 qtxie
commented
2 years ago
qtxie
commented
2 years ago At least up to 4 words (but maybe even up to 8-16), I see no reason why object needs a hash table. Just scan all words linearly, and it will likely be faster than hash lookup.
It's faster only if the number of words is small. The global context can easily contain millions of words, which causes a big issue in some real world Apps. We used linear search in the original implementation. Some users reported super slow startup time in their apps, then we change it to use a hashtable.
 hiiamboris
hiiamboris
One would expect object size (in memory) to be
x + ynwherenis the number of words. Especially since object cannot be extended, so there's no reason to allocate more than needed.My measurements however show the following: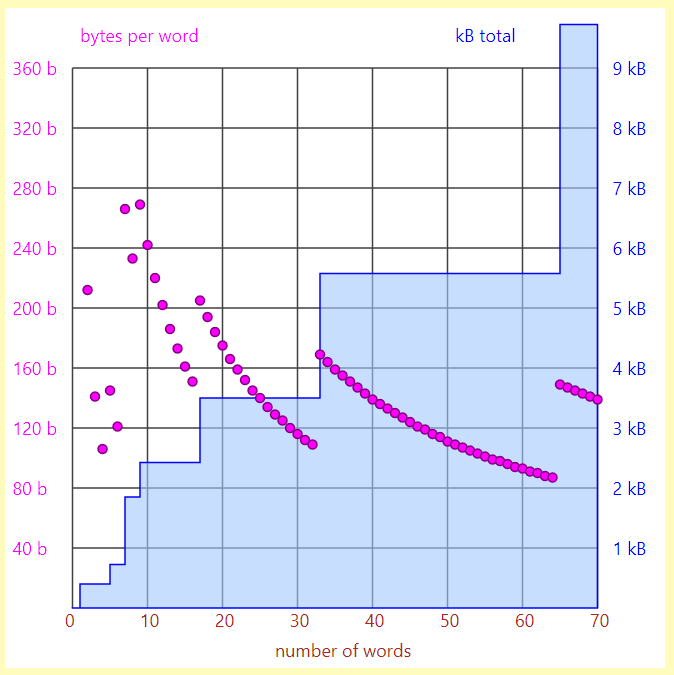 (obtained using this tool)
(1-word object point is not visible as 424 bytes per word doesn't fit the plot; visible points start at 2)
(obtained using this tool)
(1-word object point is not visible as 424 bytes per word doesn't fit the plot; visible points start at 2)
My math may not take into account some implementation details, please correct me where I'm wrong:
We should consider RAM usage when we switch to 64 bits. 24 bytes or 300 bytes per word is a huge difference now and will likely double.