago @P33M, Ta, that'll do. Sorry for the hassle.
 cinderblock
commented
8 years ago
cinderblock
commented
8 years ago This is affecting a project I'm working on. Fortunately, I have complete control over the slave device firmware and I was able to add use the workaround of adding an extra half period delay (clock stretch) in my responses which skips the bad behavior.
Good analysis of the problem can be found on advamation.com.
Is this bad hardware in Broadcom's I2C implementation or are there kernel tweaks possible to get the hardware to behave correctly?
 mwilliams03
commented
8 years ago
mwilliams03
commented
8 years ago I have just subscribed to this issue as I have also encountered this with a product I am developing which uses i2c between an AVR and Pi. Now I need to rethink it. Has anyone used any reliable form of i2c bit banging ?
 pdg137
commented
8 years ago
pdg137
commented
8 years ago @mwilliams03, you might be interested in this project, in which I successfully established 100 kHz and 400 kHz I2C communication between a Raspberry Pi and an AVR. I am not bit-banging, but instead using the hardware I2C support and inserting delays at key points. It turned out that the AVR is slow enough that at 400 kHz no extra delays are needed.
In particular, here is information about the I2C issues. Note also that the AVR's TWI module has an issue preventing quick reads.
mwilliams03
commented
8 years ago thanks @pdg137 , I tried it out and on the first go I got 1.2 million reads without errors and still going.
 Ruffio
commented
8 years ago
Ruffio
commented
8 years ago @rewolff is looks like this issue has been resolved. If that is the case, please close this issue.
rewolff
commented
8 years ago And now.... add a level shifter and 40cm of extension cable.. Does it work then? Chances are that this causes enough delay on the "up" side of the waveforms, and all of a sudden, the bug strikes again.
As far as I can tell, broadcom and employees still think that this bug is restricted to the FIRST 5 microsecond (actually half-clock) after the final bit of a byte. then just adding 10 microseconds will carry things over to two half-clocks further and there should be no problems. In my testing, I find "bad" moments to stop the clock stretching every 5 microseconds.
Due to symmetry between SPI and I2C it is easier in my AVR code if the next databyte is "calculated" in the "next data" interrupt.... (I expose an interface where continuing to read is permissable, so a 16 byte buffer is not always enough.).
I'm not convinced.
 chrisdew
commented
8 years ago
chrisdew
commented
8 years ago I'm experiencing issues with SMBus between a Respberry Pi and an ATMEGA 324PA - could these be related to this issue? https://stackoverflow.com/questions/39274784/talking-smbus-between-raspberr-pi-and-atmega-324pa-avr-not-clock-stretching
 DavidEGrayson
commented
8 years ago
DavidEGrayson
commented
8 years ago As far as I can tell, broadcom and employees still think that this bug is restricted to the FIRST 5 microsecond (actually half-clock) after the final bit of a byte.
@rewolff: I would have to agree with Broadcom employees. In my tests, with a Raspberry Pi 3 and 100 kHz I2C (which slows down to 62 kHz when the CPU is throttled), I am getting results similar to the animation from advamation.com. Are you getting experimental results that differ from that animation, or is the animation not sufficient to convince you?
rewolff
commented
8 years ago The animation seems sound. However it is not in line with my experience. Maybe I should setup a test. Might take a while. It's busy with other stuff.
But if this were the case, simply a "usleep (10)" in my interrupt routine (with hardware clock stretching) would normally do the trick and make things not lock up. I'm pretty sure that this was not the case. :-(
DavidEGrayson
commented
8 years ago @rewolff: On the Raspberry Pi 3, I have seen the CPU get throttled to 600 MHz, resulting in a default I2C speed of 62 kHz. So you should sleep for 17 microseconds in your slave's ISR if the ISR starts on the falling edge of SCL. Or if you think the CPU might get throttled to below 600 MHz, sleep for longer.
 onnokort
commented
7 years ago
onnokort
commented
7 years ago Would it be possible to include @kadamski's i2c-gpio-param module in the Raspberry Pi kernel? I can confirm that this approach seems to work quite well for my application (AVR software I2C slave) and it is somewhat cumbersome to install the required headers for the raspberry kernel, so having it available would be great.
It would also be a good workaround addressing the HW bug underlying this whole issue.
 6by9
commented
7 years ago
6by9
commented
7 years ago @onnokort You mean like the i2c-gpio overlay present in current kernels since Nov 2015? https://github.com/raspberrypi/linux/blob/rpi-4.4.y/arch/arm/boot/dts/overlays/i2c-gpio-overlay.dts From the README for overlays:
Name: i2c-gpio
Info: Adds support for software i2c controller on gpio pins
Load: dtoverlay=i2c-gpio,<param>=<val>
Params: i2c_gpio_sda GPIO used for I2C data (default "23")
i2c_gpio_scl GPIO used for I2C clock (default "24")
i2c_gpio_delay_us Clock delay in microseconds
(default "2" = ~100kHz)@6by9: Awesome, thanks, I learned something new today. I didn't test this yet, but, yes, this looks exactly what I was looking for (and found in i2c-gpio-param).
JamesH65
commented
7 years ago @popcornmix @6by9 Can this be closed? Been around a looong time, and the dt param stuff from my reading seems to be a decent option.
P33M
commented
7 years ago The recommended workaround for devices that definitely do not play well with our I2C hardware is to use the i2c-gpio overlay, which bitbashes pins.
Otherwise, clock stretching in the address ACK phase is supported by the upstream driver.
{kind=link}
The broadcom BCM2835 has a (hardware) bug in the I2C module.
The BCM implements "clock stretching" in a bad way:
Instead of ensuring a minimum "hightime" for the clock, the BCM lets the I2C clock internally run on, and when it's time to flip the clock again, it checks wether or not the clock has become high, and if it is low, it does a "clock stretch". However if just in the few nanoseconds before this check the slave releases the clock signal indicating it is ready for a new clock, the clock pulse may become as short as 40ns. (that's the lowest I'm able to measure, and that of course is quite rare). With a 100kHz (10 microseconds) I2C clock, the "bad" moments to release the clock are 5 microseconds apart.
My slaves require a clock pulse of at least 500ns. (which should be a factor of ten shorter than what the master should generate when it is configured for 100kHz operation).
That is a hardware bug that we can't do much about at the moment. ( Tip for the hardware guys: instead of implementing clock stretching in this way: inhibit the counting of the CLOCKDIV counter while the clock remains low. This will probably clock-stretch a few fast-clocks on every cycle, but standards conformance will improve substantially).
When this occurs, the BCM will send a byte, with a very short first clock pulse. The slave then doesn't see the first clock pulse, so when at the end of that byte it is time to ACK that byte, the slave is still waiting for the 8th bit. The BCM interprets this as a "NAK" and aborts the I2C transfer. However at that point in time the slave sees its 8th clock pulse and issues an "ACK" (Pulls the SDA line low). This in turn means that the BCM cannot issue a proper "START" condition for the next transfer.
Suggested software workaround to reduce the impact of this hardware bug: When a transfer is aborted due to a "NAK" for a byte, issue a single extra clock cycle before the STOP to synchronize the slave. This probably has to be done in software.
This only happens in the "error path" when the slave doesn't ACK a byte. Maybe it's best to only do this when it is NOT the first byte in a transfer, as the bug cannot happen on the first byte of a transfer.
Does this software fix belong in the driver? Yes. It's a driver for a piece of hardware that has a bug. It is the duty of the driver to make this buggy hardware work the best it can.