 reveriel
commented
5 years ago
reveriel
commented
5 years ago 要求
- Python 2.7
- CUDA >= 7.0
- CuDNN == v4 (v5 is not compatible with our Theano fork)
folder:
cpp
python
scripts
writing有三个实现
- A Python/Theano implementation of SPINN using a naïve stack representation (named
fat-stack) - A Python/Theano implementation of SPINN using the
thin-stackrepresentation described in our paper - A C++/CUDA implementation of the SPINN feedforward, used for performance testing
代码中, 所有句子长度都 pad 到 seq_length = 30. 忽略长度大于 30 的句子, 论文中说最长长度设为 25 可以处理 SNLI 的 98% 的句子.
语法树
constituency-based trees, of constituency grammars, 将节点分为终结节点(叶子)和非终结节点(其他).
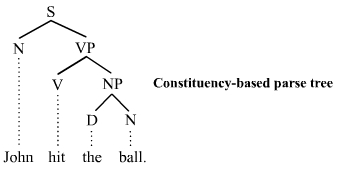
S 表示句子 sentence, NP : noun phrase, VP for verb phrase, V for verb, D for determiner, N for noun.
树中的节点可能是 root node, branch node, 或 leaf node. 如字面意义, 其中 branch 节点将两个或多个孩子节点相连.
dependecy-based parse tree, 根据的是 dependency grammars, 所有的节点都是终结节点.
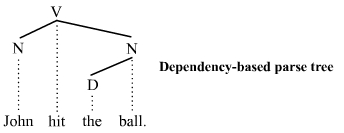
这种树相比constituency tree 缺少句子结构(S, VP, NP) 结构
对于consitituency based tree.
代码
python/spinn/models/fat_classifier.py
models -> { cbow, fat_stack, plain_rnn}
Theano 简介: Theano 静态的计算框架, 声明变量及其类型, 然后构建表达式, 最后编译表达式, 编译过程会对表达式的计算进行优化, 包括 GPU计算, 常量这点, 子图合并, 数值稳定性等.
关键函数, f = theano.function( [输入变量列表], [输出变量列表])
在 blocks.py 里, 实现的 TreeLSTM 是两个孩子的
gates = T.dot(l_h_prev, W_l) + T.dot(r_h_prev, W_r) + bshift reduce parser
parser 包含两个数据结构
- input buffer : 保存输入字符串
- stack, 保存计算中间结果, 在应用 production rules 会用到.
Shift 操作: 将符号从 input buffer 移动到 stack 中.
Reduce 操作: 对栈顶的数据进行操作, 从栈顶弹出 production rules 的操作数, 将结果压栈.
在编译中,
SR 格式
代码运行.
虚拟环境:
pip install -r python/requirements.txt运行 ./checkpoint/spinn.sh 出错:
The nvidia driver version installed with this OS does not give good results for reduction.Installing the nvidia driver available on the same download page as the cuda package will fix the problem: http://developer.nvidia.com/cuda-downloads
[INFO]: ERROR: Unable to load the kernel module 'nvidia.ko'. This happens most frequently when this kernel module was built against the wrong or improperly configured kernel sources, with a version of gcc that differs from the one used to build the target kernel, or if another driver, such as nouveau, is present and prevents the NVIDIA kernel module from obtaining ownership of the NVIDIA GPU(s), or no NVIDIA GPU installed in this system is supported by this NVIDIA Linux graphics driver release.
修改 /etc/modprobe.d/blacklist.conf, 加上
blacklist rivafb
blacklist vga16fb
blacklist nouveau
blacklist nvidiafb
blacklist rivatv
SPINN[2], which stands for Stack-augmented Parser-Interpreter Neural Network.
任务是将一对句子分成三类: 如果句1是一个没有见过的图片的准确描述, 那么句2 (a)definitely, (b)possibly (c)definitely not 是一个准确描述?说得这么绕,其实问两个句子说得是不是一件事。和 SICK 数据集里的一个任务一样的。
即,将两个句子的关系分为
例子:
看看这篇博客是怎么实现 Tree-LSTM 的。
我看不懂肯定是因为这篇博客[1]写得太烂了,直接看 SPINN[2] 的论文吧。
SPINN针对 树结构神经网络难以 batch 化的问题,提出 Stack-augmented Parser-Interpreter Neural Network, , which combines parsing and interpretation within a single tree-sequence hybrid model by integrating tree-structured sentence interpretation into the linear sequential structure of a shift-reduce parser。
基于 shift-reduce parsing。 从左到右读一个句子, 通过shift reduce 建立一棵树。
输入为两个list,
对于一个 N 个词的 binary-branching tree, 需要 2n-1 个transitions, 需要一个 stack 作为辅助空间。
遇到 shift 时将一个 token 压栈, 遇到 reduce 时将栈顶的两个 token 规约。
一个 tree 的结构编码在这个 transitions 数组中。这里称之为 SR 编码。 同一棵树只有一种 SR 编码。 例如
可以表示为 ((1 2) (3 4)),只有这一个表示方法。左括号表示 shift, 右括号表示 reduce
每次 reduce 即执行一次规约操作。
看一下更多的例子
本质上就是从左到右深度优先的顺序遍历树,离开节点的顺序。这叫做 Post-order。该顺序与按照节点深度的排序并不相同。
对于二叉树的 post-order 可以扩展到多叉树。在 Reduce 时需要记录 reduce 多少个节点。
表示为 S S S R3 S S R2 S S S S R4
内存开销,每个句子需要一个额外的栈,最大深度为句子长度。
batch 化的stack。
stack 是个tensor, b max_depth emb_dim
shift reduce parser:线性读取input tokens 序列和 transitions 序列,构建一棵树。
parser 使用两个辅助的数据结构: stack S, buffer B, 初始 stack 为空, buffer 放 input tokens。
transitions = shift | reduce
shift 语义: $\langle S, x \,|\, B\rangle \to \langle x \,|\, S,B\rangle$, 从 buffer 中取一个元素放到栈顶
reduce 语义: $\langle x \,|\, y \,|\, S, B\rangle \to \langle (x,y) \,|\, S,B\rangle $ , 从 stack pop 两个元素, merge后,把结果放在 stack 上。
SPINN 最后需要的不是一语法树,而是一个表示这棵树的向量,所以 merge 操作需要略修改一下。
$$\left[\begin{array}{c}{\vec{i}}\\ {\vec{f_l}}\\ {\vec{fr}}\\ {\vec{o}}\\ {\vec{g}}\end{array}\right]= \left[\begin{array}{c}{\sigma}\\ {\sigma}\\ {\sigma}\\ {\sigma}\\ {\tanh }\end{array}\right]\left(W{comp}\left[\begin{array}{c}\vec{h_s^1}\\ \vec{hs^2}\\ \vec{e} \end{array}\right]+\vec{b}{comp}\right) $$
$$\vec{c} = \vec{fl} \odot \vec{c}{s}^{2}+\overrightarrow{f_r} \odot \vec{c}_s^1 +\vec{i} \odot \vec{g}$$
$$\vec{h}=\vec{o} \odot \tanh (\vec{c})$$
$comp$ 表示 compose, $e$ 是当前节点的输入, 可选,本文在 e 这里输入的是另一个 LSTM 的输出。 这种写法类似 2-ary TreeLSTM。 另外让人怀疑, W参数是共享的吗,应该不是的。
初始化是这样的:
$$\left[\begin{array}{c}\vec{h}\\ \vec{c}\end{array}\right] = W{wd} \vec{x}{GloVe} + \vec{b}$$
直接词向量的仿射作为 h 和 c 初始值。
除了这个 composition 的计算之外,还有一个 tracking LSTM,这是一个sequence-based LSTMRNN, 每一步的输入是当前的 stack top 2 和 buffer 的top 1. Tree RNN 和 LSTM RNN 这两个网络的信息相互传递,形成一个有趣的整体。
通过这种方式,是一种将树形结构与线性结构相结合的混合模型,加上这个 tracking LSTM 能够提升效果也不令人奇怪,显然,用的信息会更多。 曾经看到过一个 graph NN,将语法树作为 Tree 计算,同时加上线性的句子。加上的线性句子也能对模型效果有提升。
然后本为对此也有相应的介绍: 自然语言中的歧义,哎,强行解释一番。
对 action 的预测, 使用一个softmax 层, 根据buffer 的 top one 和 stack 的 top two 进行预测一下操作是 shift还是 reduce, 相比外部的 parser 给出的结果会更不准确.
这个softmax 会通过学习外部 parser 进行训练. SNLI 是自带一个 parser : binary Stanford PCFG Parser.
实现上!考虑反向传播时的消耗。
一个 "naive" 的反向传播会把每一步的 stack 的值都保存. 实际上现有的框架做得怎么样呢? 这个是一个异常的消耗, 编程者可能在不知情的情况下写出十分耗内存的程序!
使用 think stack, 用一个$T \times D$ 的矩阵 $S$ 表示一个 stack . 每一行 $S[t]$ , $0 \lt t \le T$ 表示栈在时间步 t 的栈顶. push/shift 操作为吧一个元素放在 t, reduce 的话需要找到栈上的 top 2, 为此需要维护一个 queue 保存粘上还有效的数据的 indices.
这个 queue 在反向传播时又是怎样被求导的呢?
这个我在考虑到了, 计划是先实现了, 再注意让某些数据不要保存 gradient, 不知道可不可行. 这里给出了另一种方法.
一个 textual entailment 的更大的数据集, SNLI corpus, 有570K个人工标注的句子对
最后在未来的工作, 提到,用可微分的 push 和 pop 操作实现 SPINN, 可以使模型学会如何更好地 parse 句子
[1] https://devblogs.nvidia.com/recursive-neural-networks-pytorch/ [2] A Fast Unified Model for Parsing and Sentence Understanding, 2016, https://arxiv.org/abs/1603.06021