 cosmoscalibur
commented
6 years ago
cosmoscalibur
commented
6 years ago La verdad no pude encontrar documentación al respecto, pero al ver la opción de configuración de lenguaje de LibreOffice es posible ver una lista de lenguajes por defecto independiente de los locale reconocidos en el sistema operativo y de los paquetes instalados. Por ejemplo, se puede observar en dicha lista que justo las dos variantes regionales discutidas no figuran, así como tampoco figuran otras lenguas (por ejemplo, esta la opción de inglés de filipinas pero no de filipino que también es lengua oficial). Me atrevería a afirmar que si la variante del corrector de ortografía no coincide con las opciones de lenguaje predefinidas en LibreOffice, simplemente no será reconocida.
Aún así, creo que la generación de las variantes (ANY, US, PH e incluso GQ si aparecen aportes) vale la pena, no como extensión de LibreOffice pero si al menos los archivos planos que pueden ser usados en editores que permitan la configuración con estos.
 olea
olea
 RickieES
RickieES
Caolán me ha lanzado una duda que me ha dejado bastante sorprendido refiriéndose a la localización es_PH: https://src.fedoraproject.org/rpms/mythes-es/pull-request/1#comment-4290
Hasta donde he podido descubrir cada código local debe estar oficialmente registrado y en particular no encuentro rastro del es_PH.
Pero, ya peor, me he puesto a hacer alguna comprobación en mi sistema y observo que en particular LibreOffice no maneja varios de los diccionarios instalados:
como se comprueba en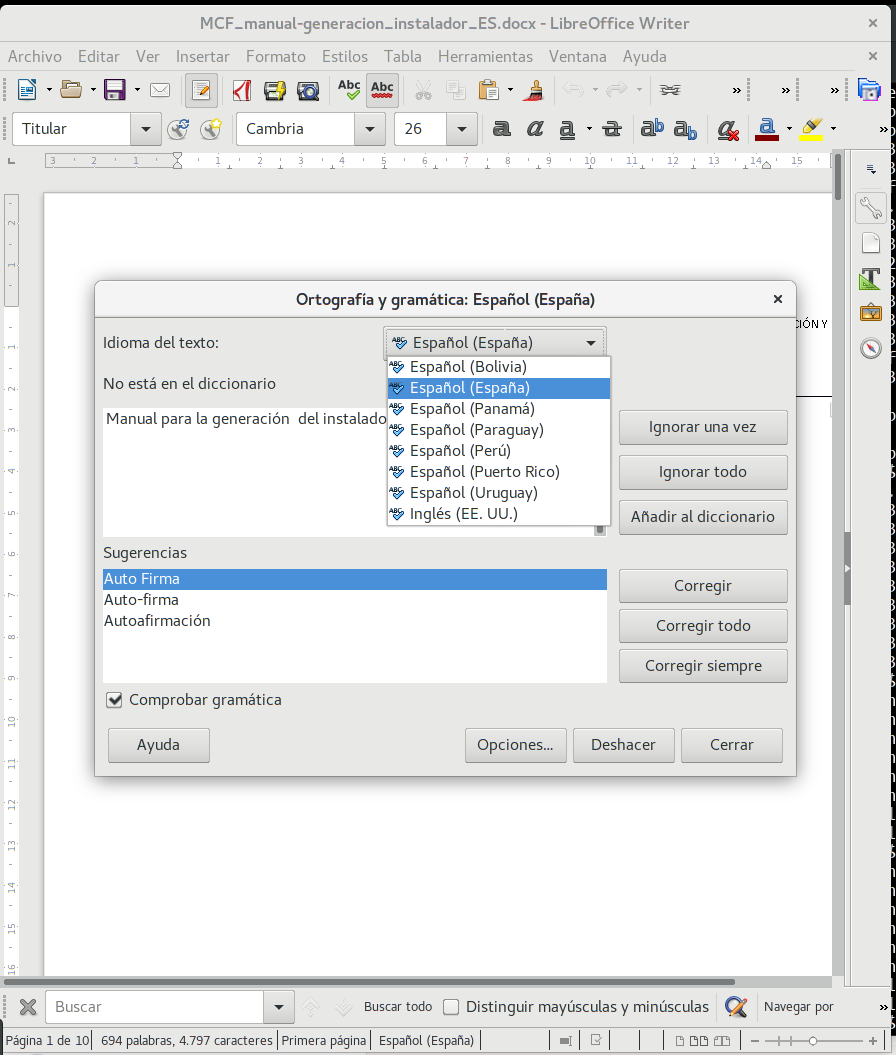
Obsérvese que LO no parece usar los diccionarios de ANY, es_US ni es_PH.
Todo esto ussando libreoffice-writer-5.3.7.2-6.fc26.x86_64 y las versiones 2.3 de los diccionarios:
Me es muy complicado encontrar bibliografía de referencia. En particular de ISO 639-*, que es pagoware. Al menos en los código
Por ejemplo en la localización en libstdc++ sí se menciona es_US pero no es_PH.
Ídem interrogando la orden locale (en Linux):
[...]
Tras mucho arrebuscar creo que he encontrado una buena referencia: en el «CLDR - Unicode Common Locale Data Repository» http://cldr.unicode.org/. Particularmente en:
https://www.unicode.org/repos/cldr/tags/release-32-0-1/common/main/, a su vez publicados en https://unicode.org/Public/cldr/1.8.0/core.zip y efectivamente para lengua española tendríamos los siguentes códigos: es_AR, es_BO, es_BR, es_BZ, es_CL, es_CO, es_CR, es_CU, es_DO, es_EA, es_EC, es_ES, es_GQ, es_GT, es_HN, es_IC, es_MX, es_NI, es_PA, es_PE, es_PH, es_PR, es_PY, es_SV, es_US, es_UY y es_VE
además de: es y es_419 que no acabo de saber como tenerlos en cuenta exactamente. Tampoco es igual la manera de presentar los contenidos en https://www.unicode.org/repos/cldr/tags/release-32-0-1/common/main/ y en https://unicode.org/Public/cldr/1.8.0/core.zip. Parece que en el primero las configuraciones en cada fichero son completas por código local mientras que en el segundo parece que cada código local contiene las diferencias de configuración respecto al general es.xml.
Conclusiones
Pues después de tanto divagar llego hasta: