 fenn
commented
7 months ago
fenn
commented
7 months ago these numbers seem way off. it's time to get out the napkin!
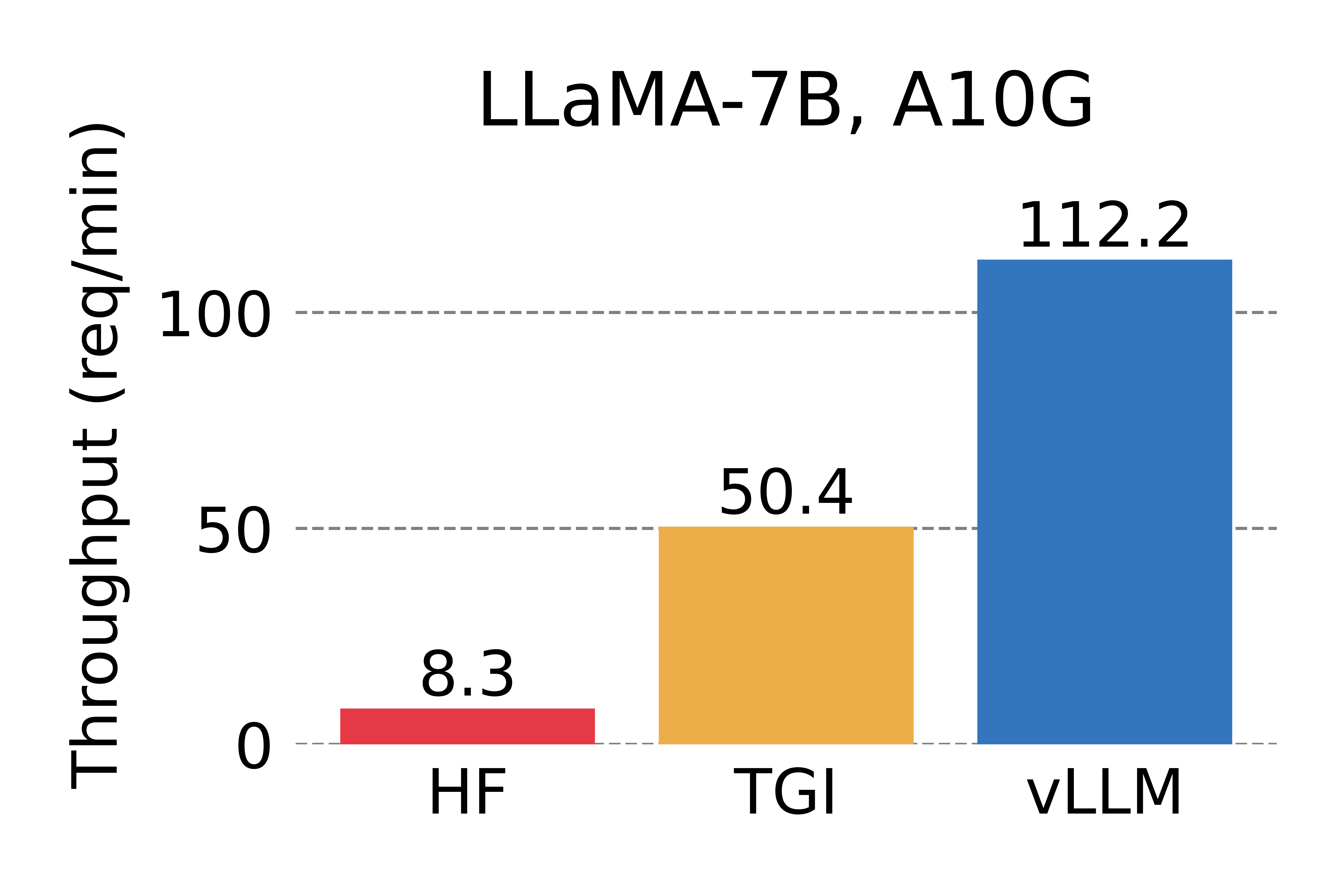
an iphone 15 battery holds 13 Wh per full charge, and it will take ~15 Wh to charge it fully. vLLM can generate 1900 token/s on a single A100 GPU which uses less than 400W, or 0.0585 mWh/token. even for a 512 token response (this is a very long response) that's only 0.03 Wh per request. vLLM authors present the throughput with real world usage data as 112 requests/min on an A10g which uses less than 150W, which works out to 0.02 Wh per request or > 600 requests per phone charge equivalent. (this is $0.00001 / request or 100,000 requests/dollar in electricity costs, even at bloated hawaii electricity prices!)
{kind=link}
the energy usage will be proportionally higher for larger model size, and also for smaller batch sizes, but not 1000x larger. at least, not until you get into really big models like GPT-4, with really long contexts, but those models are often located in large datacenters that use hydroelectric or wind power, so it gets more complicated to calculate the CO2 equivalent. the most impactful thing you can do for reducing energy consumption is to use larger batch sizes on newer chips, and after that try to use smaller models and context lengths.
The number provided are in terms of memory usage. It would be nice to provide numbers in terms of energy consumptions. That is current number shows that an LLM inference can costs twice the energy used for a phone charge.
See: https://www.kaggle.com/code/lucasmorin/mistral-7-b-instruct-electricity-co2-consumption
I get:
Hardware | Energy consumed (Wh) -- | -- GPU T4x2 | 6.2 GPU P100 | not supported TPU VM v3-8 | 8.8for mistral inference. While the last iphone charge energy consumption is considered 3Wh.