 ehuss
commented
4 years ago
ehuss
commented
4 years ago FWIW, if you set codegen-units to 1 you should get the same result.
Open JoshMcguigan opened 4 years ago
ehuss
commented
4 years ago FWIW, if you set codegen-units to 1 you should get the same result.
 JoshMcguigan
commented
4 years ago
JoshMcguigan
commented
4 years ago FWIW, if you set codegen-units to 1 you should get the same result.
I added codegen-units = 1 under a [profile.release] heading in my Cargo.toml file. The result of this was both versions of the program performing the same. Unfortunately it caused a regression in the performance of the baseline program, so both versions take about 1270 ms with this compiler configuration.
 vojta7
commented
4 years ago
vojta7
commented
4 years ago Hi, I repeated your benchmark on my computer with same toolchain:
rustc 1.41.0 (5e1a79984 2020-01-27)
binary: rustc
commit-hash: 5e1a799842ba6ed4a57e91f7ab9435947482f7d8
commit-date: 2020-01-27
host: x86_64-unknown-linux-gnu
release: 1.41.0
LLVM version: 9.0and both programs behave exactly the same. I did also took look at generated assembly and the code is exactly the same ( minus the exported trait code, but this code is not used ), so I think you had just bad luck with the benchmark result.
JoshMcguigan
commented
4 years ago ..and both programs behave exactly the same.
Hmm, this performance differential is very repeatable on my machine. Just to ensure we are doing the same thing, I am comparing the following commands (running inside the repo linked in the issue description):
cargo run --release --bin struct
cargo run --release --bin trait
vojta7
commented
4 years ago 
JoshMcguigan
commented
4 years ago 
I wonder if you (or I) could somehow have some global compiler/cargo setting configured which could cause this difference?
I get this same performance no matter which of the benchmarks I run first.
 jonas-schievink
commented
4 years ago
jonas-schievink
commented
4 years ago The Cargo and rustc versions you posted mismatch. Please use the newest nightly when reporting performance bugs.
JoshMcguigan
commented
4 years ago The Cargo and rustc versions you posted mismatch. Please use the newest nightly when reporting performance bugs.
Apologies for the confusion. I was trying to convey that I tested with both stable and the latest nightly, and found the same issue. I realize now that my original issue description was misleading, so I've corrected it to show the version of rustc I was using for nightly testing.
edit - Actually, further testing with the following commands suggest the latest nightly provides equal performance for both versions of this program, but slower than the struct version on 1.41 stable.
cargo run --release --bin struct -> ~1000 ms
cargo run --release --bin trait -> ~1250 ms
cargo +nightly --release --bin struct -> ~1250 ms
cargo +nightly --release --bin trait -> ~1250 ms
vojta7
commented
4 years ago I copy-pasted your code from linked repo to godbolt, fmt is making it hard to read. But we can see the only different part is this symbol <example::OddFinderOne as example::OddFinder>::is_odd: (line 48), but as far as I can see it is never called.
I think that this can cause different memory layout which can significantly change the result of such a small benchmark, but this effect is purely random and I believe that slightly different layout can even speed up the resulting binary. So this can explain that your result differs from mine.
Generated assembly is the same for nightly and rustc 1.41.0
Sorry for my English, I am not a native speaker
JoshMcguigan
commented
4 years ago Thanks for your help tracking this down. It is odd that godbolt shows the generated assembly is the same from 1.41.0 to nightly, as I was seeing different performance between the two. I've since updated to 1.41.1 on my machine (which seemed to behave the same a 1.41.0), and I did the following test:
$ cargo build --release --bin struct && cp target/release/struct ./struct-stable && cargo +nightly build --release --bin struct && cp target/release/struct ./struct-nightly
$ ls -l
total 5352
-rw-rw-r--. 1 josh josh 150 Feb 29 04:28 Cargo.lock
-rw-rw-r--. 1 josh josh 118 Feb 29 14:07 Cargo.toml
-rw-rw-r--. 1 josh josh 10803 Feb 29 08:10 LICENSE-APACHE.txt
-rw-rw-r--. 1 josh josh 10803 Feb 29 08:10 LICENSE-MIT.txt
-rw-rw-r--. 1 josh josh 121 Feb 29 09:45 README.md
drwxrwxr-x. 3 josh josh 4096 Feb 29 05:34 src
-rwxrwxr-x. 1 josh josh 2781704 Feb 29 18:20 struct-nightly
-rwxrwxr-x. 1 josh josh 2646504 Feb 29 18:20 struct-stable
drwxrwxr-x. 5 josh josh 4096 Feb 29 04:36 target
$ ./struct-stable
1999999999 in 1025 ms
$ ./struct-nightly
1999999999 in 1283 msNote the difference in size of the struct-stable vs struct-nightly binaries. I tried running objdump -d $BIN on each of these files and diffing the output, but the diff was very large. Is there some other way I could meaningfully inspect these binaries locally?
 zacps
commented
4 years ago
zacps
commented
4 years ago Is there some other way I could meaningfully inspect these binaries locally?
See cargo asm
 avl
commented
4 years ago
avl
commented
4 years ago I tried the two programs, for fun, and got no difference. (458ms for both, on Ryzen 3900X).
@JoshMcguigan What CPU are you using? And what operating system?
It would be interesting to see what a profiler such as 'perf' sees!
If you're on linux, you can do
perf stat
To get some cpu-performance counter values. It would be interesting to know what differs between the two binaries.
avl
commented
4 years ago Interestingly on linux I get:
anders@adesk:~/cost-of-indirection$ cargo run --release --bin struct
Finished release [optimized] target(s) in 0.00s
Running `target/release/struct`
1999999999 in 884 ms
anders@adesk:~/cost-of-indirection$ cargo run --release --bin trait
Finished release [optimized] target(s) in 0.00s
Running `target/release/trait`
1999999999 in 441 msWhile on windows, I got 458ms for both tests!
avl
commented
4 years ago perf stat output:
struct:
Performance counter stats for './struct':
903,24 msec task-clock # 0,999 CPUs utilized
85 context-switches # 0,094 K/sec
0 cpu-migrations # 0,000 K/sec
79 page-faults # 0,087 K/sec
4 010 883 875 cycles # 4,441 GHz (83,18%)
995 489 stalled-cycles-frontend # 0,02% frontend cycles idle (83,18%)
2 152 816 stalled-cycles-backend # 0,05% backend cycles idle (83,18%)
12 003 392 736 instructions # 2,99 insn per cycle
# 0,00 stalled cycles per insn (83,58%)
1 997 923 689 branches # 2211,947 M/sec (83,62%)
6 810 branch-misses # 0,00% of all branches (83,27%)
0,903763382 seconds time elapsed
0,903399000 seconds user
0,000000000 seconds sys
trait:
Performance counter stats for './trait':
461,13 msec task-clock # 0,999 CPUs utilized
42 context-switches # 0,091 K/sec
0 cpu-migrations # 0,000 K/sec
83 page-faults # 0,180 K/sec
2 005 966 735 cycles # 4,350 GHz (83,08%)
479 742 stalled-cycles-frontend # 0,02% frontend cycles idle (83,52%)
1 059 865 stalled-cycles-backend # 0,05% backend cycles idle (83,52%)
11 976 454 941 instructions # 5,97 insn per cycle
# 0,00 stalled cycles per insn (83,53%)
1 994 858 712 branches # 4326,004 M/sec (83,52%)
3 681 branch-misses # 0,00% of all branches (82,82%)
0,461547111 seconds time elapsed
0,461368000 seconds user
0,000000000 seconds sys
$ perf stat -d target/release/struct
1999999999 in 1012 ms
Performance counter stats for 'target/release/struct':
1,007.20 msec task-clock:u # 0.994 CPUs utilized
0 context-switches:u # 0.000 K/sec
0 cpu-migrations:u # 0.000 K/sec
77 page-faults:u # 0.076 K/sec
3,187,890,051 cycles:u # 3.165 GHz (49.87%)
11,991,292,654 instructions:u # 3.76 insn per cycle (62.40%)
1,998,678,625 branches:u # 1984.399 M/sec (62.51%)
10,936 branch-misses:u # 0.00% of all branches (62.51%)
211,202 L1-dcache-loads:u # 0.210 M/sec (62.60%)
9,782 L1-dcache-load-misses:u # 4.63% of all L1-dcache hits (62.57%)
1,063 LLC-loads:u # 0.001 M/sec (50.01%)
46 LLC-load-misses:u # 4.33% of all LL-cache hits (49.93%)
1.013577794 seconds time elapsed
0.997534000 seconds user
0.003969000 seconds sys
$ perf stat -d target/release/trait
1999999999 in 1283 ms
Performance counter stats for 'target/release/trait':
1,283.87 msec task-clock:u # 1.000 CPUs utilized
0 context-switches:u # 0.000 K/sec
0 cpu-migrations:u # 0.000 K/sec
75 page-faults:u # 0.058 K/sec
4,039,253,928 cycles:u # 3.146 GHz (49.88%)
12,000,040,451 instructions:u # 2.97 insn per cycle (62.42%)
2,000,434,927 branches:u # 1558.131 M/sec (62.49%)
14,333 branch-misses:u # 0.00% of all branches (62.57%)
210,909 L1-dcache-loads:u # 0.164 M/sec (62.61%)
9,571 L1-dcache-load-misses:u # 4.54% of all L1-dcache hits (62.58%)
1,256 LLC-loads:u # 0.978 K/sec (49.97%)
473 LLC-load-misses:u # 37.66% of all LL-cache hits (49.89%)
1.284390399 seconds time elapsed
1.273640000 seconds user
0.001981000 seconds sysThanks @avl for suggesting the perf tool. Note the difference in LLC-load-misses between the two programs (~4% vs ~37%).
I think at this point we've pretty well proven this is a very hardware specific behaviour, particularly since your machine demonstrates the exact opposite (trait 2x faster than struct).
Given this, I'm not sure if there is anything actionable here for the compiler team, with the possible exception of not including the trait impl at all in the resulting binary if it is not used. I'm not sure if the compiler including all trait methods in the resulting binary is standard behaviour, or if perhaps this is a weird situation where since the function is inlined it can be removed, but the compiler doesn't take that code size optimization. In either case, feel free to close this issue if you don't think this merits further investigation.
avl
commented
4 years ago The difference in LLC-load-misses was indeed very large! I wonder if it has any impact on the program though. Even 473 misses should complete very quickly, and not affect the total runtime very much. This program should be completely CPU-limited.
avl
commented
4 years ago I see the 'bad' performance on "rustc 1.41.1 (f3e1a954d 2020-02-24)". On "rustc 1.43.0-nightly (834bc5650 2020-02-24)", both versions are equally fast.
avl
commented
4 years ago I've done some more digging. It seems the performance doesn't really have anything to do with the code in the binary. Minor changes which don't affect the hot code path at all seem to give differences. I even saw a case where running with the 'rt scheduler' in linux made one of the programs slower, but not the other.
I've established that the 'problem' is not a 'startup penalty'. Each iteration of the loop really becomes slower. I verified this by having an environment variables determine the number of iterations, and running the two binaries with different numbers of iterations. The percentage-wise performance difference was about constant.
If a static number of iterations is used, just changing the number of iterations is enough to change the performance.
avl
commented
4 years ago perf annotate gives slightly different profiles for the fast and the slow runs:
fast:

slow:
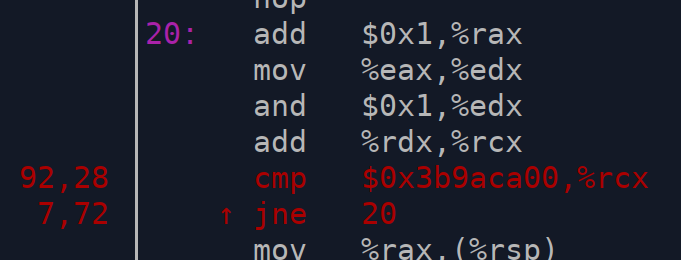 avl
commented
4 years ago
avl
commented
4 years ago Ok, I've reduced the performance difference (on my machine at least) to just being a question of alignment of the inner loop. I created two small assembler programs (so that we can get very direct control over the generated program), and could relatively easily create one fast and one slow program.
avl
commented
4 years ago Well, actually, it turns out that it if the inner-loop is located entirely within one cache-line, it is fast. If it spans two cache-lines, it is slow.
If the compiler could somehow figure out that this is a very hot loop, it could, in this particular case, actually use this knowledge to improve performance.
On my machine, in this particular case. It would be interesting to know if this is common to all processors, in all situations, or if this particular micro benchmark triggers something in my CPU.
avl
commented
4 years ago Okay, tried on an "Intel Xeon E3-1575M". The difference is much much smaller here, but the cacheline-spanning loop is still slightly slower, approximately in line with the original poster.
JoshMcguigan
commented
4 years ago Really interesting analysis! Thanks for sharing your work @avl
avl
commented
4 years ago AMD's "Software Optimization Guide for AMD Family 17h Models 30h and Greater Processors" has this to say:
"Since the processor can read an aligned 64-byte fetch block every cycle, aligning the end of the loop to the last byte of a 64-byte cache line is the best thing to do, if possible."
So at least profile-guided optimization could in theory detect the case described by this report and fix it. Any small loop with more than N iterations should be 64-byte aligned. I suppose this requires LLVM-support and may be outside the scope of the Rust-project?
Hi all, thanks for all the work on the rust project!
I tried this code:
I expected it to perform similarly to this code:
Instead, this happened:
The version with the
is_oddmethod defined directly on the struct completes in 1032 ms, while the version whereis_oddis defined as part of the trait completes in 1340 ms. I would expect this abstraction to be zero cost, since thefind_nth_oddmethod in both cases is defined as taking the concrete struct as an argument (as opposed to a trait object).Meta
rustc --version --verbose:rustc +nightly --version --verboseI see the same behavior with both the latest stable and nightly compilers. I run both version of the program in release mode. The reported performance numbers have proven to be very repeatable.
Let me know if I can provide any additional useful information. You can find my repo containing this benchmark code at the link below.
https://github.com/JoshMcguigan/cost-of-indirection