 2moe
commented
6 months ago
2moe
commented
6 months ago BTW, SDK:
- Microsoft Platform SDK February 2003
- Microsoft Visual C++ Toolkit 2003
Closed 2moe closed 6 months ago
2moe
commented
6 months ago BTW, SDK:
 seritools
commented
6 months ago
seritools
commented
6 months ago Thanks for testing these!
And I think this may be a problem with the WinXP cmd itself.
Yeah, on WinXP there is no unicows fallbacks being loaded adn the commands go straight through to WriteConsoleW just like on modern Windows, so it seems more like an issue of the old cmd.exe not fully running in unicode mode or something similar.
EDIT: Ah, might actually be fixable!
This function uses either Unicode characters or 8-bit characters from the console's current code page. The console's code page defaults initially to the system's OEM code page. To change the console's code page, use the SetConsoleCP or SetConsoleOutputCP functions.
I'll try to reproduce it and add a workaround/fix! From this stackoverflow post it seems like you have to switch to a truetype font like Luicda Console and maybe even need to set up font fallback for asian characters (SimHeim, SimSun, MS PGothic, etc). Anyways, it doesn't seem to be a rust9x-specific problem.
In fact, if you enable the (recently fully deprecated) legacy console in modern Windows versions:
You'll see the same behavior
On win95, as long as unicows.dll is included, it will output unicode characters, but the program will end up in panic.
I'm more surprised that it actually manages to output those characters, at least if your locale/windows language doesn't include them! Interesting, I'll try it on my Win98 system and see if I can figure out where the panic comes from.
seritools
commented
6 months ago Just tested
fn main() {
println!("Hello, 世界!");
}on my Win98 machine, it doesn't crash, but also just writes "Hello, ??!" to the console as expected (since the codepage doesn't have those characters).
What version and language of Win95 did you use?
Regarding the panic - it seems like WriteConsoleW in unicows just passes through the lpNumberOfCharsWritten, and the asian characters use surrogate pairs in UTF16 (=2 chars), but map to a single char in the used code page, causing a difference in length. I'll see what I can do with that check.
EDIT: checking in rust playground, '界'.len_utf16() is 1, so nothing weird here... no idea yet what causes it
2moe
commented
6 months ago What version and language of Win95 did you use?
That's Win95 Chinese Edition, and system language is Chinese. The exact version may be OSR2.5. I am running it in a virtual machine.
I have two ideas:
Considering that 9x and NT have different levels of unicode support, it may be necessary to treat them separately.
Without knowing the underlying details, I've done tests before that show that:
The behavior of SetConsoleOutputCP(CP_UTF8) and chcp 65001 is "almost" the same.
When I use CP_UTF8, I'm actually using the "A" api.
2moe
commented
6 months ago Off topic: I don't know the history of the win95/98 era. I'm curious if back then, if a software had to support languages from multiple countries around the world (including East Asia), it would need to be distributed separately.
seritools
commented
6 months ago convert the character encoding to UTF-16 LE, and then use the "W" api to output.
that's exactly what the rust stdlib does :) it converts from utf8 to utf16 and calls WriteConsoleW, and then, on 9x/ME ...
Instead of using unicode, convert the character encoding to the corresponding language encoding, and then use the "A" api.
... unicows checks the system (ACP) and console (OEM) codepage, and converts the utf16 to the console codepage, and then calls WriteConsoleA
Considering that 9x and NT have different levels of unicode support, it may be necessary to treat them separately.
that's exactly what unicows is supposed to do ^^
I'm curious if back then, if a software had to support languages from multiple countries around the world (including East Asia), it would need to be distributed separately.
yes, definitely. lots of programs and games were specifically made for a region. there are lots of games that only work correctly with a Japanese locale, for example.
Codepages are byte-based, so they had to hack in support for multibyte characters (since obviously there are more than 256 Chinese characters): https://learn.microsoft.com/en-us/cpp/c-runtime-library/single-byte-and-multibyte-character-sets?view=msvc-170 https://learn.microsoft.com/en-us/cpp/text/support-for-multibyte-character-sets-mbcss?view=msvc-170 https://learn.microsoft.com/en-us/windows/win32/intl/double-byte-character-sets (All the pages are begging the reader to just use Unicode :^))
MBCS seems to work like a primitive, language/region-specific version of UTF8. The first half of the first byte stays ASCII (0x00-0x7F) and the second half can be an "MBCS lead byte", meaning that the next byte is part of the same character.
The problem with unicows is that it just doesn't account for the MBCS multibyte characters (I don't think even windows itself does, 'A' apis always just work with byte-strings, but still calls them characters) when returning the "number of characters written". In other words, the string "Hello, 世界!" (plus NUNL byte) is 11 characters, but is 13 bytes: ['H', 'e', 'l', 'l', 'o', ',', ' ', '世' (first half), '世' (second half), '界' (first half), '界' (second half), '!', '\0'].
Rust checks the number of chars written to know how much was actually written, but since it only consisted of 11 utf-16 wchars, the 13 (mbcs bytes) will be out of bounds when indexing.
So yeah, in the end,
Instead of using unicode, convert the character encoding to the corresponding language encoding, and then use the "A" api.
this is needed. I think doing the conversion on the stdlib side makes sense, so we know how many bytes we expect to write out. Thankfully console I/O is probably the only area where this is needed.
seritools
commented
6 months ago Without knowing the underlying details, I've done tests before that show that: The behavior of SetConsoleOutputCP(CP_UTF8) and chcp 65001 is "almost" the same. When I use CP_UTF8, I'm actually using the "A" api.
The UTF8 console implementation has been broken and not recommended until very recently (some Windows 10 release I think?). Either way, it won't help with the font rendering issue on Windows XP's cmd.exe, so there is no reason to change it from Rust mainline.
seritools
commented
6 months ago For 9x/ME:
So there's a right way, and a hacky way:
The right way (roughly what unicows does):
GetOEMCP(), check the maximum byte count per character via GetCPInfo()MultiByteToWideChar), then to the OEM codepage (WideCharToMultiByte)
b. call WriteConsoleA
b. check that all bytes are written.However, if the number of bytes written don't match, you'd have to scan through the string to figure out how many MBCS characters, not bytes have been written, to report the correct usize for the length of written utf8 chars.
The hacky way:
This will actually likely work, as the buffer hopefully isn't smaller than 8K on any Windows version, and thus should always be able to write the entire buffer. I think I'll go with this one and create an improvement issue if someone wants to implement the proper way.
seritools
commented
6 months ago Oh, it always happens when the number of characters in utf16 doesn't match the number of characters in the output. This can easily happen with emojis as well.
seritools
commented
6 months ago @2moe I've added the hacky fix to rust9x for now, and updated the description in #14.
I'll upload a rust9x v2 dist in a bit if you'd like to test :)
2moe
commented
6 months ago On my pc, it takes about an hour to compile rust9x(stage2) manually. Maybe letting github actions compile it automatically is a better option.
Right now I'm not home to do the test. I can then send you a PR to have "github actions" automatically compile and publish to "github releases".
seritools
commented
6 months ago https://github.com/rust9x/rust/releases/tag/rust9x-1.76-beta-v2 @2moe there you go!
2moe
commented
6 months ago @seritools Thank you. You are very warm and friendly. 😊
2moe
commented
6 months ago It works.
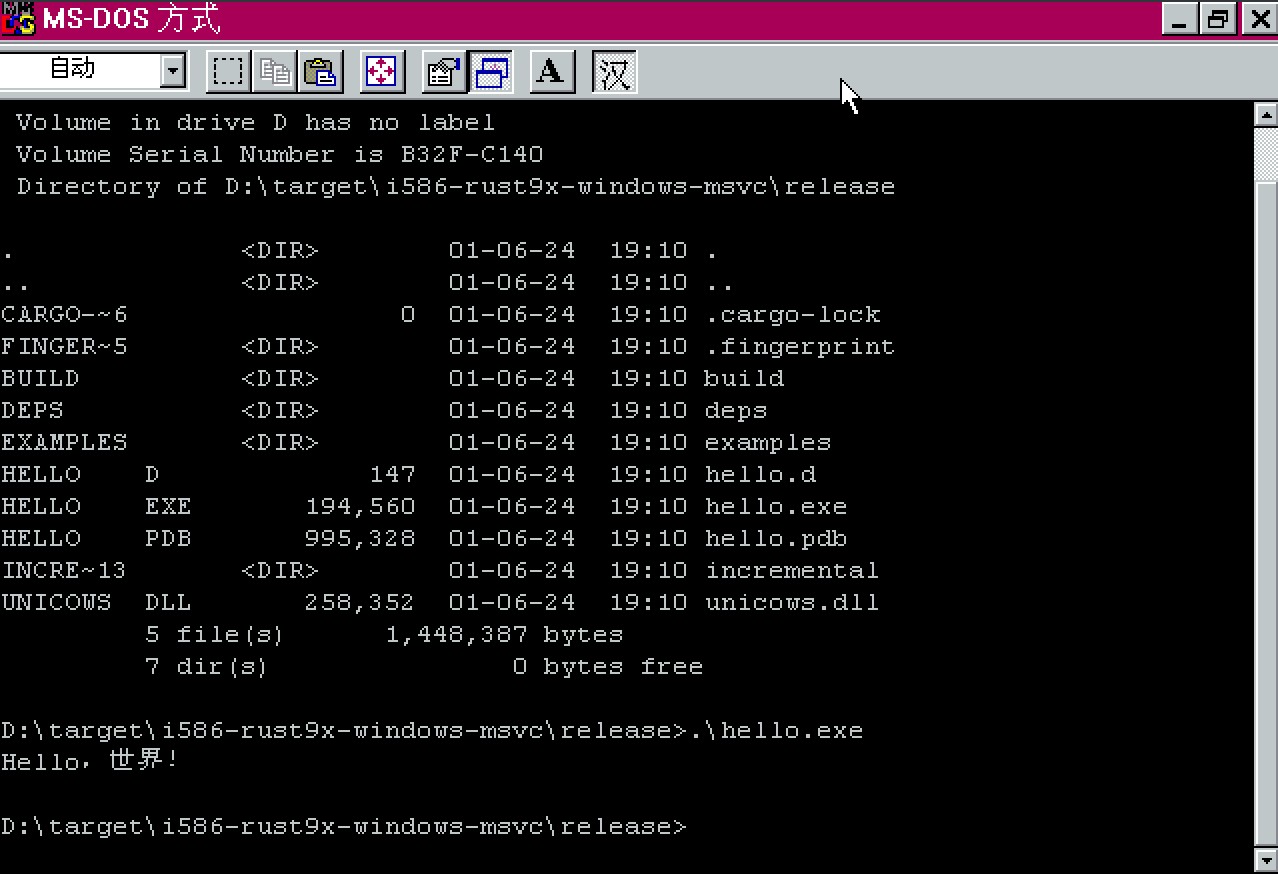
On win95, as long as unicows.dll is included, it will output unicode characters, but the program will end up in panic.
On WinXP, the same program will not panic. But XP has other unicode problems.
If the "non-unicode profile" is English, then the unicode character becomes "??", which does not automatically fallback to the corresponding font. And I think this may be a problem with the WinXP cmd itself.
bad:
good:
good: