 dockimbel
commented
1 year ago
dockimbel
commented
1 year ago It seems to me that 4. and 5. (or variations of those) are the only viable options for typed objects.
Open dockimbel opened 1 year ago
dockimbel
commented
1 year ago It seems to me that 4. and 5. (or variations of those) are the only viable options for typed objects.
 greggirwin
commented
1 year ago
greggirwin
commented
1 year ago On functions, it seems confusing and dangerous to be able to spec a local type but not have it enforced (if the new attribute is not used). Confusing because it's not consistent with arg type checking. Dangerous because you can spec types, thinking it will protect you, but forget the attribute. Something a static analyzer could catch, once we have one.
Will it not work to always use strict typing, but if a type is not spec'd it allows any-type!?
dockimbel
commented
1 year ago Will it not work to always use strict typing, but if a type is not spec'd it allows any-type!?
That implies that the type-checking on word setting inside the body is always active. That is a big departure from current language semantics. I don't think we should go that far. That is why I proposed an attribute to explicitly switch to the stricter semantics.
greggirwin
commented
1 year ago While it would be a technical departure, are there practical downsides? Certainly adding a local type check on something like inner loops needs to be profiled.
With a flag, do we also end up with two func interpreters and code generators?
But perhaps we go even a step further, and add support for something like dependent types in a new func constructor, which is always strict. Though that, like instrumentation, crosses the line into evaluation and modifying the body.
greggirwin
commented
1 year ago It's also interesting to think about this as interface vs implementation WRT specs in general.
greggirwin
commented
1 year ago Thanks for writing up the object pros and cons. Option 5 seems best, as my gut reaction. Largely because specs are data. The focus right now is on how objects can support this efficiently, in the context (no pun intended) of apply changes. As you note, it can apply to structs as well, and there are open dynamic questions. So let's think about the big picture. What is a spec, and how is it used?
Zoom out a bit and you see maps and blocks as relatives of objects and structs. And if you have a typed-compound-arg in a func spec? You mentioned serialization, which leads to datastores and messaging. Ultimately, we have data and want to ensure/guarantee (ask, enforce) that it matches a spec.
That may not always be efficient, but it is necessary.
If we look at it that way, is any option other than 5 viable, whether or not it's a prototype object or helper model (thinking again about constrained/dependent* types)?
*I don't like "dependent types" as a name.
 qtxie
commented
1 year ago
qtxie
commented
1 year ago On functions, I prefer to do the type checking when the local words be typed. The current behavior is confusing.
On objects, I like option 4. On option 5, I feels like it just moves the spec block in option 4 outside. But for a full class-based model we need something like 5.
dockimbel
commented
1 year ago While it would be a technical departure, are there practical downsides?
I think you missed the fact that the "type-checking on word setting" applies equally on all words from the function's spec block, including arguments words. The "arguments" vs "locals" words is only a convention in Redbol, there's nothing that distinguishes them in the body block nor in the internal context tables. So if we were to flip the switch and activate the "type-checking on word setting" feature in Red, lots of existing code (probably most of it) will just stop working.
With a flag, do we also end up with two func interpreters and code generators?
The "type-checking on word setting" is not a feature of the interpreter (no change is needed in the interpreter for that), it would be a deep feature of words setting only. I'm not sure what you mean by "code generators" in such context.
But perhaps we go even a step further, and add support for something like dependent types in a new func constructor, which is always strict.
You can already implement a form of dependent types at runtime using object events. You could create a new function spec syntax that the function constructor would convert into an object with generated object event handlers. Though, the performance overhead could quickly become unbearable in loops.
As a matter of comparison, the simple type-checking feature I'm proposing can be implemented in 3-4 extra lines of R/S code in _context/set-in function.
dockimbel
commented
1 year ago On functions, I prefer to do the type checking when the local words be typed. The current behavior is confusing.
I'm not sure what you mean by "when the local words be typed". Only argument words are type-checked on the function's call. With typed functions, all words (both arguments and local words) would be type-checked each time they are set to a new value in the function's body.
dockimbel
commented
1 year ago Zoom out a bit and you see maps and blocks as relatives of objects and structs. And if you have a typed-compound-arg in a func spec? You mentioned serialization, which leads to datastores and messaging. Ultimately, we have data and want to ensure/guarantee (ask, enforce) that it matches a spec. That may not always be efficient, but it is necessary.
If you are thinking about DbC, then we can probably find ways to support it, even if it seems to me that it has been superseded by simple assertions (using assert) in most languages by now. If you are thinking "dependent types", which imply a run-time checking on each word setting, then that does not seem viable performance-wise. I'm not aware of any language supporting dependent types that is not statically analyzable, allowing a compiler to do the heavy lifting.
qtxie
commented
1 year ago Can the interpreter detect typed local words before execute the function body, so it can switch to strict mode automatically?
dockimbel
commented
1 year ago Sure, it can, but that will trigger also strict type-checking on argument words setting too. Better make it explicit using an attribute, so that the intention is clearly stated.
 hiiamboris
commented
1 year ago
hiiamboris
commented
1 year ago On functions.
My opinion seems to contrast with others, but I don't find this feature useful. The point for me is to enforce validity of data exchange between two points in the code separated both by space (LOC) and time (which is more important). In other words, I want the luxury of making a mistake, forgetting what was written a year ago, and letting the language make me fix it. But in a scope of a single function's body this looks just paranoid to enforce. After all if I'm looking at a function definition, I'm seeing the whole context (spec and evaluation logic), and should be able to trust my judgement to assign things.
Much better validation point here would be some ways to avoid accidentally adding new set-words to a func body or accidentally referring to an external word with a set-word in a function body. This is a real pain point. But I don't know how this could work.
hiiamboris
commented
1 year ago On readability.
I'll make a little effort to completely disqualify contenders 1 and 2 and also compare the others on real code.
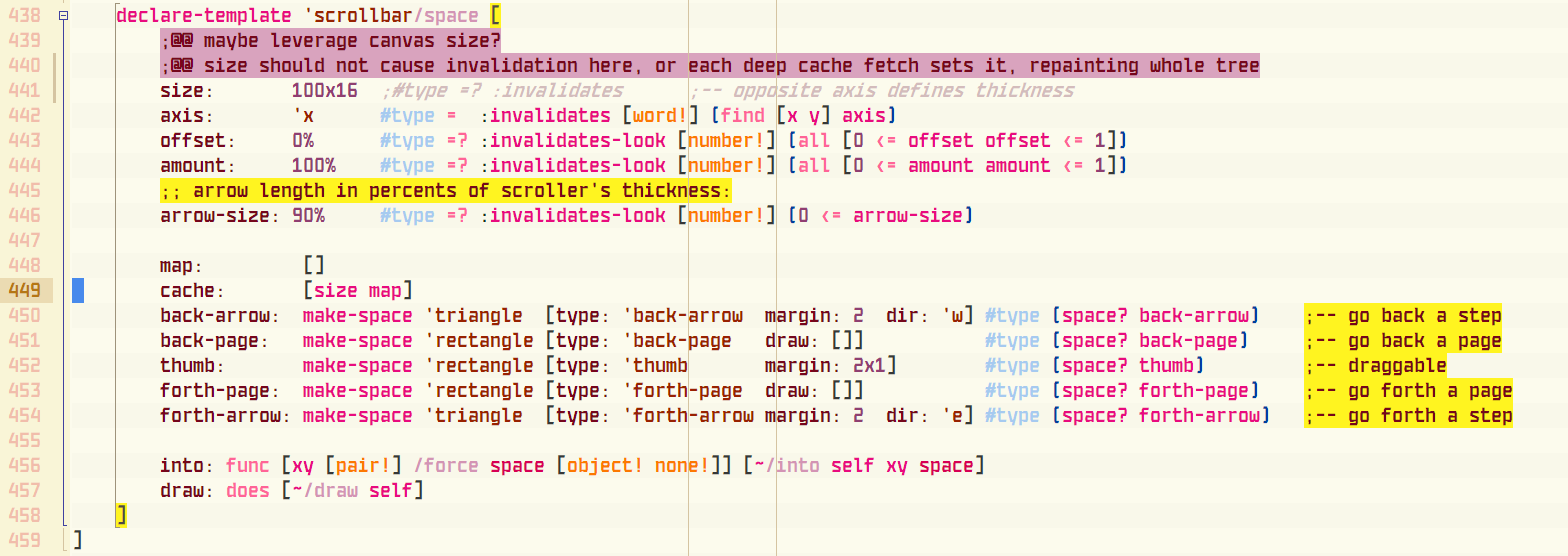
Taking as an example a scrollable template from Spaces. For the reference, this is how it originally looks like with syntax highlighting:
If you're worried that my type spec is too long and is more than a typespec, I can counter it:
Now let's compare:
1a. Prefixed (variant 1)
Note how untyped words migrated to the far right, for visual alignment.
declare-template 'scrollbar/space [
size: 100x16 ;-- opposite axis defines thickness
#type = :invalidates [word!] (find [x y] axis) axis: 'x
#type =? :invalidates-look [number!] (all [0 <= offset offset <= 1]) offset: 0%
#type =? :invalidates-look [number!] (all [0 <= amount amount <= 1]) amount: 100%
#type =? :invalidates-look [number!] (0 <= arrow-size) arrow-size: 90%
map: []
cache: [size map]
#type (space? back-arrow) back-arrow: make-space 'triangle [type: 'back-arrow margin: 2 dir: 'w] ;-- go back a step
#type (space? back-page) back-page: make-space 'rectangle [type: 'back-page draw: []] ;-- go back a page
#type (space? thumb) thumb: make-space 'rectangle [type: 'thumb margin: 2x1] ;-- draggable
#type (space? forth-page) forth-page: make-space 'rectangle [type: 'forth-page draw: []] ;-- go forth a page
#type (space? forth-arrow) forth-arrow: make-space 'triangle [type: 'forth-arrow margin: 2 dir: 'e] ;-- go forth a step
into: func [xy [pair!] /force space [object! none!]] [~/into self xy space]
draw: does [~/draw self]
]1b. Prefixed (variant 2, I actually started with this)
Note how this almost triples the number of lines of code, otherwise it's hard to visually tell whether typecheck belongs to the upper or lower word (and still would double the LOCs).
declare-template 'scrollbar/space [
size: 100x16 ;-- opposite axis defines thickness
#type = :invalidates [word!] (find [x y] axis)
axis: 'x
#type =? :invalidates-look [number!] (all [0 <= offset offset <= 1])
offset: 0%
#type =? :invalidates-look [number!] (all [0 <= amount amount <= 1])
amount: 100%
#type =? :invalidates-look [number!] (0 <= arrow-size)
arrow-size: 90%
map: []
cache: [size map]
#type (space? back-arrow)
back-arrow: make-space 'triangle [type: 'back-arrow margin: 2 dir: 'w] ;-- go back a step
#type (space? back-page)
back-page: make-space 'rectangle [type: 'back-page draw: []] ;-- go back a page
#type (space? thumb)
thumb: make-space 'rectangle [type: 'thumb margin: 2x1] ;-- draggable
#type (space? forth-page)
forth-page: make-space 'rectangle [type: 'forth-page draw: []] ;-- go forth a page
#type (space? forth-arrow)
forth-arrow: make-space 'triangle [type: 'forth-arrow margin: 2 dir: 'e] ;-- go forth a step
into: func [xy [pair!] /force space [object! none!]] [~/into self xy space]
draw: does [~/draw self]
]2. Infixed
This one becomes total mess.
declare-template 'scrollbar/space [
size: 100x16 ;-- opposite axis defines thickness
axis: #type = :invalidates [word!] (find [x y] axis) 'x
offset: #type =? :invalidates-look [number!] (all [0 <= offset offset <= 1]) 0%
amount: #type =? :invalidates-look [number!] (all [0 <= amount amount <= 1]) 100%
arrow-size: #type =? :invalidates-look [number!] (0 <= arrow-size) 90%
map: []
cache: [size map]
back-arrow: #type (space? back-arrow) make-space 'triangle [type: 'back-arrow margin: 2 dir: 'w] ;-- go back a step
back-page: #type (space? back-page) make-space 'rectangle [type: 'back-page draw: []] ;-- go back a page
thumb: #type (space? thumb) make-space 'rectangle [type: 'thumb margin: 2x1] ;-- draggable
forth-page: #type (space? forth-page) make-space 'rectangle [type: 'forth-page draw: []] ;-- go forth a page
forth-arrow: #type (space? forth-arrow) make-space 'triangle [type: 'forth-arrow margin: 2 dir: 'e] ;-- go forth a step
into: func [xy [pair!] /force space [object! none!]] [~/into self xy space]
draw: does [~/draw self]
]3. Postfix (original implementation)
Basically type spec here is almost like a comment, and so stays on the right where it's easy to discard it visually until it's needed. In fact, with the type spec introduction I just replaced all comments that described what value constraints are with the actual constraints.
In my implementation there's actually no distinction between infix and postfix: it just applies #type spec to the last set-word found. But I always format is as postfix.
declare-template 'scrollbar/space [
size: 100x16 ;-- opposite axis defines thickness
axis: 'x #type = :invalidates [word!] (find [x y] axis)
offset: 0% #type =? :invalidates-look [number!] (all [0 <= offset offset <= 1])
amount: 100% #type =? :invalidates-look [number!] (all [0 <= amount amount <= 1])
arrow-size: 90% #type =? :invalidates-look [number!] (0 <= arrow-size)
map: []
cache: [size map]
back-arrow: make-space 'triangle [type: 'back-arrow margin: 2 dir: 'w] #type (space? back-arrow) ;-- go back a step
back-page: make-space 'rectangle [type: 'back-page draw: []] #type (space? back-page) ;-- go back a page
thumb: make-space 'rectangle [type: 'thumb margin: 2x1] #type (space? thumb) ;-- draggable
forth-page: make-space 'rectangle [type: 'forth-page draw: []] #type (space? forth-page) ;-- go forth a page
forth-arrow: make-space 'triangle [type: 'forth-arrow margin: 2 dir: 'e] #type (space? forth-arrow) ;-- go forth a step
into: func [xy [pair!] /force space [object! none!]] [~/into self xy space]
draw: does [~/draw self]
]4. Separate spec block
The problem for me here is to figure out what is specced, and what isn't. Considering that some words are specced in the parent template and are just inherited, it becomes even harder. Plus code bloat. Though overall it's readable.
declare-template 'scrollbar/space [
[
axis: = :invalidates [word!] (find [x y] axis)
offset: =? :invalidates-look [number!] (all [0 <= offset offset <= 1])
amount: =? :invalidates-look [number!] (all [0 <= amount amount <= 1])
arrow-size: =? :invalidates-look [number!] (0 <= arrow-size)
back-arrow: (space? back-arrow)
back-page: (space? back-page)
thumb: (space? thumb)
forth-page: (space? forth-page)
forth-arrow: (space? forth-arrow)
]
size: 100x16 ;-- opposite axis defines thickness
axis: 'x
offset: 0%
amount: 100%
arrow-size: 90%
map: []
cache: [size map]
back-arrow: make-space 'triangle [type: 'back-arrow margin: 2 dir: 'w] ;-- go back a step
back-page: make-space 'rectangle [type: 'back-page draw: []] ;-- go back a page
thumb: make-space 'rectangle [type: 'thumb margin: 2x1] ;-- draggable
forth-page: make-space 'rectangle [type: 'forth-page draw: []] ;-- go forth a page
forth-arrow: make-space 'triangle [type: 'forth-arrow margin: 2 dir: 'e] ;-- go forth a step
into: func [xy [pair!] /force space [object! none!]] [~/into self xy space]
draw: does [~/draw self]
]5. Prototype
This is the worst of options in my opinion. I have enough experience with C++ to tell that it was a HUGE mistake to separate spec and implementation. But in C++ you at least get compiler to warn you you forgot to sync these lists, which is not an option for us. Basically it's as bad as keeping assertions in a separate file: they are always out of sync. D dudes decided to fix that even for a compiled lang, so let's learn from them.
some-prototype-name: declare [
axis: = :invalidates [word!] (find [x y] axis)
offset: =? :invalidates-look [number!] (all [0 <= offset offset <= 1])
amount: =? :invalidates-look [number!] (all [0 <= amount amount <= 1])
arrow-size: =? :invalidates-look [number!] (0 <= arrow-size)
back-arrow: (space? back-arrow)
back-page: (space? back-page)
thumb: (space? thumb)
forth-page: (space? forth-page)
forth-arrow: (space? forth-arrow)
]
declare-template 'scrollbar/space some-prototype-name [
size: 100x16 ;-- opposite axis defines thickness
axis: 'x
offset: 0%
amount: 100%
arrow-size: 90%
map: []
cache: [size map]
back-arrow: make-space 'triangle [type: 'back-arrow margin: 2 dir: 'w] ;-- go back a step
back-page: make-space 'rectangle [type: 'back-page draw: []] ;-- go back a page
thumb: make-space 'rectangle [type: 'thumb margin: 2x1] ;-- draggable
forth-page: make-space 'rectangle [type: 'forth-page draw: []] ;-- go forth a page
forth-arrow: make-space 'triangle [type: 'forth-arrow margin: 2 dir: 'e] ;-- go forth a step
into: func [xy [pair!] /force space [object! none!]] [~/into self xy space]
draw: does [~/draw self]
]Thanks for clarifying @dockimbel. I agree that a lot of code may break for args that have types, but are used flexibly inside the func. Given how often that feature is used, strong types/weak vars, it's a huge change. The main value I see in it, per @hiiamboris ' points, is in marketing as a stricter language for those who want that. But it may also lead to what we consider less idiomatic Red code. The real question, though, is whether it will make things better overall, and improve software. It could also be confusing (contexts trip people up because other langs don't have them), if you expect things to be strict, but don't understand that's not enforced outside the body of the function, or if a typed word is passed to a sub-func.
I can't think of many times Red's flexibility here has bitten me. No horror stories come to mind.
Since asserts came up, that's another place a spec system can be used. Check things when and where you need, triggering an error if things go out of spec.
What about doing it experimentally, so we and the community can play? Go with [strict] and see what it's like to work with. But make it clear it may go away in a month if it doesn't pan out.
Now to make time to read Boris' message. :^)
greggirwin
commented
1 year ago Mostly code examples made it clear and easy reading. Thanks @hiiamboris.
Another key point about this, since C++ came up, is whether these features are meant to make things easier for PitS, or do we envision people doing PitL in Red? For me, the latter means more systemic thinking, working in small pieces that talk to each other. C++ doesn't do that, as they care about low level performance quite heavily.
@dockimbel are you firm in making this part of standard object specs, rather than using helpers?
If we think about constraints, they are also something that should be something you can define and reuse. e.g. common cases might be non-negative numbers, or limits from 0-N. Note in Boris' examples that the name is used in the constraint. How do we omit that, but also allow other words to be ref'd.
offset: =? :invalidates-look [number!] (all [0 <= offset offset <= 1])
amount: =? :invalidates-look [number!] (all [0 <= amount amount <= 1])Could this be something like:
look-num: spec [limit [0 to 1 incl] [number!] :invalidates-look]
offset: =? look-num
amount: =? look-numI'll push back on the performance issue. Yes, it exists, but the goal is for the effect to be minimal if you don't use the feature. If you don't define constraints, you don't pay (much of) the price. As long as you can work around it for the most critical cases, it's a big win IMO, because Red is a language designed for communication. We get away with not spec'ing things a lot in Red now, because we're doing PitS. But I imaging we've all written code, or been bitten by bugs because we didn't, to vet a value. I know I have. And as soon as you manually check values, you pay the same price, right?
Languages, rightly, have moved toward safety and correctness as goals. At least some of them. I think that's a good thing, and we should try to do that in ways that fit Red when we can. There's a reason Clojure added spec, and that JSONSchema exists.
On separate specs vs inline, things can get out of sync. But we're not C++. If you make an object from a prototype, then add to it, that's OK. The proto doesn't need to sync. If you remove something from the proto, only you know if that's by design or not, and yes that can break things. But in the big picture, if we inline this for objects, the leveraging specs is lost everywhere else, right?
As an added note on funcs, should we think about default arg values while we're here? Not that they have to be in the spec, but how we set them in general. I think I'm OK with a simple, dialected deafult func, but am open to suggestions.
hiiamboris
commented
1 year ago #type or similar cue before/after every set-word is not viable in options 1 to 3:a: foo [integer!] b: barHow do we know foo is not a function that takes [integer!] argument? Same applies for postfix.
Or infix:
a: foo b: [integer!] bar How do we know if foo doesn't take b: and [integer!] arguments? Or maybe it's an op that takes a: and b:?
Plus this syntax cannot be extended (e.g. with on-change triggers).
What's faster - evaluation-transparent syntax that is evaluated on every object creation, or sophisticated syntax that is evaluated once before all such objects are created?
We use block prototypes (not objects) in View and Spaces. In my classy-object implementation, spec is only parsed once (on class declaration) and gets stripped of all the type info, which nearly zeroes any object construction overhead (except for series of on-change calls, but it's orthogonal).
Basically as long as we're able to split parse stage from actual object construction, all options are fine. Of course we can make wrappers on top of what Red does, but I'd prefer language do the best thing instead of requiring human to fix it.
Once we declare a typed object we need to be able to modify the spec before making a new object. If we separate parsing and creation stages, this modification is only possible by either naming the spec (something I've discovered we'd like to avoid), or keeping the link to the spec in the object and being able to access it using reflect (and modifying such spec copy).
In declare model, the initial object should normally have unset or none initial values for everything, but in most cases that will make it invalid from its own spec's perspective.
Shared syntax makes for less cognitive load.
declare model has two funcsIt looks like func [][] is evaluated both in the class and in the object in the OP.
To @qtxie and @greggirwin questions. Option 5 does not have to be the only way for a class-based system. In classy-object I derive both the class and the object from the same spec. Using reflect is another way. There are options here. I think we could have inlined spec being parsed into a refined spec.
mold/all should probably display the constraints, as it does with on-changeIf we separate the parsing stage, it may come to mold producing whole expressions, i.e. some call that parses the spec is then fed to make.
Does it have to be a new first-class serialization form if make object! is worthless without evaluation anyway?
This is not leveraged in Red yet, but use cases are different. I see "context" more like a "namespace" to impose structure on available functionality, as something unique, unlike "object" which is one of many. For "context" use case typing is unlikely beneficial, so it could work as dumber object without typing support.
- How to solve conflicting type definitions on multiple inheritance? (Should not happen in 5. as the proto object is the one providing the typing information.)
You mean when A and B are objects we then C: make A B? I don't recall ever using this. Probably we could just prioritize B as we would prioritize what comes in the block spec in place of B. Option 5 doesn't seem any different - if prototypes are objects, they should follow the same multiple inheritance rules.
I'm using single inheritance model, and override there is fine. For a real example I may have spacing generally defined as a pair or integer, but in a document I may force it to be integer-only, dropping pair support as it makes no sense. Cases like this pop up from time to time.
- Allow changing typesets on a given word? (Personally, I think the stricter the rule in typing, the simpler it is for end users.)
I don't remember ever wanting to modify the type spec of an existing template. Not to mention of existing objects. Let's disallow modification until there's a solid need.
- function! values should not need to be typed, though, a typed object could protect such word of function! type from being modified to a different datatype.
Something to consider is some kind of auto type locking. It's rather hard to implement as it's unclear how to detect the first assignment. Plus there's a can of worms: if I assign x in object A to a function and it locks it as a function, what if I want to redefine it to function or op in object B derived from A, and set it to an op? In object B it's not the first assignment anymore. This is also what complicates the notion of constant values and relates to (if I understood the question correctly):
- Should typed object also support a way to specify words protection from modification or should that be deferred to protect/unprotect functions?
I think the need for constant fields in the object is generally small, though if there's a way to later cheaply extend our design with protection, let's leave it for the future as an option.
General protect seems much more useful.
- How much the new typed object syntax needs to be back-compatible with untyped objects?
Fully IMO. Ideally so one could copy and paste the object into R2, dropping the type checks in the process but keeping it valid.
As an added note on funcs, should we think about default arg values while we're here? Not that they have to be in the spec, but how we set them in general. I think I'm OK with a simple, dialected
deafultfunc, but am open to suggestions.
By the way I mostly replaced it with advanced-function design, except in a few cases where default value is not immediately known at function entry, or where I my words are not function arguments but come from elsewhere.
Note in Boris' examples that the name is used in the constraint. How do we omit that, but also allow other words to be ref'd.
In that particular case - just using range datatype. But in general we can either agree on a standard word (x or value). Or use a unary function for value checks (but it will conflict with the on-change func). Also error message from a failed check should print out the checking code, which is trivial if it's a paren but harder with a function (as error messages are quite short).
But a drawback of not using a name is that it's easy to copy and paste another check accidentally and forget to modify it.
Also, I used this only in function value checks, but names make it possible to refer to other words. E.g. function [a [integer!] b [integer!] (b >= a)] [...]
 GiuseppeChillemi
commented
1 year ago
GiuseppeChillemi
commented
1 year ago Could type checking accept multiple types per word as [typed]] a [integer! float!] ?
Could you add a way to use an unary fuction as checker?
checker: func [val] [if val > 2 [true]]
f: func [a [:checker]] [] so one can do his own custom checking for values/objects and custom structures?
hiiamboris
commented
1 year ago
- Could the selected typed object syntax provide a clean way to support specifying object event handlers? (The current
on-change*/on-deep-change*convention has always been temporary until a better solution is found.)
A tangent: we are discussing this property setter, but do we plan to have getters as well?
To show an example of real pain points, suppose I'm designing a drop-down and among its sub-components it has: editable field and a dropping down list-view. Access to field text will be smth like drop-down-obj/spaces/field/text, that is inconvenient to use and is an internal detail, which may change.
I'd like to expose field's /text directly into drop-down, as drop-down-obj/text. I can make a macro (say #push) that creates an on-change handler that mirrors assignments of drop-down-obj/text into drop-down-obj/spaces/field/text.
Also let's imagine that field works similarly to the one in View: converts /data into /text and /text into /data. Same thing I can do to mirror drop-down-obj/data into drop-down-obj/spaces/field/data. So far so good.
But then user inputs some text into the field, and field internally replaces its /data facet, and now it's out of sync with drop-down-obj/data. As an author of the framework I know enough internals to anticipate this, create a new class for the field, and point on-change of field/data back into drop-down-obj/data.
My problems with this are:
I can't make drop-down-obj/text a function mirroring the field/text either, both because it won't be writeable, and because its result won't be as convenient (e.g. drop-down-obj/text/1 path access will fail).
What can be done?
drop-down-obj/text fully transparent link to the inner field/text(I realize 2-3 may open worse cans of worms)
greggirwin
commented
1 year ago Strong points: :+1:
Of course we can make wrappers on top of what Red does, but I'd prefer language do the best thing instead of requiring human to fix it.
Two different issues. We're fixing it now, then it's part of the language either way.
Q. How does construct work if specs aren't evaluated?
Q. What reflectors interact with constraints? spec-of makes sense and, since we don't use it yet, it's a good time to think of it in broad spec terms.
I agree with Boris' answers, except that R2 shouldn't be a consideration.
Access to field text will be smth like drop-down-obj/spaces/field/text, that is inconvenient to use and is an internal detail, which may change.
:+1: R2 VID's biggest pain may have been needing to know and interact with implementation details. The *-face accessors were meant to help with that.
Bear in mind that if we design this specifically for objects (which do have special features that add benefits. i.e. change detection), we still want a spec system for block, map, etc. They also have more overhead (https://github.com/red/red/wiki/%5BPROP%5D-Node!-datatype has great details).
There are also three types of limit behaviors to consider, which we may want to define: error, fail silently (do nothing), set to the nearest bound limit).
 planetsizecpu
commented
1 year ago
planetsizecpu
commented
1 year ago On 5.How much the new typed object syntax needs to be back-compatible with untyped objects? I would say 100%, it is not the soul of Redbol langs to be human-oriented and easy? so IMHO easy way must be first of all, if not, we are removing the sweetest sugar 😉
 pekr
commented
1 year ago
pekr
commented
1 year ago I am not surely the one who's opinion should matter, with this deep topic, but my preference is as follows:
I don't mind prefixed typing (1). I know, it is a reverse to function arguments, but prefer that visually instead of chasing types at the end of the line. Otoh, if some object attributes will not have any type defined, or will have multiple typed values, the visual aspect of readability will worsen. Let's not also forget, that at least in R2, the type value could be followed by the help string. Where do we place a help strings? Always at the end?
What do I prefer most, though, is a separate spec block (4), even though I know, that if might be a bit problematic to sync. I might try to provide another Pros:
So, just my two cents :-) /Petr
hiiamboris
commented
1 year ago Per-field docstring is actually an interesting idea. May just replace comments. External tooling (and help) then may provide insights into any object's behavior as it was meant by the object designer. On the other hand functions already have their docstrings and that will just add another docstring to any function in the object. And that's a big problem.
In multi-command command line interface, single object-wide docstring will be useful to describe the command.
greggirwin
commented
1 year ago R2 added a docs facet to VID faces. It was like option 4, except that it was just a named block value, not first in the spec. So it was nothing new as far as the language was concerned. Just a convention tools could leverage.
greggirwin
commented
1 year ago What is the default value of typed local words? We either need to allow none as a preset value, or provide a way to specify default values (can be tedious in practice)?
Something like opt as a keyword, perhaps? In thinking about specs in the past, a lot of value comes from leveraging parse as a model when describing data.
GiuseppeChillemi
commented
1 year ago About typed arguments in functions, I would like having the typed or strict flag for each argument as:
foo: func [a [typed integer!] b /local c [typed string!] d [integer!]][
a: none ; error!
c: 'hi ; error!
]
foo 1 27 ; type-checkAlso, it would be nice to have an one or 2 argument function as checker, where the first argument is always the passed value, you so you can write:
range-integer: func [
value [integer!]
range [block!]
/local
min
max
] [
set [min max] range
either all [value >= min value <= max] [true] [false]
]
foo: func [a [:range-integer [2 10]] b /local c [typed string!] d [integer!]][
a: 1 ; error!
c: 'hi ; error!
]
foo 1 27 ; type-checkThe same check function mechanism should be allowed for typed contexts
After the changes made in the
applybranch on red/red repo, it is now possible to add an array of typesets to Red contexts, so that additional type-checking can be enforced for datatypes relying on contexts. Such extra checks would help make Red code more robust when needed and ease debugging. Such extra typing is an optional feature, the current untyped versions are still allowed.Typed function contexts
Example:
That strict type-checking for argument words is not back-compatible with words setting semantics in "non-typed" functions. So, we would need to explicitly specify when we want type-checking on each set-word inside the function's body (including when words are set using
set, as long as they are bound to a typed function or typed object).Proposal: use
typedorstrictattribute to force type-checking on word setting.So without such attribute, usual word setting semantics is preserved (local words type spec in such case would be ignored):
The implementation cost for such feature is very low, as all word settings boil down to a call to
_context/set-infunction, which can be trivially extended to check the corresponding typeset.General questions
noneas a preset value, or provide a way to specify default values (can be tedious in practice)?Typed object contexts
The implementation cost is the same as for typed functions. Though, coming up with a clear, intuitive and minimal syntax is challenging. Here are several propositions:
In several of the propositions, we need a flag to mark the fact that the object needs to be processed for type information. Convention:
1. Prefixed inline type spec
Pros:
Cons:
2. Infixed inline type spec
Pros:
Cons:
#typeinside or outside each spec block.)3. Postfix inline type spec
Pros:
Cons:
name: foo 123 [string!], is it a spec block or an argument tofoo?). (Though, risks can be reduced by adding an extra marker, like#typeinside or outside each spec block.)4. Spec block as first value
Pros:
Cons:
5. Prototype typed object
Let's add a new
declareconstructor function that takes a typed object spec and returns an object value with all fields preset tonone(except for functions), ready to be used as a prototype for new typed objects. Internally, symbol and type arrays could be shared by default, as long as the context is not extended with new symbols.Pros:
Cons:
General questions
How to solve conflicting type definitions on multiple inheritance? (Should not happen in 5. as the proto object is the one providing the typing information.)
What is the default value of typed local words? We either need to allow
noneas a preset value, or provide a way to specify default values (can be tedious in practice)?Allow changing typesets on a given word? (Personally, I think the stricter the rule in typing, the simpler it is for end users.)
function!values should not need to be typed, though, a typed object could protect such word offunction!type from being modified to a different datatype.How much the new typed object syntax needs to be back-compatible with untyped objects?
Should typed object also support a way to specify words protection from modification or should that be deferred to
protect/unprotectfunctions?Could the selected typed object syntax provide a clean way to support specifying object event handlers? (The current
on-change*/on-deep-change*convention has always been temporary until a better solution is found.)References