 samice99
commented
1 year ago
samice99
commented
1 year ago { "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "<p style=\"text-align:center\">\n", " <a href=\"https://skills.network/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork865-2023-01-01\">\n", " <img src=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/assets/logos/SN_web_lightmode.png\" width=\"200\" alt=\"Skills Network Logo\" />\n", " \n", "
\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# Space X Falcon 9 First Stage Landing Prediction\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "\n", "## Web scraping Falcon 9 and Falcon Heavy Launches Records from Wikipedia\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Estimated time needed: 40 minutes\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "In this lab, you will be performing web scraping to collect Falcon 9 historical launch records from a Wikipedia page titled{kind=link}
List of Falcon 9 and Falcon Heavy launches\n",
"\n",
"https://en.wikipedia.org/wiki/List_of_Falcon_9_and_Falcon_Heavy_launches\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Falcon 9 first stage will land successfully\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Falcon 9 first stage will land successfully\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Several examples of an unsuccessful landing are shown here:\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Several examples of an unsuccessful landing are shown here:\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
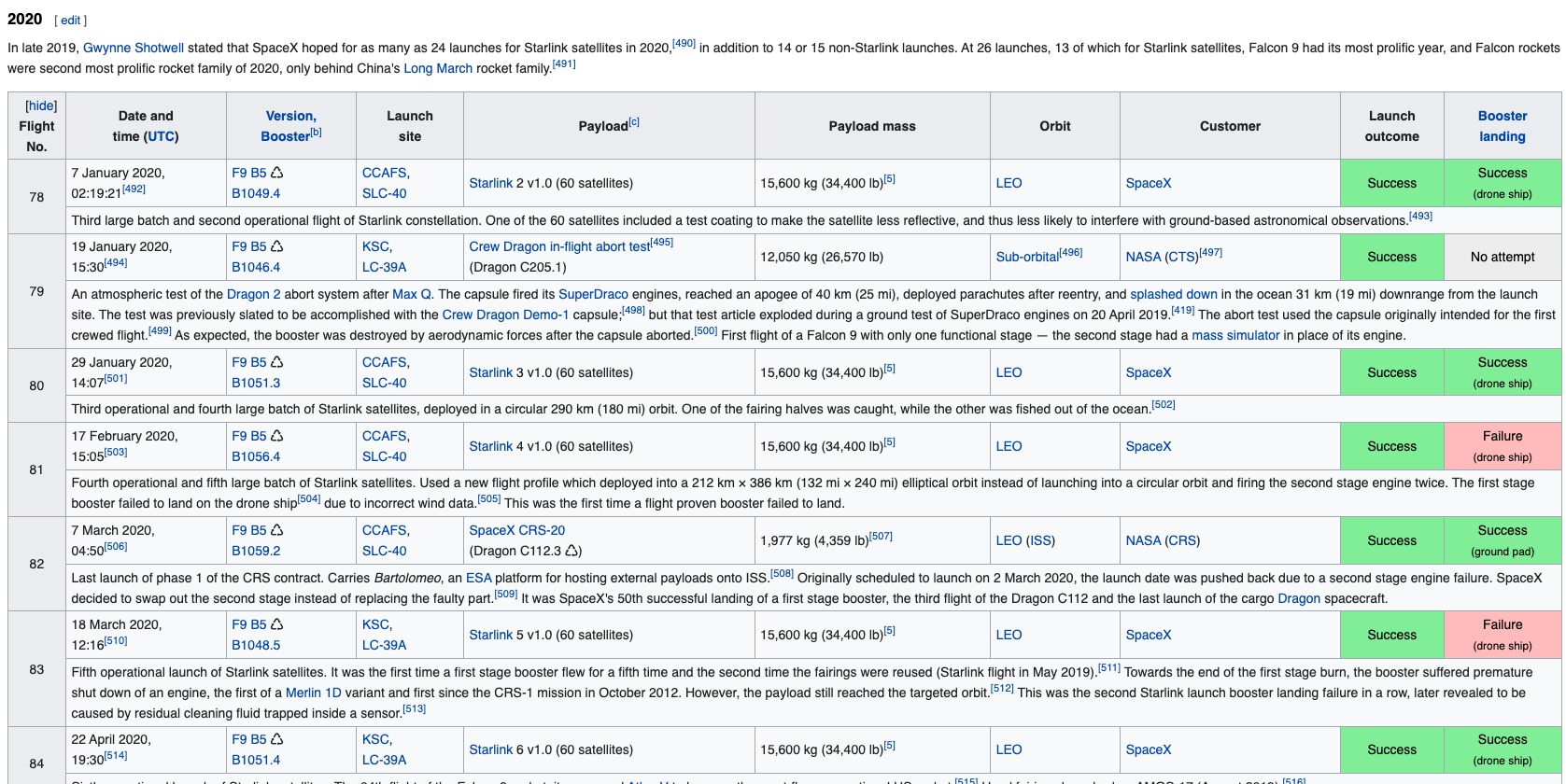
"More specifically, the launch records are stored in a HTML table shown below:\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"More specifically, the launch records are stored in a HTML table shown below:\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ## Objectives\n",
"Web scrap Falcon 9 launch records with
\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" ## Objectives\n",
"Web scrap Falcon 9 launch records with BeautifulSoup: \n",
"- Extract a Falcon 9 launch records HTML table from Wikipedia\n",
"- Parse the table and convert it into a Pandas data frame\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"First let's import required packages for this lab\n"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Requirement already satisfied: beautifulsoup4 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (4.11.1)\n",
"Requirement already satisfied: soupsieve>1.2 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from beautifulsoup4) (2.3.2.post1)\n",
"Requirement already satisfied: requests in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (2.29.0)\n",
"Requirement already satisfied: charset-normalizer<4,>=2 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests) (3.1.0)\n",
"Requirement already satisfied: idna<4,>=2.5 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests) (3.4)\n",
"Requirement already satisfied: urllib3<1.27,>=1.21.1 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests) (1.26.15)\n",
"Requirement already satisfied: certifi>=2017.4.17 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests) (2023.5.7)\n"
]
}
],
"source": [
"!pip3 install beautifulsoup4\n",
"!pip3 install requests"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"import requests\n",
"from bs4 import BeautifulSoup\n",
"import re\n",
"import unicodedata\n",
"import pandas as pd"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"and we will provide some helper functions for you to process web scraped HTML table\n"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"def date_time(table_cells):\n",
" \"\"\"\n",
" This function returns the data and time from the HTML table cell\n",
" Input: the element of a table data cell extracts extra row\n",
" \"\"\"\n",
" return [data_time.strip() for data_time in list(table_cells.strings)][0:2]\n",
"\n",
"def booster_version(table_cells):\n",
" \"\"\"\n",
" This function returns the booster version from the HTML table cell \n",
" Input: the element of a table data cell extracts extra row\n",
" \"\"\"\n",
" out=''.join([booster_version for i,booster_version in enumerate( table_cells.strings) if i%2==0][0:-1])\n",
" return out\n",
"\n",
"def landing_status(table_cells):\n",
" \"\"\"\n",
" This function returns the landing status from the HTML table cell \n",
" Input: the element of a table data cell extracts extra row\n",
" \"\"\"\n",
" out=[i for i in table_cells.strings][0]\n",
" return out\n",
"\n",
"\n",
"def get_mass(table_cells):\n",
" mass=unicodedata.normalize(\"NFKD\", table_cells.text).strip()\n",
" if mass:\n",
" mass.find(\"kg\")\n",
" new_mass=mass[0:mass.find(\"kg\")+2]\n",
" else:\n",
" new_mass=0\n",
" return new_mass\n",
"\n",
"\n",
"def extract_column_from_header(row):\n",
" \"\"\"\n",
" This function returns the landing status from the HTML table cell \n",
" Input: the element of a table data cell extracts extra row\n",
" \"\"\"\n",
" if (row.br):\n",
" row.br.extract()\n",
" if row.a:\n",
" row.a.extract()\n",
" if row.sup:\n",
" row.sup.extract()\n",
" \n",
" colunm_name = ' '.join(row.contents)\n",
" \n",
" # Filter the digit and empty names\n",
" if not(colunm_name.strip().isdigit()):\n",
" colunm_name = colunm_name.strip()\n",
" return colunm_name \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To keep the lab tasks consistent, you will be asked to scrape the data from a snapshot of the List of Falcon 9 and Falcon Heavy launches Wikipage updated on\n",
"9th June 2021\n"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"static_url = \"https://en.wikipedia.org/w/index.php?title=List_of_Falcon_9_and_Falcon_Heavy_launches&oldid=1027686922\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next, request the HTML page from the above URL and get a response object\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### TASK 1: Request the Falcon9 Launch Wiki page from its URL\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"First, let's perform an HTTP GET method to request the Falcon9 Launch HTML page, as an HTTP response.\n"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"https://en.wikipedia.org/w/index.php?title=List_of_Falcon_9_and_Falcon_Heavy_launches&oldid=1027686922\n"
]
}
],
"source": [
"# use requests.get() method with the provided static_url\n",
"response = requests.get(static_url)\n",
"\n",
"response.status_code\n",
"\n",
"print(response.url)\n",
"\n",
"# assign the response to a object\n",
"object = response"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Create a BeautifulSoup object from the HTML response\n"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Use BeautifulSoup() to create a BeautifulSoup object from a response text content\n",
"# soup = BeautifulSoup(response.text,\"https://en.wikipedia.org/w/index.php?title=List_of_Falcon_9_and_Falcon_Heavy_launches&oldid=1027686922\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Print the page title to verify if the BeautifulSoup object was created properly \n"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"text/plain": [
"BeautifulSoup, please check the external reference link towards the end of this lab\n"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Use the find_all function in the BeautifulSoup object, with element type table\n",
"# Assign the result to a list called html_tables\n",
"html_tables = soup.find_all('table')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Starting from the third table is our target table contains the actual launch records.\n"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"<table class=\"wikitable plainrowheaders collapsible\" style=\"width: 100%;\">\n",
"time (<a href=\"/wiki/Coordinated_Universal_Time\" title=\"Coordinated Universal Time\">UTC)\n", "\n", "<th scope=\"col\"><a href=\"/wiki/List_of_Falcon_9_first-stage_boosters\" title=\"List of Falcon 9 first-stage boosters\">Version,
Booster <sup class=\"reference\" id=\"cite_ref-booster_11-0\"><a href=\"#cite_note-booster-11\">[b]\n", "\n", "<th scope=\"col\">Launch site\n", "\n", "<th scope=\"col\">Payload<sup class=\"reference\" id=\"cite_ref-Dragon_12-0\"><a href=\"#cite_note-Dragon-12\">[c]\n", "\n", "<th scope=\"col\">Payload mass\n", "\n", "<th scope=\"col\">Orbit\n", "\n", "<th scope=\"col\">Customer\n", "\n", "<th scope=\"col\">Launch
outcome\n", "\n", "<th scope=\"col\"><a href=\"/wiki/Falcon_9_first-stage_landing_tests\" title=\"Falcon 9 first-stage landing tests\">Booster
landing\n", "
18:45\n", "
B0003.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-0\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
(parachute)\n", "
15:43<sup class=\"reference\" id=\"cite_ref-spaceflightnow_Clark_Launch_Report_19-0\"><a href=\"#cite_note-spaceflightnow_Clark_Launch_Report-19\">[13]\n", "
B0004.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-1\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
(Dragon C101)\n", "
- <a href=\"/wiki/NASA\" title=\"NASA\">NASA (<a href=\"/wiki/Commercial_Orbital_Transportation_Services\" title=\"Commercial Orbital Transportation Services\">COTS) \n", "
- <a href=\"/wiki/National_Reconnaissance_Office\" title=\"National Reconnaissance Office\">NRO
(parachute)\n", "
07:44<sup class=\"reference\" id=\"cite_ref-BBC_new_era_23-0\"><a href=\"#cite_note-BBC_new_era-23\">[17]\n", "
B0005.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-2\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
(Dragon C102)\n", "
00:35<sup class=\"reference\" id=\"cite_ref-SFN_LLog_27-0\"><a href=\"#cite_note-SFN_LLog-27\">[21]\n", "\n", "<td rowspan=\"2\"><a href=\"/wiki/Falcon_9_v1.0\" title=\"Falcon 9 v1.0\">F9 v1.0<sup class=\"reference\" id=\"cite_ref-MuskMay2012_13-3\"><a href=\"#cite_note-MuskMay2012-13\">[7]
B0006.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-3\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "\n", "<td rowspan=\"2\"><a href=\"/wiki/Cape_Canaveral_Space_Force_Station\" title=\"Cape Canaveral Space Force Station\">CCAFS,
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "\n", "
(Dragon C103)\n", "
15:10\n", "
B0007.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-4\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
(Dragon C104)\n", "
16:00<sup class=\"reference\" id=\"cite_ref-pa20130930_36-0\"><a href=\"#cite_note-pa20130930-36\">[30]\n", "
B1003<sup class=\"reference\" id=\"cite_ref-block_numbers_14-5\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Vandenberg_Space_Launch_Complex_4\" title=\"Vandenberg Space Launch Complex 4\">SLC-4E\n", "
(ocean)<sup class=\"reference\" id=\"cite_ref-ocean_landing_38-0\"><a href=\"#cite_note-ocean_landing-38\">[d]\n", "
22:41<sup class=\"reference\" id=\"cite_ref-sfn_wwls20130624_41-0\"><a href=\"#cite_note-sfn_wwls20130624-41\">[34]\n", "
B1004\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
<sup class=\"reference\" id=\"cite_ref-sf10120131203_45-0\"><a href=\"#cite_note-sf10120131203-45\">[38]\n", "
<th> as follows:\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n", "<tr>\n", "<th scope=\"col\">Flight No.\n", "</th>\n", "<th scope=\"col\">Date and<br/>time (<a href=\"/wiki/Coordinated_Universal_Time\" title=\"Coordinated Universal Time\">UTC</a>)\n", "</th>\n", "<th scope=\"col\"><a href=\"/wiki/List_of_Falcon_9_first-stage_boosters\" title=\"List of Falcon 9 first-stage boosters\">Version,<br/>Booster</a> <sup class=\"reference\" id=\"cite_ref-booster_11-0\"><a href=\"#cite_note-booster-11\">[b]</a></sup>\n", "</th>\n", "<th scope=\"col\">Launch site\n", "</th>\n", "<th scope=\"col\">Payload<sup class=\"reference\" id=\"cite_ref-Dragon_12-0\"><a href=\"#cite_note-Dragon-12\">[c]</a></sup>\n", "</th>\n", "<th scope=\"col\">Payload mass\n", "</th>\n", "<th scope=\"col\">Orbit\n", "</th>\n", "<th scope=\"col\">Customer\n", "</th>\n", "<th scope=\"col\">Launch<br/>outcome\n", "</th>\n", "<th scope=\"col\"><a href=\"/wiki/Falcon_9_first-stage_landing_tests\" title=\"Falcon 9 first-stage landing tests\">Booster<br/>landing</a>\n", "</th></tr>\n", "\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next, we just need to iterate through the <th> elements and apply the provided extract_column_from_header() to extract column name one by one\n"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"column_names = []\n",
"\n",
"# Apply find_all() function with th element on first_launch_table\n",
"search_result = first_launch_table.find_all('th')\n",
"# Iterate each th element and apply the provided extract_column_from_header() to get a column name\n",
"for col in search_result:\n",
" name = extract_column_from_header(col)\n",
" if name != None and len(name) >0: \n",
" column_names.append(name)\n",
"# Append the Non-empty column name (if name is not None and len(name) > 0) into a list called column_names\n",
" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Check the extracted column names\n"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['Flight No.', 'Date and time ( )', 'Launch site', 'Payload', 'Payload mass', 'Orbit', 'Customer', 'Launch outcome']\n"
]
}
],
"source": [
"print(column_names)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## TASK 3: Create a data frame by parsing the launch HTML tables\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We will create an empty dictionary with keys from the extracted column names in the previous task. Later, this dictionary will be converted into a Pandas dataframe\n"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"launch_dict= dict.fromkeys(column_names)\n",
"\n",
"# Remove an irrelvant column\n",
"del launch_dict['Date and time ( )']\n",
"\n",
"# Let's initial the launch_dict with each value to be an empty list\n",
"launch_dict['Flight No.'] = []\n",
"launch_dict['Launch site'] = []\n",
"launch_dict['Payload'] = []\n",
"launch_dict['Payload mass'] = []\n",
"launch_dict['Orbit'] = []\n",
"launch_dict['Customer'] = []\n",
"launch_dict['Launch outcome'] = []\n",
"# Added some new columns\n",
"launch_dict['Version Booster']=[]\n",
"launch_dict['Booster landing']=[]\n",
"launch_dict['Date']=[]\n",
"launch_dict['Time']=[]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next, we just need to fill up the launch_dict with launch records extracted from table rows.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Usually, HTML tables in Wiki pages are likely to contain unexpected annotations and other types of noises, such as reference links B0004.1[8], missing values N/A [e], inconsistent formatting, etc.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To simplify the parsing process, we have provided an incomplete code snippet below to help you to fill up the launch_dict. Please complete the following code snippet with TODOs or you can choose to write your own logic to parse all launch tables:\n"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"tags": []
},
"outputs": [
{
"ename": "KeyError",
"evalue": "'Column_names'",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mKeyError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m/tmp/ipykernel_71/3635705379.py\u001b[0m in \u001b[0;36mFlight No.\n",
" datatimelist=date_time(row[0])\n",
" launch_dict('Flight No.').append(flight_number)\n",
" #print(flight_number)\n",
" print(flight_number)\n",
" \n",
" # Date value\n",
" # TODO: Append the date into launch_dict with key Date\n",
" date = datatimelist[0].strip(',')\n",
" launch_dict('Date').append(date)\n",
" #print(date)\n",
" print(date)\n",
" \n",
" # Time value\n",
" # TODO: Append the time into launch_dict with key Time\n",
" time = datatimelist[1]\n",
" launch_dict('Time').append(time)\n",
" #print(time)\n",
" print(time)\n",
" \n",
" # Booster version\n",
" # TODO: Append the bv into launch_dict with key Version Booster\n",
" bv=booster_version(row[1])\n",
" if not(bv):\n",
" bv=row[1].a.string\n",
" launch_dict('Version Booster').append(bv)\n",
" print(bv)\n",
" \n",
" # Launch Site\n",
" # TODO: Append the bv into launch_dict with key Launch Site\n",
" launch_site = row[2].a.string\n",
" launch_dict('Launch Site').append(launch_site)\n",
" #print(launch_site)\n",
" print(launch_site)\n",
" \n",
" # Payload\n",
" # TODO: Append the payload into launch_dict with key Payload\n",
" payload = row[3].a.string\n",
" launch_dict('Payload').append(launch_dict)\n",
" #print(payload)\n",
" print(payload)\n",
" \n",
" # Payload Mass\n",
" # TODO: Append the payload_mass into launch_dict with key Payload mass\n",
" payload_mass = get_mass(row[4])\n",
" launch_dict('Payload mass').append(payload_mass)\n",
" #print(payload)\n",
" print(payload_mass)\n",
" \n",
" # Orbit\n",
" # TODO: Append the orbit into launch_dict with key Orbit\n",
" orbit = row[5].a.string\n",
" launch_dict('Orbit').append(orbit)\n",
" #print(orbit)\n",
" print(orbit)\n",
" \n",
" # Customer\n",
" # TODO: Append the customer into launch_dict with key Customer\n",
" customer = row[6].a.string\n",
" launch_dict('Customer').append(customer)\n",
" #print(customer)\n",
" print(customer)\n",
" \n",
" # Launch outcome\n",
" # TODO: Append the launch_outcome into launch_dict with key Launch outcome\n",
" launch_outcome = list(row[7].strings)[0]\n",
" launch_dict('Launch outcome').append(launch_outcome)\n",
" #print(launch_outcome)\n",
" print(launch_outcome)\n",
" \n",
" # Booster landing\n",
" # TODO: Append the launch_outcome into launch_dict with key Booster landing\n",
" booster_landing = landing_status(row[8])\n",
" launch_dict('Booster landing').append(launch_outcome)\n",
" #print(booster_landing)\n",
" print(booster_landing)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After you have fill in the parsed launch record values into launch_dict, you can create a dataframe from it.\n"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Empty DataFrame\n",
"Columns: [Flight No., Launch site, Payload, Payload mass, Orbit, Customer, Launch outcome, Version Booster, Booster landing, Date, Time]\n",
"Index: []\n"
]
}
],
"source": [
"df=pd.DataFrame(launch_dict)\n",
"print(df)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now export it to a CSV for the next section, but to make the answers consistent and in case you have difficulties finishing this lab. \n",
"\n",
"Following labs will be using a provided dataset to make each lab independent. \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"df.to_csv('spacex_web_scraped.csv', index=False)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Authors\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<a href=\"https://www.linkedin.com/in/yan-luo-96288783/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork865-2023-01-01\">Yan Luo\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<a href=\"https://www.linkedin.com/in/nayefaboutayoun/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork865-2023-01-01\">Nayef Abou Tayoun\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Change Log\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"| Date (YYYY-MM-DD) | Version | Changed By | Change Description |\n",
"| ----------------- | ------- | ---------- | ----------------------- |\n",
"| 2021-06-09 | 1.0 | Yan Luo | Tasks updates |\n",
"| 2020-11-10 | 1.0 | Nayef | Created the initial version |\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Copyright © 2021 IBM Corporation. All rights reserved.\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python",
"language": "python",
"name": "conda-env-python-py"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.12"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
{ "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "<p style=\"text-align:center\">\n", " <a href=\"https://skills.network/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork865-2023-01-01\">\n", " <img src=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/assets/logos/SN_web_lightmode.png\" width=\"200\" alt=\"Skills Network Logo\" />\n", " \n", "
\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# Space X Falcon 9 First Stage Landing Prediction\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "\n", "## Web scraping Falcon 9 and Falcon Heavy Launches Records from Wikipedia\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Estimated time needed: 40 minutes\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "In this lab, you will be performing web scraping to collect Falcon 9 historical launch records from a Wikipedia page titledList of Falcon 9 and Falcon Heavy launches\n", "\n", "https://en.wikipedia.org/wiki/List_of_Falcon_9_and_Falcon_Heavy_launches\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "BeautifulSoup: \n", "- Extract a Falcon 9 launch records HTML table from Wikipedia\n", "- Parse the table and convert it into a Pandas data frame\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "First let's import required packages for this lab\n" ] }, { "cell_type": "code", "execution_count": 3, "metadata": { "tags": [] }, "outputs": [ { "name": "stdout", "output_type": "stream", "text": [ "Requirement already satisfied: beautifulsoup4 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (4.11.1)\n", "Requirement already satisfied: soupsieve>1.2 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from beautifulsoup4) (2.3.2.post1)\n", "Requirement already satisfied: requests in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (2.29.0)\n", "Requirement already satisfied: charset-normalizer<4,>=2 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests) (3.1.0)\n", "Requirement already satisfied: idna<4,>=2.5 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests) (3.4)\n", "Requirement already satisfied: urllib3<1.27,>=1.21.1 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests) (1.26.15)\n", "Requirement already satisfied: certifi>=2017.4.17 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests) (2023.5.7)\n" ] } ], "source": [ "!pip3 install beautifulsoup4\n", "!pip3 install requests" ] }, { "cell_type": "code", "execution_count": 4, "metadata": { "tags": [] }, "outputs": [], "source": [ "import sys\n", "\n", "import requests\n", "from bs4 import BeautifulSoup\n", "import re\n", "import unicodedata\n", "import pandas as pd" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "and we will provide some helper functions for you to process web scraped HTML table\n" ] }, { "cell_type": "code", "execution_count": 5, "metadata": { "tags": [] }, "outputs": [], "source": [ "def date_time(table_cells):\n", " \"\"\"\n", " This function returns the data and time from the HTML table cell\n", " Input: the element of a table data cell extracts extra row\n", " \"\"\"\n", " return [data_time.strip() for data_time in list(table_cells.strings)][0:2]\n", "\n", "def booster_version(table_cells):\n", " \"\"\"\n", " This function returns the booster version from the HTML table cell \n", " Input: the element of a table data cell extracts extra row\n", " \"\"\"\n", " out=''.join([booster_version for i,booster_version in enumerate( table_cells.strings) if i%2==0][0:-1])\n", " return out\n", "\n", "def landing_status(table_cells):\n", " \"\"\"\n", " This function returns the landing status from the HTML table cell \n", " Input: the element of a table data cell extracts extra row\n", " \"\"\"\n", " out=[i for i in table_cells.strings][0]\n", " return out\n", "\n", "\n", "def get_mass(table_cells):\n", " mass=unicodedata.normalize(\"NFKD\", table_cells.text).strip()\n", " if mass:\n", " mass.find(\"kg\")\n", " new_mass=mass[0:mass.find(\"kg\")+2]\n", " else:\n", " new_mass=0\n", " return new_mass\n", "\n", "\n", "def extract_column_from_header(row):\n", " \"\"\"\n", " This function returns the landing status from the HTML table cell \n", " Input: the element of a table data cell extracts extra row\n", " \"\"\"\n", " if (row.br):\n", " row.br.extract()\n", " if row.a:\n", " row.a.extract()\n", " if row.sup:\n", " row.sup.extract()\n", " \n", " colunm_name = ' '.join(row.contents)\n", " \n", " # Filter the digit and empty names\n", " if not(colunm_name.strip().isdigit()):\n", " colunm_name = colunm_name.strip()\n", " return colunm_name \n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "To keep the lab tasks consistent, you will be asked to scrape the data from a snapshot of theList of Falcon 9 and Falcon Heavy launchesWikipage updated on\n", "9th June 2021\n" ] }, { "cell_type": "code", "execution_count": 6, "metadata": { "tags": [] }, "outputs": [], "source": [ "static_url = \"https://en.wikipedia.org/w/index.php?title=List_of_Falcon_9_and_Falcon_Heavy_launches&oldid=1027686922\"" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Next, request the HTML page from the above URL and get aresponseobject\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### TASK 1: Request the Falcon9 Launch Wiki page from its URL\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "First, let's perform an HTTP GET method to request the Falcon9 Launch HTML page, as an HTTP response.\n" ] }, { "cell_type": "code", "execution_count": 7, "metadata": { "tags": [] }, "outputs": [ { "name": "stdout", "output_type": "stream", "text": [ "https://en.wikipedia.org/w/index.php?title=List_of_Falcon_9_and_Falcon_Heavy_launches&oldid=1027686922\n" ] } ], "source": [ "# use requests.get() method with the provided static_url\n", "response = requests.get(static_url)\n", "\n", "response.status_code\n", "\n", "print(response.url)\n", "\n", "# assign the response to a object\n", "object = response" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Create aBeautifulSoupobject from the HTMLresponse\n" ] }, { "cell_type": "code", "execution_count": 8, "metadata": { "tags": [] }, "outputs": [], "source": [ "# Use BeautifulSoup() to create a BeautifulSoup object from a response text content\n", "# soup = BeautifulSoup(response.text,\"https://en.wikipedia.org/w/index.php?title=List_of_Falcon_9_and_Falcon_Heavy_launches&oldid=1027686922\")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Print the page title to verify if theBeautifulSoupobject was created properly \n" ] }, { "cell_type": "code", "execution_count": 9, "metadata": { "tags": [] }, "outputs": [ { "data": { "text/plain": [ "BeautifulSoup, please check the external reference link towards the end of this lab\n" ] }, { "cell_type": "code", "execution_count": 10, "metadata": { "tags": [] }, "outputs": [], "source": [ "# Use the find_all function in the BeautifulSoup object, with element typetable\n", "# Assign the result to a list calledhtml_tables\n", "html_tables = soup.find_all('table')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Starting from the third table is our target table contains the actual launch records.\n" ] }, { "cell_type": "code", "execution_count": 11, "metadata": { "tags": [] }, "outputs": [ { "name": "stdout", "output_type": "stream", "text": [ "<table class=\"wikitable plainrowheaders collapsible\" style=\"width: 100%;\">\n", "time (<a href=\"/wiki/Coordinated_Universal_Time\" title=\"Coordinated Universal Time\">UTC)\n", "\n", "<th scope=\"col\"><a href=\"/wiki/List_of_Falcon_9_first-stage_boosters\" title=\"List of Falcon 9 first-stage boosters\">Version,
Booster <sup class=\"reference\" id=\"cite_ref-booster_11-0\"><a href=\"#cite_note-booster-11\">[b]\n", "\n", "<th scope=\"col\">Launch site\n", "\n", "<th scope=\"col\">Payload<sup class=\"reference\" id=\"cite_ref-Dragon_12-0\"><a href=\"#cite_note-Dragon-12\">[c]\n", "\n", "<th scope=\"col\">Payload mass\n", "\n", "<th scope=\"col\">Orbit\n", "\n", "<th scope=\"col\">Customer\n", "\n", "<th scope=\"col\">Launch
outcome\n", "\n", "<th scope=\"col\"><a href=\"/wiki/Falcon_9_first-stage_landing_tests\" title=\"Falcon 9 first-stage landing tests\">Booster
landing\n", "
18:45\n", "
B0003.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-0\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
(parachute)\n", "
15:43<sup class=\"reference\" id=\"cite_ref-spaceflightnow_Clark_Launch_Report_19-0\"><a href=\"#cite_note-spaceflightnow_Clark_Launch_Report-19\">[13]\n", "
B0004.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-1\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
(Dragon C101)\n", "
- <a href=\"/wiki/NASA\" title=\"NASA\">NASA (<a href=\"/wiki/Commercial_Orbital_Transportation_Services\" title=\"Commercial Orbital Transportation Services\">COTS)
\n",
"- <a href=\"/wiki/National_Reconnaissance_Office\" title=\"National Reconnaissance Office\">NRO
\n", "\n", "(parachute)\n", "
07:44<sup class=\"reference\" id=\"cite_ref-BBC_new_era_23-0\"><a href=\"#cite_note-BBC_new_era-23\">[17]\n", "
B0005.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-2\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
(Dragon C102)\n", "
00:35<sup class=\"reference\" id=\"cite_ref-SFN_LLog_27-0\"><a href=\"#cite_note-SFN_LLog-27\">[21]\n", "\n", "<td rowspan=\"2\"><a href=\"/wiki/Falcon_9_v1.0\" title=\"Falcon 9 v1.0\">F9 v1.0<sup class=\"reference\" id=\"cite_ref-MuskMay2012_13-3\"><a href=\"#cite_note-MuskMay2012-13\">[7]
B0006.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-3\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "\n", "<td rowspan=\"2\"><a href=\"/wiki/Cape_Canaveral_Space_Force_Station\" title=\"Cape Canaveral Space Force Station\">CCAFS,
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "\n", "
(Dragon C103)\n", "
15:10\n", "
B0007.1<sup class=\"reference\" id=\"cite_ref-block_numbers_14-4\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
(Dragon C104)\n", "
16:00<sup class=\"reference\" id=\"cite_ref-pa20130930_36-0\"><a href=\"#cite_note-pa20130930-36\">[30]\n", "
B1003<sup class=\"reference\" id=\"cite_ref-block_numbers_14-5\"><a href=\"#cite_note-block_numbers-14\">[8]\n", "
<a href=\"/wiki/Vandenberg_Space_Launch_Complex_4\" title=\"Vandenberg Space Launch Complex 4\">SLC-4E\n", "
(ocean)<sup class=\"reference\" id=\"cite_ref-ocean_landing_38-0\"><a href=\"#cite_note-ocean_landing-38\">[d]\n", "
22:41<sup class=\"reference\" id=\"cite_ref-sfn_wwls20130624_41-0\"><a href=\"#cite_note-sfn_wwls20130624-41\">[34]\n", "
B1004\n", "
<a href=\"/wiki/Cape_Canaveral_Space_Launch_Complex_40\" title=\"Cape Canaveral Space Launch Complex 40\">SLC-40\n", "
<sup class=\"reference\" id=\"cite_ref-sf10120131203_45-0\"><a href=\"#cite_note-sf10120131203-45\">[38]\n", "
<th>as follows:\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "\n", "<tr>\n", "<th scope=\"col\">Flight No.\n", "</th>\n", "<th scope=\"col\">Date and<br/>time (<a href=\"/wiki/Coordinated_Universal_Time\" title=\"Coordinated Universal Time\">UTC</a>)\n", "</th>\n", "<th scope=\"col\"><a href=\"/wiki/List_of_Falcon_9_first-stage_boosters\" title=\"List of Falcon 9 first-stage boosters\">Version,<br/>Booster</a> <sup class=\"reference\" id=\"cite_ref-booster_11-0\"><a href=\"#cite_note-booster-11\">[b]</a></sup>\n", "</th>\n", "<th scope=\"col\">Launch site\n", "</th>\n", "<th scope=\"col\">Payload<sup class=\"reference\" id=\"cite_ref-Dragon_12-0\"><a href=\"#cite_note-Dragon-12\">[c]</a></sup>\n", "</th>\n", "<th scope=\"col\">Payload mass\n", "</th>\n", "<th scope=\"col\">Orbit\n", "</th>\n", "<th scope=\"col\">Customer\n", "</th>\n", "<th scope=\"col\">Launch<br/>outcome\n", "</th>\n", "<th scope=\"col\"><a href=\"/wiki/Falcon_9_first-stage_landing_tests\" title=\"Falcon 9 first-stage landing tests\">Booster<br/>landing</a>\n", "</th></tr>\n", "\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Next, we just need to iterate through the<th>elements and apply the providedextract_column_from_header()to extract column name one by one\n" ] }, { "cell_type": "code", "execution_count": 12, "metadata": { "tags": [] }, "outputs": [], "source": [ "column_names = []\n", "\n", "# Apply find_all() function withthelement on first_launch_table\n", "search_result = first_launch_table.find_all('th')\n", "# Iterate each th element and apply the provided extract_column_from_header() to get a column name\n", "for col in search_result:\n", " name = extract_column_from_header(col)\n", " if name != None and len(name) >0: \n", " column_names.append(name)\n", "# Append the Non-empty column name (if name is not None and len(name) > 0) into a list called column_names\n", " \n", "\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Check the extracted column names\n" ] }, { "cell_type": "code", "execution_count": 13, "metadata": { "tags": [] }, "outputs": [ { "name": "stdout", "output_type": "stream", "text": [ "['Flight No.', 'Date and time ( )', 'Launch site', 'Payload', 'Payload mass', 'Orbit', 'Customer', 'Launch outcome']\n" ] } ], "source": [ "print(column_names)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## TASK 3: Create a data frame by parsing the launch HTML tables\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "We will create an empty dictionary with keys from the extracted column names in the previous task. Later, this dictionary will be converted into a Pandas dataframe\n" ] }, { "cell_type": "code", "execution_count": 16, "metadata": { "tags": [] }, "outputs": [], "source": [ "launch_dict= dict.fromkeys(column_names)\n", "\n", "# Remove an irrelvant column\n", "del launch_dict['Date and time ( )']\n", "\n", "# Let's initial the launch_dict with each value to be an empty list\n", "launch_dict['Flight No.'] = []\n", "launch_dict['Launch site'] = []\n", "launch_dict['Payload'] = []\n", "launch_dict['Payload mass'] = []\n", "launch_dict['Orbit'] = []\n", "launch_dict['Customer'] = []\n", "launch_dict['Launch outcome'] = []\n", "# Added some new columns\n", "launch_dict['Version Booster']=[]\n", "launch_dict['Booster landing']=[]\n", "launch_dict['Date']=[]\n", "launch_dict['Time']=[]" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Next, we just need to fill up thelaunch_dictwith launch records extracted from table rows.\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Usually, HTML tables in Wiki pages are likely to contain unexpected annotations and other types of noises, such as reference linksB0004.1[8], missing valuesN/A [e], inconsistent formatting, etc.\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "To simplify the parsing process, we have provided an incomplete code snippet below to help you to fill up thelaunch_dict. Please complete the following code snippet with TODOs or you can choose to write your own logic to parse all launch tables:\n" ] }, { "cell_type": "code", "execution_count": 23, "metadata": { "tags": [] }, "outputs": [ { "ename": "KeyError", "evalue": "'Column_names'", "output_type": "error", "traceback": [ "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", "\u001b[0;31mKeyError\u001b[0m Traceback (most recent call last)", "\u001b[0;32m/tmp/ipykernel_71/3635705379.py\u001b[0m in \u001b[0;36mFlight No.\n", " datatimelist=date_time(row[0])\n", " launch_dict('Flight No.').append(flight_number)\n", " #print(flight_number)\n", " print(flight_number)\n", " \n", " # Date value\n", " # TODO: Append the date into launch_dict with keyDate\n", " date = datatimelist[0].strip(',')\n", " launch_dict('Date').append(date)\n", " #print(date)\n", " print(date)\n", " \n", " # Time value\n", " # TODO: Append the time into launch_dict with keyTime\n", " time = datatimelist[1]\n", " launch_dict('Time').append(time)\n", " #print(time)\n", " print(time)\n", " \n", " # Booster version\n", " # TODO: Append the bv into launch_dict with keyVersion Booster\n", " bv=booster_version(row[1])\n", " if not(bv):\n", " bv=row[1].a.string\n", " launch_dict('Version Booster').append(bv)\n", " print(bv)\n", " \n", " # Launch Site\n", " # TODO: Append the bv into launch_dict with keyLaunch Site\n", " launch_site = row[2].a.string\n", " launch_dict('Launch Site').append(launch_site)\n", " #print(launch_site)\n", " print(launch_site)\n", " \n", " # Payload\n", " # TODO: Append the payload into launch_dict with keyPayload\n", " payload = row[3].a.string\n", " launch_dict('Payload').append(launch_dict)\n", " #print(payload)\n", " print(payload)\n", " \n", " # Payload Mass\n", " # TODO: Append the payload_mass into launch_dict with keyPayload mass\n", " payload_mass = get_mass(row[4])\n", " launch_dict('Payload mass').append(payload_mass)\n", " #print(payload)\n", " print(payload_mass)\n", " \n", " # Orbit\n", " # TODO: Append the orbit into launch_dict with keyOrbit\n", " orbit = row[5].a.string\n", " launch_dict('Orbit').append(orbit)\n", " #print(orbit)\n", " print(orbit)\n", " \n", " # Customer\n", " # TODO: Append the customer into launch_dict with keyCustomer\n", " customer = row[6].a.string\n", " launch_dict('Customer').append(customer)\n", " #print(customer)\n", " print(customer)\n", " \n", " # Launch outcome\n", " # TODO: Append the launch_outcome into launch_dict with keyLaunch outcome\n", " launch_outcome = list(row[7].strings)[0]\n", " launch_dict('Launch outcome').append(launch_outcome)\n", " #print(launch_outcome)\n", " print(launch_outcome)\n", " \n", " # Booster landing\n", " # TODO: Append the launch_outcome into launch_dict with keyBooster landing\n", " booster_landing = landing_status(row[8])\n", " launch_dict('Booster landing').append(launch_outcome)\n", " #print(booster_landing)\n", " print(booster_landing)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "After you have fill in the parsed launch record values intolaunch_dict, you can create a dataframe from it.\n" ] }, { "cell_type": "code", "execution_count": 24, "metadata": { "tags": [] }, "outputs": [ { "name": "stdout", "output_type": "stream", "text": [ "Empty DataFrame\n", "Columns: [Flight No., Launch site, Payload, Payload mass, Orbit, Customer, Launch outcome, Version Booster, Booster landing, Date, Time]\n", "Index: []\n" ] } ], "source": [ "df=pd.DataFrame(launch_dict)\n", "print(df)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "We can now export it to a CSV for the next section, but to make the answers consistent and in case you have difficulties finishing this lab. \n", "\n", "Following labs will be using a provided dataset to make each lab independent. \n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "df.to_csv('spacex_web_scraped.csv', index=False)\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Authors\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "<a href=\"https://www.linkedin.com/in/yan-luo-96288783/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork865-2023-01-01\">Yan Luo\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "<a href=\"https://www.linkedin.com/in/nayefaboutayoun/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork865-2023-01-01\">Nayef Abou Tayoun\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Change Log\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "| Date (YYYY-MM-DD) | Version | Changed By | Change Description |\n", "| ----------------- | ------- | ---------- | ----------------------- |\n", "| 2021-06-09 | 1.0 | Yan Luo | Tasks updates |\n", "| 2020-11-10 | 1.0 | Nayef | Created the initial version |\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Copyright © 2021 IBM Corporation. All rights reserved.\n" ] } ], "metadata": { "kernelspec": { "display_name": "Python", "language": "python", "name": "conda-env-python-py" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.7.12" } }, "nbformat": 4, "nbformat_minor": 4 }