robert-w-gries
commented
6 years ago
robert-w-gries
commented
6 years ago Thanks @too-r! It looks like the PIT driver is working as intended.
Regarding the issue you saw, it looks like there were a few issues involving deadlocks in resched. The resched method will deadlock if any scheduling related locks are still held when it is called.
Problem 1: Incorrect locking of ready_list in resched
Debugging
I found out where the kernel is deadlocking by running gdb, hitting the deadlock, and running info stack
Call #2 in the stack is the culprit:
#2 0x000000000010cdb2 in rxinu::scheduling::cooperative_scheduler::{{impl}}::resched (
self=0x146538 <<rxinu::scheduling::SCHEDULER as core::ops::deref::Deref>::deref::__stability::LAZY+8>) at src/scheduling/cooperative_scheduler.rs:102It points to the following following block:
// skip expensive locks if possible
if self.ready_list.read().is_empty() {
return;
}Click to expand debugging output
``` (gdb) info stack #0 0x000000000012542b in core::sync::atomic::AtomicUsize::load ( self=0x146568 <Background
The reason that resched deadlocks when locks are held is that our context switch to a new process is an inner call in resched. Here's how the stack call looks when we run a new process:
new_process
rxinu::arch::context::switch_to
rxinu::scheduling::cooperative_scheduler::resched
rxinu::interrupts::irq::timer
rxinu::rust_mainNote that resched will always remain in the call stack until we get back to the null process.
The next question is "Why are locks held during the call to resched?" The way Rust implements locks is that they're held until drop is called on them. There are two ways to make sure drop is called for a lock: 1) Reach the end of the scope or 2) drop is manually called on the lock.
I debated whether to use solution 1) or 2) and ultimately decided to stick with solution 1). I reasoned that Rust as a language wants to limit manual management as much as possible. That's why Rust uses scoping and lifetimes by default. So I decided that rXinu will use scoping to free held locks.
Solution
So the issue is that I didn't properly scope the checking of the ready_list in resched. Because the ready_list lock is still active when we call context::switch_to, there will be a deadlock the next time we try to read from or write to ready_list.
Here's my fix:
- // skip expensive locks if possible
- if self.ready_list.read().is_empty() {
- return;
+ {
+ // skip expensive locks if possible
+ if self.ready_list.read().is_empty() {
+ return;
+ }Previously, we didn't run into this issue by chance. Thanks to your PIT driver, bugs in my scheduling code will be triggered more easily and can be fixed sooner!
Problem 2: Interrupting critical scheduling code
Now that we're using an irq handler to call resched, we need to ensure that the PIT irq handler doesn't invoke resched at incorrect times in our kernel.
Right now, important code, such as scheduling code using locks, can be interrupted. We need to disable interrupts while holding locks and re-enable interrupts when we are done.
My solution was to wrap the important scheduling components in the disable_interrupts_then function.
Problem 3: Resetting the PIT_TICKS value after resched
Currently, your PIT irq handler increments after every timer interrupt. It then checks to see if we've had 10 ticks, and if so we call resched.
The issue is that we need to reset PIT_TICKS to 0 after calling resched. Otherwise, PIT_TICKS will always be greater than 10 and we will call resched every clock tick.
diff --git a/src/arch/x86/interrupts/irq.rs b/src/arch/x86/interrupts/irq.rs
index 295108d..8d97885 100644
--- a/src/arch/x86/interrupts/irq.rs
+++ b/src/arch/x86/interrupts/irq.rs
@@ -18,12 +18,17 @@ fn trigger(irq: u8) {
}
pub extern "x86-interrupt" fn timer(_stack_frame: &mut ExceptionStack) {
+ use arch::x86::interrupts;
+
pic::MASTER.lock().ack();
if PIT_TICKS.fetch_add(1, Ordering::SeqCst) >= 10 {
+ PIT_TICKS.store(0, Ordering::SeqCst);
unsafe {
- SCHEDULER.resched();
- }
+ interrupts::disable_interrupts_then(|| {
+ SCHEDULER.resched();
+ });
+ }
}
} toor
toor
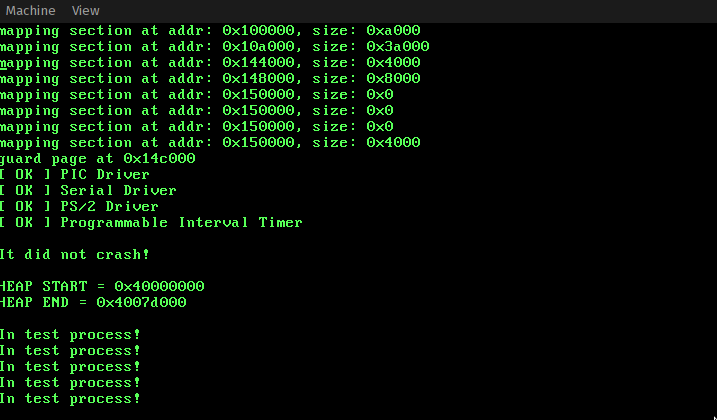
I have forked rxinu and implemented a basic PIT driver. The PIT, under this model, operates in Mode 3, using lobyte/hibyte configuration. I have experimented with moving the resched() call into the timer irq, and saw that a couple of test processes ran, printing to screen. However, after that it stopped, which is something I need to debug. Anyway, I thought you might like to check out my most recent few commits and give your opinion on the code so far.
Screenshot of rxinu running with the new model: