 mvindiola1
commented
3 years ago
mvindiola1
commented
3 years ago Hi @rfali,
If by gamma you mean the reward discount factor I do not think you can change that just using a model. You will also need to update the loss function. This is where the DQN loss function is computing the n_step discount factor. https://github.com/ray-project/ray/blob/1d834bcbe33c7714913fa06c7a7392c29eb7d71d/rllib/agents/dqn/dqn_tf_policy.py#L98.
The specific error you are getting is because you are returning a list of tensors and not a tensor for q_values. You need a q_values = tf.keras.layers.Concatenate()[q_values].
 rfali
rfali

 stale[bot]
stale[bot]
Hi,
I had posted my question 8 days ago on ray discourse [here] but didn't hear back. So I am opening an issue here, as I am getting errors on my custom model and I am not sure what is wrong (can I get some help @sven1977?)
I want to customize RLLib's DQN in a way that it outputs n (let's say 10) number of Q-values where each Q-value uses a different discount factor gamma that is also passed as an input argument. I am trying to implement an architecture from this paper which is shown on page 14 Figure 9. I have 2 questions:
Can I can try to define a CustomModel class using this RLlib example code which could implement this architecture? Is this doable in a way that it does not mess up with the rest of RLlib (which I am trying to learn and am no expert). I want to use a TF model. My Custom Model and its summary is appended at the end.
What will happen to the config [gamma] as I don't want to implement a fixed gamma value (which can be passed to RLlib algorithms), rather I want to pass a list of gammas when the neural network is created? I am not sure how the config [gamma] will behave in this case?
Here is the model I made based on Custom DQN Model example
Here is how I am trying to confirm the model output
Here is the model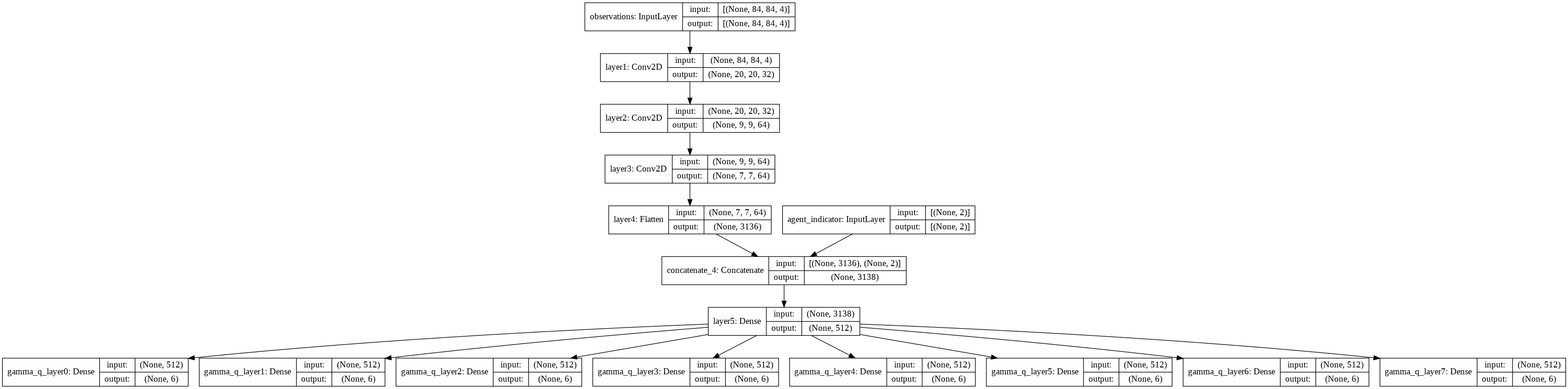
The tensor error is as follows if i use
layer_outValueError: Output is not a tensor: [[<tf.Tensor 'policy_0/model_2/gamma_q_layer0/BiasAdd:0' shape=(?, 256) dtype=float32>, <tf.Tensor 'policy_0/model_2/gamma_q_layer1/BiasAdd:0' shape=(?, 256) dtype=float32>, <tf.Tensor 'policy_0/model_2/gamma_q_layer2/BiasAdd:0' shape=(?, 256) dtype=float32>], <tf.Tensor 'policy_0/model_2/tf_op_layer_policy_0/add_2/policy_0/add_2:0' shape=(?, 256) dtype=float32>]If it helps. I am trying to recreate this code from here into RLlib.
Can anyone please guide? Thanks
p.s the 2 util functions are from here