 rexlunae
commented
7 years ago
rexlunae
commented
7 years ago If we're going to have an x86-interrupt abi, would it also make sense to have an x86-syscall? Or x86-sysenter?
Open phil-opp opened 7 years ago
rexlunae
commented
7 years ago If we're going to have an x86-interrupt abi, would it also make sense to have an x86-syscall? Or x86-sysenter?
 phil-opp
commented
7 years ago
phil-opp
commented
7 years ago @kyrias Thanks for the hint, I updated the issue text. I'll try to create a backport PR in the next few days.
 steveklabnik
commented
5 years ago
steveklabnik
commented
5 years ago Triage: not aware of any movement stabilizing this.
Personal note: this is one of my favorite rust features :)
 kyrias
commented
5 years ago
kyrias
commented
5 years ago Both of the 64-bit issues have long since been fixed, and Rust's minimum LLVM is newer than the fix, so it's just the MMX/x87 floating point and 32-bit issues remaining, which appear to have been untouched since 2017.
phil-opp
commented
5 years ago @kyrias I updated the issue description. I also added https://github.com/rust-lang/rust/issues/57270, which will be hopefully fixed soon with the LLVM 9 upgrade.
 josephlr
commented
3 years ago
josephlr
commented
3 years ago @phil-opp I think this issue can be updated to cross off #57270
On the x87/MMX issue, we should just mandate that to use the interrupt ABI, you have to build the code with target-features of -x87 and -mmx (-mmx could be a default now that MMX support is gone from Rust). It looks like LLVM and GCC just never intend to support saving/restoring the MMX/x87 registers, so it's probably not worth trying to make it work (as nobody should be using those features anyway.
We may also want to similarly disallow all SSE code in interrupt handlers (GCC bans SSE code, Clang allows it), as that might make it easier to make sure we are doing the right thing.
phil-opp
commented
3 years ago @phil-opp I think this issue can be updated to cross off #57270
Done!
 mark-i-m
commented
3 years ago
mark-i-m
commented
3 years ago Just came across the following from a conference paper, and thought I would quote here as a data point:
We implement the low-level interrupt entry and exit code in assembly. While Rust provides support for the x86-interrupt function ABI (a way to write a Rust function that takes the x86 interrupt stack frame as an argument), in practice, it is not useful as we need the ability to interpose on the entry and exit from the interrupt, for example, to save all CPU registers.
(section 4.1 of https://www.usenix.org/system/files/osdi20-narayanan_vikram.pdf)
 repnop
commented
3 years ago
repnop
commented
3 years ago After discussing this on the Rust Community Server #os-dev channel with some folks (cc @Soveu @asquared31415), and checking out the LLVM patch that includes the ABI, it seems like taking the struct by-reference is incorrect and leads to undefined behavior (as seen in https://github.com/rust-osdev/x86_64/issues/240). This seems to have worked previously, but I suspect the upgrade to LLVM 12 may have "fixed" the behavior. (edit: asquared tested both 2021-03-03 and 2021-03-05 nightly releases, both by-value and by-ref work on the former, but by-ref breaks on the latter, which I think pretty much confirms the LLVM 12 upgrade fixed the behavior)
The patch to LLVM includes the following code, suggesting that the very first parameter should always be by-value and never by-reference.
if (F.getCallingConv() == CallingConv::X86_INTR) {
// IA Interrupt passes frame (1st parameter) by value in the stack.
if (Idx == 1)
Flags.setByVal();
} Soveu
commented
3 years ago
Soveu
commented
3 years ago By the way, if the function signature contains more than 2 arguments LLVM crashes with
LLVM ERROR: unsupported x86 interrupt prototype@repnop Thanks a lot for investigating this! I'll look into it and update the description of this issue if I can confirm that it works with a by-value parameter. Given that the Rust implementation just sets the LLVM calling convention, this shouldn't require any changes on the Rust side to fix it. We should adjust the x86_64 crate though.
To prevent issues like this (and wrong number of arguments errors), we should probably introduce some kind of lint that checks the function signature when the x86-interrupt calling convention is used. It's probably difficult to check the layout of the ExceptionStackFrame struct in detail, but verifying the number of parameters and the correct argument types (struct and optional u64) should be possible. I don't have any experience with creating lints though, so I'm not sure about the details.
Soveu
commented
3 years ago Also, we have found with @asquared31415 that using the second argument can cause stack corruption, because LLVM does not check if there is an error code and just pops unconditionally
 Andy-Python-Programmer
commented
3 years ago
Andy-Python-Programmer
commented
3 years ago I'll look into it and update the description of this issue if I can confirm that it works with a by-value parameter. Given that the Rust implementation just sets the LLVM calling convention, this shouldn't require any changes on the Rust side to fix it. We should adjust the x86_64 crate though.
It does work by-value parameter!
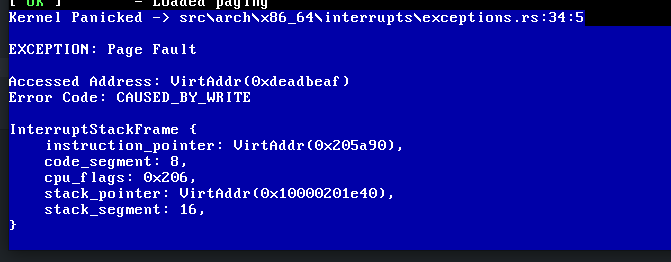 Everything now seems to be correct. Eg the stack segment is (16) => 0x10 which is valid
Everything now seems to be correct. Eg the stack segment is (16) => 0x10 which is valid
Thanks @repnop and @phil-opp!
Andy-Python-Programmer
commented
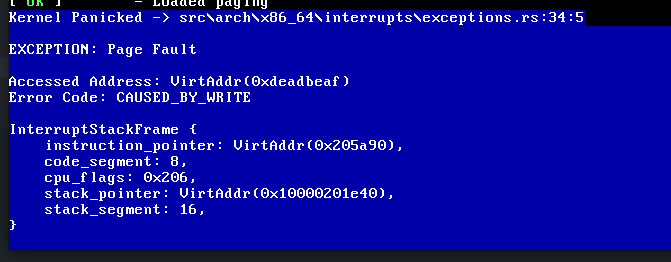
3 years ago Discovered something more:
As we are writing to 0xdeadbeaf the stack segment should be 0x00. For example this is a right interrupt stack:
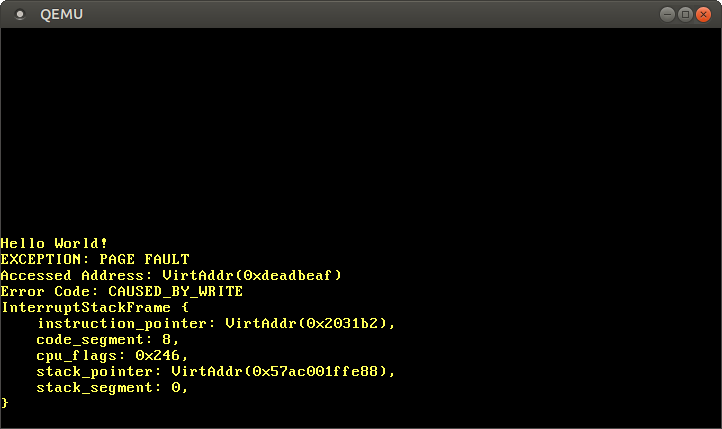 (Picture from OS Phillip's Blog)
As you can see the image below its 0x10.
(Picture from OS Phillip's Blog)
As you can see the image below its 0x10.
Soveu
commented
3 years ago Shouldn't 0x0 segment be null descriptor? (which iirc is invalid, stack segment should be a 64bit data segment)
 asquared31415
commented
3 years ago
asquared31415
commented
3 years ago On x86_64 architecture, the stack segment is supposed to be always forced to zero. Segmentation is almost entirely unused, in favor of paging.
Soveu
commented
3 years ago Yes, segmentation is mostly unused, but you have to have at least null, 64bit data and code segments
asquared31415
commented
3 years ago As per this wikipedia article, "Four of the segment registers, CS, SS, DS, and ES, are forced to 0, and the limit to 2^64". Additionally the AMD manual says that those segments are unused. It's curious that the cpu is reporting a non-zero value, however from testing their code in the community discord, everything seems to work, despite it seemingly being wrong. This was only tested on QEMU though, so perhaps that is an emulation fault.
Andy-Python-Programmer
commented
3 years ago As per this wikipedia article, "Four of the segment registers, CS, SS, DS, and ES, are forced to 0, and the limit to 2^64". Additionally the AMD manual says that those segments are unused. It's curious that the cpu is reporting a non-zero value, however from testing their code in the community discord, everything seems to work, despite it seemingly being wrong. This was only tested on QEMU though, so perhaps that is an emulation fault.
This is totally not a emulation fault as interrupt stack is perfect when in other languages.
Andy-Python-Programmer
commented
3 years ago (edit: asquared tested both 2021-03-03 and 2021-03-05 nightly releases, both by-value and by-ref work on the former, but by-ref breaks on the latter, which I think pretty much confirms the LLVM 12 upgrade fixed the behavior)
It still is UB in latest nightly and LLVM 12 by ref:
rustc 1.53.0-nightly (07e0e2ec2 2021-03-24)
binary: rustc
commit-hash: 07e0e2ec268c140e607e1ac7f49f145612d0f597
commit-date: 2021-03-24
host: x86_64-pc-windows-msvc
release: 1.53.0-nightly
LLVM version: 12.0.0I tried it myself and I can confirm that a by-ref parameter leads to invalid values and that a by-value parameter works. I updated the issue description accordingly.
I will also prepare a pull request for the x86_64 crate. One potential problem I noticed is that modifying the interrupt stack frame does no longer work reliably with the by-value parameter. It works in debug mode, but not in release mode. So I guess we should remove support for modifying it, at least for now. Edit: I opened https://github.com/rust-osdev/x86_64/pull/242.
Regarding the null segment descriptor: AFAIK it is allowed to have a null-segment descriptor for data segments, however only in kernel mode. For userspace mode, you still need to set up a proper data segment. There was some discussion about this in https://github.com/rust-osdev/x86_64/pull/78.
@Andy-Python-Programmer Judging from your code at https://github.com/Andy-Python-Programmer/aero/blob/713d34955152353b4240a4ef24cf5636ca4f2660/src/arch/x86_64/load_gdt.asm, it looks like you're loading 0x10 into ss, so the value is expected in your case. So this seems to be completely unrelated to the x86-interrupt calling convention.
Also, we have found with @asquared31415 that using the second argument can cause stack corruption, because LLVM does not check if there is an error code and just pops unconditionally
This is expected because there is unfortunately no good way to find out if there is an error code on the stack. So it's the obligation of the programmer to use the correct function signature for each IDT entry. There is no way to use an x86-interrupt function without unsafe (calling it directly is not allowed), so this does not break Rust's safety guarantees.
Soveu
commented
3 years ago This is expected because there is unfortunately no good way to find out if there is an error code on the stack
My hack around this:
InterruptInfo: error_code: u64 and has_error_code: u64has_error_code or push 0 two times to zero error_code and clean has_error_codeextern "x86-interrupt" code or save registers and then jump into code with different calling convention(I haven't tested it though)
test sp, 15
jz no_error_code
push 1
jmp continue_to_handler
no_error_code:
push 0
push 0
continue_to_handler:
// remember about `cld` as direction flag could be setOne potential problem I noticed is that modifying the interrupt stack frame does no longer work reliably with the by-value parameter. It works in debug mode, but not in release mode.
Using ptr::write_volatile does work to modify the interrupt stack. It's not a great way to do it though. Ideally code like
pub extern "x86-interrupt" fn handler(mut stack: InterruptStackFrame) {
stack.ip = 0;
}would work, however the compiler currently optimizes that write out. It would be best if the compiler could realize that modifying the interrupt stack frame does have an effect through the effect of iretq.
In the meantime this code works as expected to modify the stack frame
pub extern "x86-interrupt" fn handler(mut stack: InterruptStackFrame) {
unsafe {
addr_of_mut!(stack.ip).write_volatile(0x0);
}
}On the other hand, it is just consistent with other calling conventions, where changing preserved registers or return pointer is UB
phil-opp
commented
3 years ago @asquared31415 Good idea! I updated my x86_64 PR to use a volatile wrapper (and added a note about the potential unsafety).
asquared31415
commented
3 years ago While I agree that changing those things is normally UB, certain interrupt handlers, especially the debug interrupts, are expected to set some values in the pushed RFLAGS register (normally the resume flag) so that the state is right when it returns. This is the only case where changing saved state is expected that I can think of, so I don't know if there's precedent as to how to handle this.
 joshtriplett
commented
2 years ago
joshtriplett
commented
2 years ago We discussed this in today's @rust-lang/lang meeting.
We agree that this needs an RFC. Not specifically for x86-interrupt, but an "target-specific interrupt calling conventions" RFC. Once that RFC goes in, new target-specific interrupt calling conventions would just need a patch to the ABI section of the reference, ideally documenting the calling convention.
Would someone involved in this thread be up for writing that RFC?
@phil-opp Would you be willing to write that RFC?
We'd also appreciate an update to the API evolution RFC, to note that target-specific calling conventions are only as stable as the targets they're supported on; if we remove a target (for which we have guidelines and process in the target tier policy), removing its associated target-specific calling conventions is not a breaking change.
 mikeleany
commented
2 years ago
mikeleany
commented
2 years ago Also, we have found with @asquared31415 that using the second argument can cause stack corruption, because LLVM does not check if there is an error code and just pops unconditionally
This is expected because there is unfortunately no good way to find out if there is an error code on the stack. So it's the obligation of the programmer to use the correct function signature for each IDT entry. There is no way to use an
x86-interruptfunction withoutunsafe(calling it directly is not allowed), so this does not break Rust's safety guarantees.
I think this is a problem that needs to be solved before x86-interrupt can be stabilized. To give an idea of the severity of this issue, let's say a user-space program executes the instruction int 14 (which invokes the page fault exception handler). In this case no error code is pushed since it's just a software interrupt, not a real page fault. The problem is that the page fault exception handler is still expecting an error code, which isn't there, resulting in stack corruption, with everything off by 8 bytes.
As it stands currently, having an IDT entry directly reference an x86-interrupt function that takes an error code is unsound. You would instead need to use a trampoline function to work around the issue as in @Soveu's solution above.
josephlr
commented
2 years ago I think this is a problem that needs to be solved before
x86-interruptcan be stabilized. To give an idea of the severity of this issue, let's say a user-space program executes the instructionint 14(which invokes the page fault exception handler). In this case no error code is pushed since it's just a software interrupt, not a real page fault. The problem is that the page fault exception handler is still expecting an error code, which isn't there, resulting in stack corruption, with everything off by 8 bytes.
The problem described here is exactly why you must have DPL == 0 in any IDT entry for an exception (i.e. vectors 0 though 31). That way, a usermode process cannot corrupt the kernel stack or (more generally) trigger the kernel's interrupt handling code in unexpected ways. With this setup, if usermode executes int 14, you just get a #GP.
As it stands currently, having an IDT entry directly reference an
x86-interruptfunction that takes an error code is unsound. You would instead need to use a trampoline function to work around the issue as in @Soveu's solution above.
I don't think this is true. It's the calling code's responsibility to make sure that each interrupt handler invocation matches its function signature, including:
InterruptStackFrame having the correct size/alignmentWhile the calling convention doesn't provide these protections itself (as its just abound declaring functions), things like the x86_64 crate can help here. It's also worth noting that the "check sp alignment and conditionally push values" trampoline code linked above is not what Linux does. Based on the IDT vector, you should always know if an error code is present or not.
In short, I don't think any of the above issues should block stabilization. Of course, the LLVM crashes, error messages, and known issues probably need to be addressed before stabilization.
phil-opp
commented
2 years ago @joshtriplett Yes, I'm happy to work on this! I will create a rough draft and then open a pre-rfc thread on internals to discuss the details.
mikeleany
commented
2 years ago I think this is a problem that needs to be solved before
x86-interruptcan be stabilized. To give an idea of the severity of this issue, let's say a user-space program executes the instructionint 14(which invokes the page fault exception handler). In this case no error code is pushed since it's just a software interrupt, not a real page fault. The problem is that the page fault exception handler is still expecting an error code, which isn't there, resulting in stack corruption, with everything off by 8 bytes.The problem described here is exactly why you must have
DPL == 0in any IDT entry for an exception (i.e. vectors 0 though 31). That way, a usermode process cannot corrupt the kernel stack or (more generally) trigger the kernel's interrupt handling code in unexpected ways. With this setup, if usermode executesint 14, you just get a#GP.
Thank you for the correction. DPL == 0 does indeed prevent the issue of user-level code corrupting the kernel stack in this way.
In short, I don't think any of the above issues should block stabilization. Of course, the LLVM crashes, error messages, and known issues probably need to be addressed before stabilization.
Given that my concern about user-level code corrupting the kernel stack was incorrect, I agree.
josephlr
commented
2 years ago Should we change the bug references above to point to:
As the LLVM project has moved to GitHub Issues.
phil-opp
commented
2 years ago Should we change the bug references above to point to:
Thanks for the suggestion! I updated/added the references you mentioned.
phil-opp
commented
2 years ago I created a Pre-RFC for initial feedback at https://internals.rust-lang.org/t/pre-rfc-interrupt-calling-conventions/16182. Please let me know what you think!
 chorman0773
commented
2 years ago
chorman0773
commented
2 years ago Note: This is unsound on 32-bit x86 (Protected mode) if llvm expects the esp/ss field.
When the processor is in legacy mode, esp and ss are pushed by the interrupt (and popped by iret) only if the interrupt crosses privilege levels (gate.RPL<CPL for interrupt, retcs.RPL>CPL for iret)
Overview
Tracking issue for the
x86-interruptcalling convention, which was added in PR #39832. The feature gate name isabi_x86_interrupt. This feature will not be considered for stabilization without an RFC.The
x86-interruptcalling convention can be used for defining interrupt handlers on 32-bit and 64-bit x86 targets. The compiler then usesiretinstead ofretfor returning and ensures that all registers are restored to their original values.Usage
for interrupts and exceptions without error code and
for exceptions that push an error code (e.g., page faults or general protection faults). The programmer must ensure that the correct version is used for each interrupt.
For more details see the LLVM PR, and the corresponding proposal.
Known issues
ExceptionStackFrameis passed by reference (instead of by value). This used to work on older LLVM version, but no longer works on LLVM 12. See https://github.com/rust-lang/rust/issues/40180#issuecomment-814270159 for more details.64-bit
[x] The x86_64 automatically aligns the stack on a 16-byte boundary when an interrupts occurs in 64-bit mode. However, the CPU pushes an 8-byte error code for some exceptions, which destroys the 16-byte alignment. At the moment, LLVM doesn't handle this case correctly and always assumes a 16-byte alignment. This leads to alignment issues on targets with SSE support, since LLVM uses misaligned
movapsinstructions for saving thexmmregisters. This issue is tracked as bug 26413.A fix for this problem was submitted in D30049 and merged in rL299383.
[x] LLVM always tries to backup the
xmmregisters on 64-bit platforms even if the target doesn't support SSE. This leads to invalid opcode exceptions whenever an interrupt handler is invoked.The fix was merged to LLVM trunk in rL295347. Backported in rust-lang/llvm#63.
[ ] https://github.com/llvm/llvm-project/issues/41189
32-bit
[ ] In 32-bit mode, the CPU performs no stack alignment on interrupts. Thus, the interrupt handler should perform a dynamic stack alignment (i.e.
and esp, 16). However, LLVM doesn't do that at the moment, which might lead to alignment errors, especially for targets with SSE support. This issue is tracked in https://github.com/llvm/llvm-project/issues/26851.