 sbinet
commented
4 years ago
sbinet
commented
4 years ago uproot started as a "conversion" of groot (at the time called rootio) from Go to Python.
groot has a bit of documentation about the ROOT file format:
extracted from ROOT's "extensive" one.
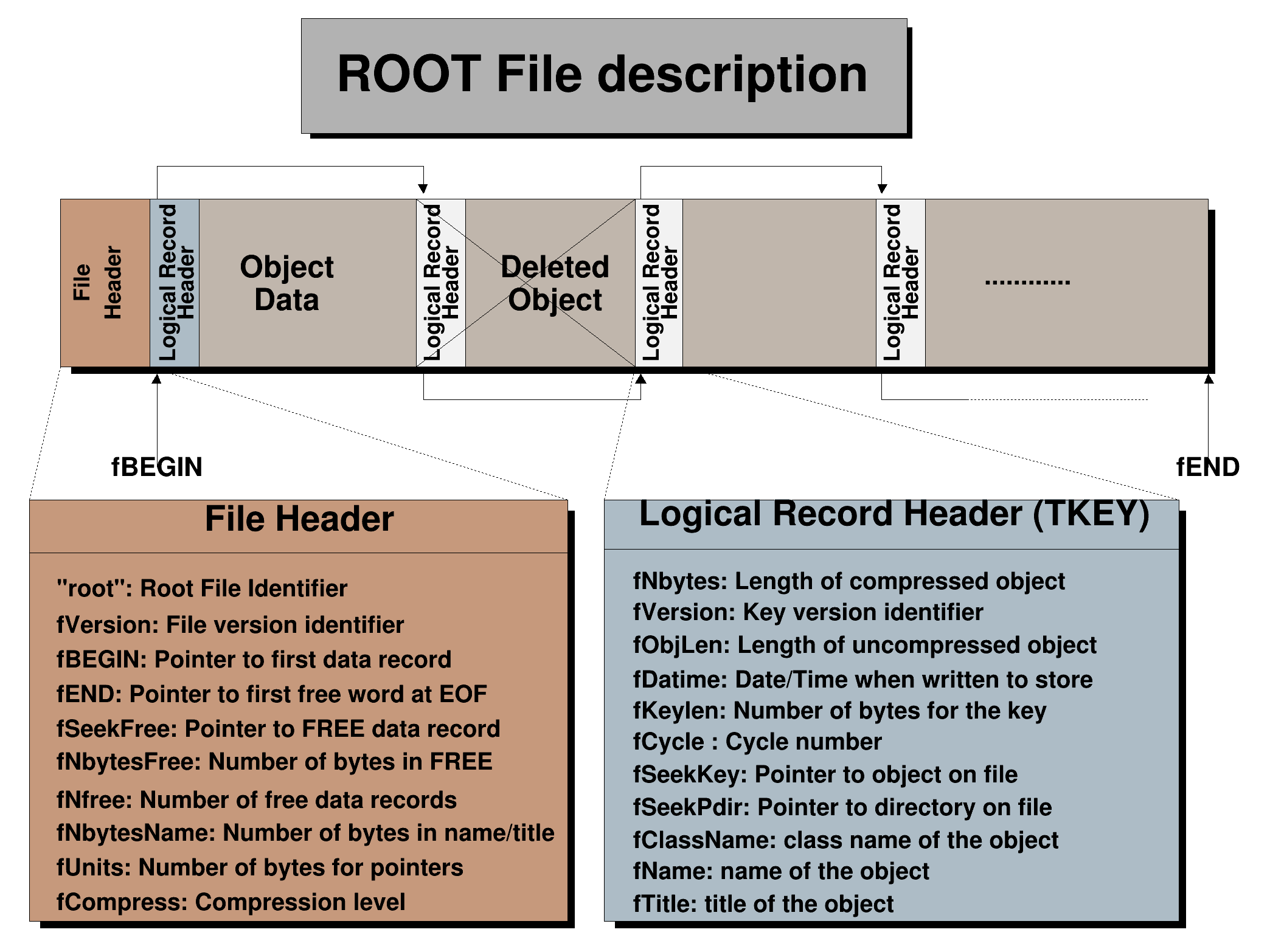
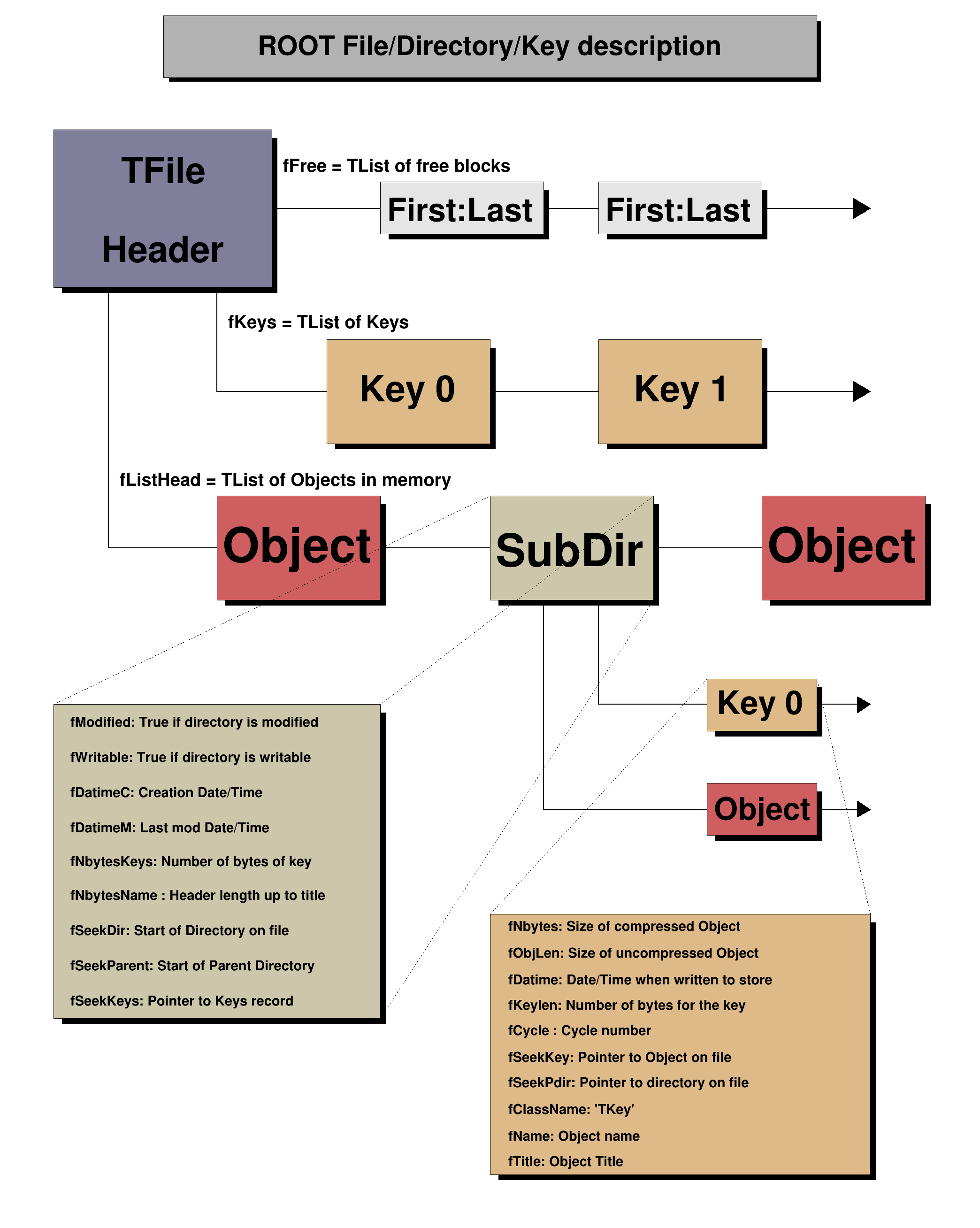
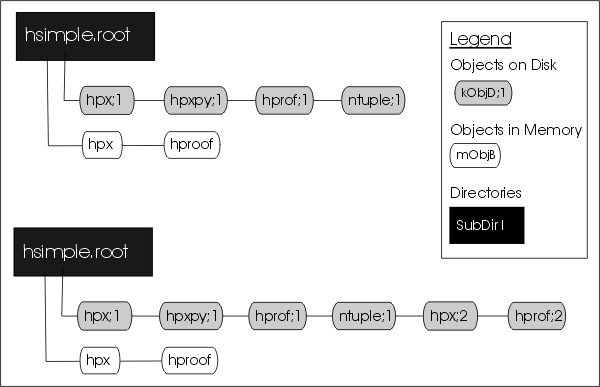
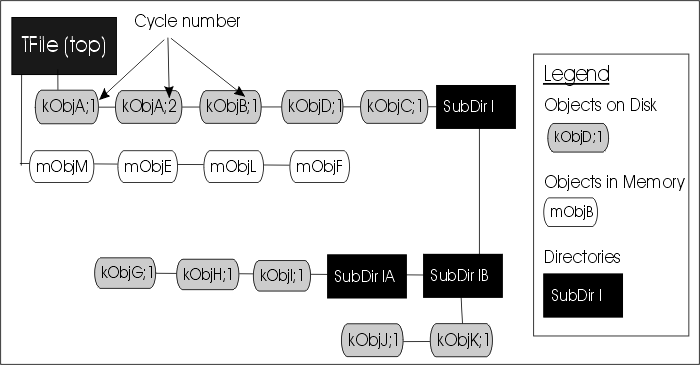
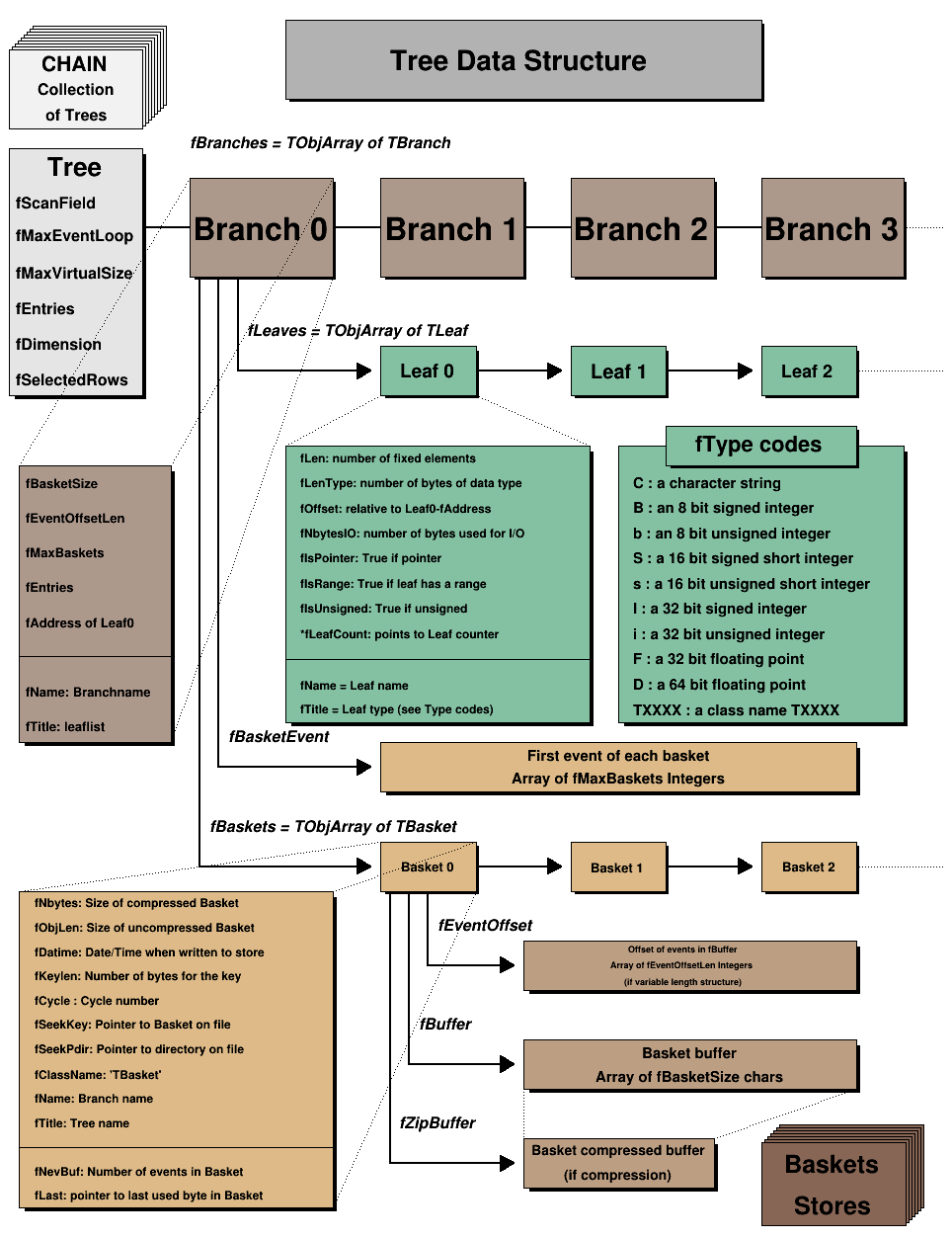
that's, of course, nowhere close from a very detailed and robust specification, and, unfortunately, the ROOT devs explicitly said they didn't want to commit to that kind of thing.
 tamasgal
tamasgal jpivarski
jpivarski cbourjau
cbourjau oschulz
oschulz
Are there any plans to consolidate all the immensely valuable information Jim and all the other people have collected about the ROOT binary dataformat and put it into a format description document? I am very well aware of the fact that this is really something the ROOT developers should provide, but as far as I know, there is no publicly available information other than the source code of ROOT. Please(!) correct me if I am wrong!
I am asking because I am thinking about a Julia "uproot" project as well and such a document would of course be tremendously helpful since uproot of course fully utilises the Python language and numpy features, so the code is very tailored and thus it's not so straight forward to get a big picture.
I am also willing to help to maintain such a document.