 bluss
commented
7 years ago
bluss
commented
7 years ago That sounds good, and I love a good illustration to go together with expressing an idea.
One concern I have here is that it's probably still not an efficient way to implement convolution, to go through this.
 Robbepop
Robbepop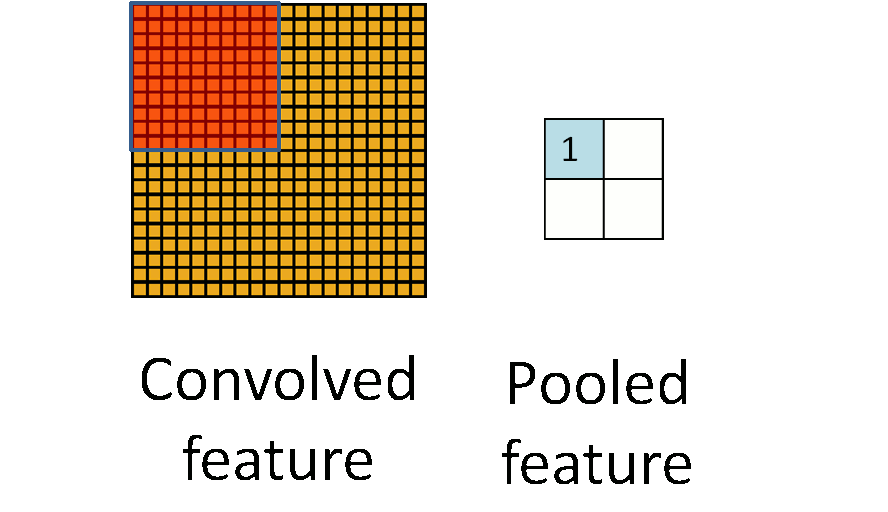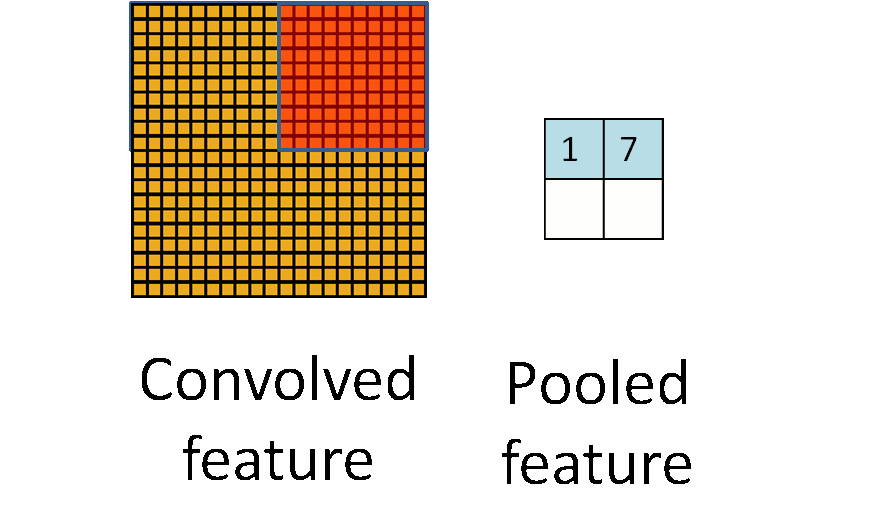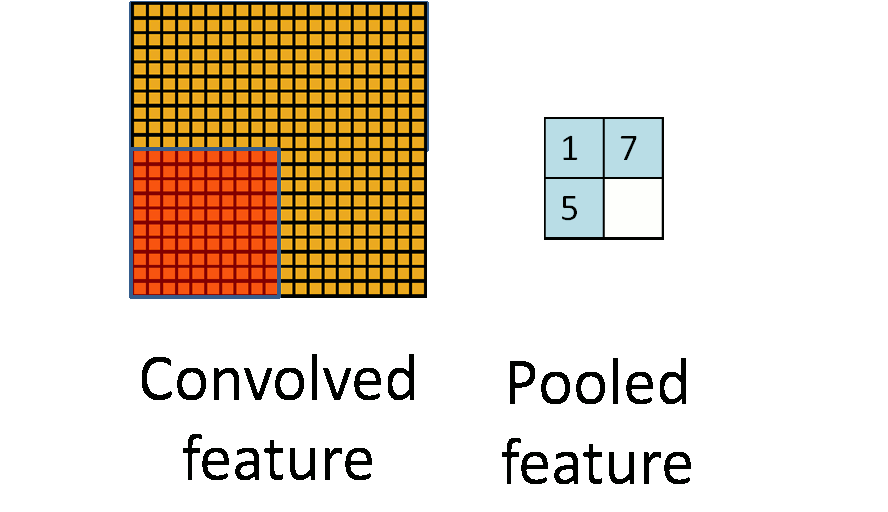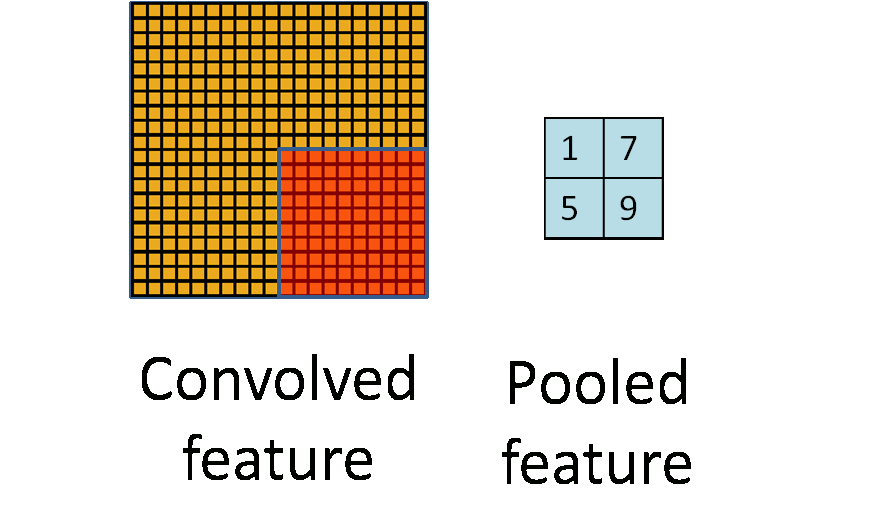{kind=link}
Already implemented features and todos:
ExactChunksandExactChunksMutaswell as theirNdProducerimplRaggedChunksor simplyChunksaswell as theirNdProducerimplWindowsNdProducerimpl forWindowsImplement n-dimensional
windowsandchunksiterators.Windows-iterators are especially useful for convolutional neural networks while chunk iterations may prove useful for paralell algorithms.
N-Dimensionality for both iterators use N-dimensionally shaped items.
For example for a 1-dimensional Array the
windowsandchunksitems are also 1-dimensional. For a 2-dimensional Array thewindowsandchunksitems are 2-dimensional, and so on.For
windowsiterator it could be useful to support two different kinds ofwindowsiterators. One for "valid" windows only that iterate only over windows within a valid region. For example in a valid-windows iterator over a10x10shaped 2d-array and window sizes of4x4the iterator would iterate totally over(10-4+1)x(10-4+1)items of size4x4. A full-windows iterator would also iterate over the windows with invalid elements (on the edges of the array) and would simulate missing elements with zero elements.Semi-nice visualization of n-dimensional chunks and windows iterators.
A similar approach could be used for n-dimensional chunks that iterate beyond the array sizes and replace missing/invalid array elements with zero elements.