 evgmik
commented
3 years ago
evgmik
commented
3 years ago I recall why I made a memory buffer per file. As an app writes to a file, even a small chunk, it had to go through encryption of the full file at the overlay layer. More importantly it disconnect the old node (with previous version) and make it efficiently ghost. So not having a buffer was difficult due to the overhead of staging it to the git.
 sahib
sahib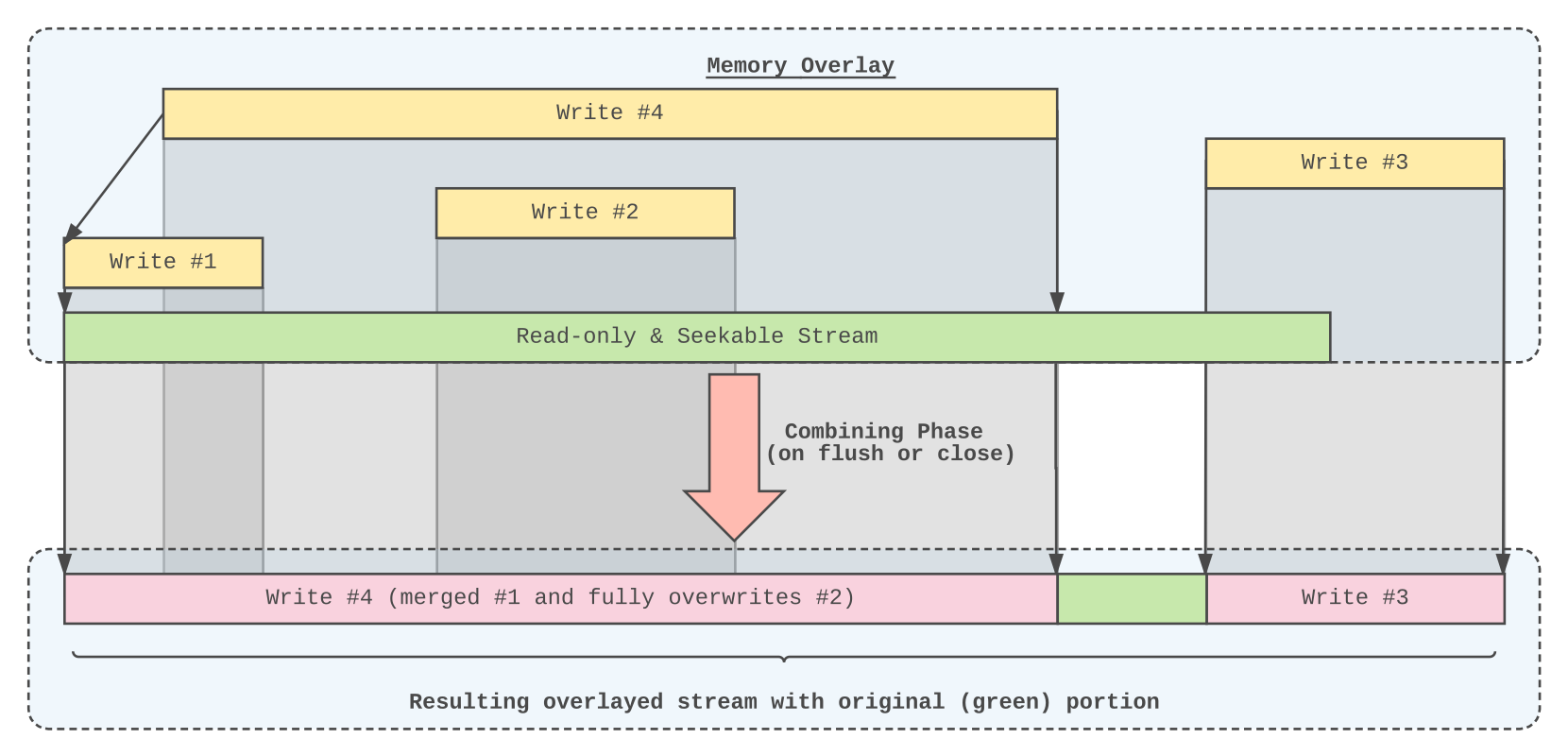
Things that should be tackled:
catfs/mio/overlay) should be partly reverted.(Note: The above could be implemented by using BadgerDB instead of keeping modifications in memory)
Other things: