 glemaitre
commented
4 years ago
glemaitre
commented
4 years ago I cannot look at this right now in details but pinging @agramfort @GaelVaroquaux @jeromedockes
Closed rnburn closed 4 years ago
glemaitre
commented
4 years ago I cannot look at this right now in details but pinging @agramfort @GaelVaroquaux @jeromedockes
 jeromedockes
commented
4 years ago
jeromedockes
commented
4 years ago Indeed the RidgeCV does LOOCV, computed efficiently as in
Rifkin, Ryan M., and Ross A. Lippert. "Notes on regularized least squares." (2007).
(which does not mention Generalized Cross Validation)
It seems the documentation misuses the term "GCV"?
(btw, looking at the docstring of RidgeClassifierCV, it also contains an outdated comment:
" Currently, only the n_features > n_samples case is handled efficiently")
 rnburn
commented
4 years ago
rnburn
commented
4 years ago The short-term fix might be to update the docs.
But GCV is generally considered to be the better metric for setting regularizers. Quoting from Golub, Heath, Wahba:
At the time of this writing, the only other methods we know of for estimating λ from the data without knowledge of or an estimate of σ^2, are PRESS and maximum likelihood, to be described. We shall indicate why GCV can be generally better than either.
(By PRESS they mean LOOCV)
If you compare the performance on the pollution dataset, for example, you'll see it does slightly better than LOOCV (see notebook).

So you might consider switching to it or supporting both GCV and LOOCV
 TomDLT
commented
4 years ago
TomDLT
commented
4 years ago The confusion seems to be pretty old https://github.com/scikit-learn/scikit-learn/pull/57#issuecomment-703343.
The short-term fix might be to update the docs.
Yes, we should first fix the documentation before considering adding GCV.
 isunitha98selvan
commented
4 years ago
isunitha98selvan
commented
4 years ago @TomDLT I can fix up the documentation. This is my first time contributing to sklearn.
TomDLT
commented
4 years ago @isunitha98selvan Yes please, and welcome !
 Villareally
commented
3 years ago
Villareally
commented
3 years ago Thanks, you are so genius
Villareally
commented
3 years ago Thanks, you are so genius, I am finding how to solve GCV function.Thanks a lot
rnburn
commented
3 years ago You're welcome!
If you're looking at cross-validation, you might also be interested this other work I was doing
https://arxiv.org/abs/2011.10218
It extends the approach for optimizing LOOCV / GCV to optimizing Approximate Leave-one-out Cross-validation, allowing you to use it for Generalized Linear Models (e.g. Logistic regression, Poisson regression, etc). TLDR: you can use second-order information to efficiently dial in to the exact hyperparameters that optimize Approximate LOOCV (which is nearly as good as LOOCV).
 agramfort
commented
3 years ago
agramfort
commented
3 years ago I would be super interested in available benchmarking code on this.
rnburn
commented
3 years ago There are benchmarking results in the paper. (Obviously those are sensitive to system setup and I didn't spend a lot of time tinkering).
But if you want to benchmark it yourself, I set up this repo
https://github.com/rnburn/peak-engines
that makes the (Approximate) LOOCV optimization approach available for use as a python module. You can install with pip.
Villareally
commented
3 years ago You're welcome!
If you're looking at cross-validation, you might also be interested this other work I was doing
https://arxiv.org/abs/2011.10218
It extends the approach for optimizing LOOCV / GCV to optimizing Approximate Leave-one-out Cross-validation, allowing you to use it for Generalized Linear Models (e.g. Logistic regression, Poisson regression, etc). TLDR: you can use second-order information to efficiently dial in to the exact hyperparameters that optimize Approximate LOOCV (which is nearly as good as LOOCV).
Ok,I will read the project you did. Thanks a lot.
rnburn
commented
3 years ago @agramfort Here's a quick benchmark you can run comparing ALO optimization to a standard grid search for logistic regression.
First, pip install peak-engines
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegressionCV
import peak_engines
import time
X, y = load_breast_cancer(return_X_y=True)
X = StandardScaler().fit_transform(X)
t1 = time.time()
model = peak_engines.LogisticRegressionModel()
model.fit(X, y) # Finds the value of C that optimize Approximate Leave-one-out Cross-validation.
# See https://arxiv.org/abs/1801.10243 for a description of ALO.
t2 = time.time()
print('***** approximate leave-one-out optimization')
print('C = ', model.C_[0])
print('time = ', (t2 - t1))
print('***** grid search')
t1 = time.time()
model = LogisticRegressionCV(scoring='neg_log_loss', random_state=0)
model.fit(X, y)
t2 = time.time()
print('C = ', model.C_[0])
print('time = ', (t2 - t1))YMMV, but running it on my computer gives
***** approximate leave-one-out optimization
C = 0.6655139682151202
time = 0.007418155670166016
***** grid search
C = 0.3593813663804626
time = 0.25518298149108887@agramfort Here's a quick benchmark you can run comparing ALO optimization to a standard grid search for logistic regression.
First,
pip install peak-enginesfrom sklearn.datasets import load_breast_cancer from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegressionCV import peak_engines import time X, y = load_breast_cancer(return_X_y=True) X = StandardScaler().fit_transform(X) t1 = time.time() model = peak_engines.LogisticRegressionModel() model.fit(X, y) # Finds the value of C that optimize Approximate Leave-one-out Cross-validation. # See https://arxiv.org/abs/1801.10243 for a description of ALO. t2 = time.time() print('***** approximate leave-one-out optimization') print('C = ', model.C_[0]) print('time = ', (t2 - t1)) print('***** grid search') t1 = time.time() model = LogisticRegressionCV(scoring='neg_log_loss', random_state=0) model.fit(X, y) t2 = time.time() print('C = ', model.C_[0]) print('time = ', (t2 - t1))YMMV, but running it on my computer gives
***** approximate leave-one-out optimization C = 0.6655139682151202 time = 0.007418155670166016 ***** grid search C = 0.3593813663804626 time = 0.25518298149108887
Thank you for your program, yet when I use pip install peak-engines, it called error,
 I can run other pip install well, want to use the code you write, can you solve it?
Or the setuptools is both ok
I can run other pip install well, want to use the code you write, can you solve it?
Or the setuptools is both ok
rnburn
commented
3 years ago Yeah, sorry. It doesn't support windows yet, only mac and linux.
Villareally
commented
3 years ago Yeah, sorry. It doesn't support windows yet, only mac and linux.
ok, hope can support windows one day
Describe the bug
The documentation for RidgeCV says the following:
But 1) it's using the LOOCV not the GCV and 2) GCV isn't "an efficient form of LOOCV".
GCV is the leave-one-out cross-validation of a rotation of the original regression problem
where Q is a unitary rotation matrix
chosen so as to circularize the matrix
X' X'^HSee
or this blog post.
There are efficient ways to compute the LOOCV, but GCV is a different metric and the rotation is designed to handle certain problem cases with performing LOOCV on X and y directly (See the cited sources for an example where LOOCV is problematic).
Steps/Code to Reproduce
We can confirm that RidgeCV isn't using GCV by putting together an example.
def compute_ridge_regression_prediction(X, y, alpha, X_test): z = np.dot(np.conj(X.T), y) L = compute_l_matrix(X, alpha) beta = scipy.linalg.solve_triangular(L, z, lower=True) beta = scipy.linalg.solve_triangular(np.conj(L.T), beta, lower=False) return np.dot(X_test, beta)
def compute_loocv_impl(X, y, alpha): result = 0 for train_indexes, test_indexes in LeaveOneOut().split(X): X_train, X_test = X[train_indexes], X[test_indexes] y_train, y_test = y[train_indexes], y[test_indexes] y_pred = compute_ridge_regression_prediction(X_train, y_train, alpha, X_test) result += np.abs(y_test[0] - y_pred[0])**2 return result / len(y)
def compute_loocv(X, y, alpha, fit_intercept=True): n, k = X.shape if fit_intercept: alpha = np.array([alpha]k + [0]) X = np.hstack((X, np.ones((n, 1)))) k +=1 else: alpha = np.ones(k)alpha return compute_loocv_impl(X, y, alpha)
Note: depending on how you treat the intercept, this function will be equivalent to this more common formula for GCV
and is available at NCSU
We'll use this package to find the optimum alpha for LOOCV and GCV and verify they're different
outputs:
Plot the functions across a range of alphas.
outputs: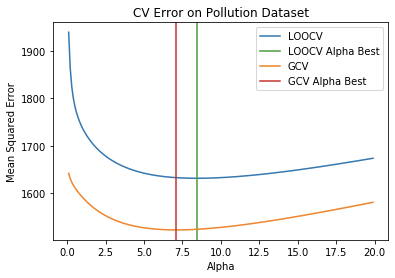
Build a RidgeCV model and confirm it's using LOOCV not GCV
outputs:
I also put together this notebook that combines all the steps.
Expected Results
If RidgeCV used GCV as claimed, step 6 would print
7.095235374911837.Actual Results
It printed 8.437006486935175 the LOOCV optimum.
Versions
System: python: 3.7.5 (default, Nov 20 2019, 09:21:52) [GCC 9.2.1 20191008] executable: /usr/bin/python3 machine: Linux-4.9.125-linuxkit-x86_64-with-Ubuntu-19.10-eoan
Python dependencies: pip: 18.1 setuptools: 47.1.1 sklearn: 0.23.1 numpy: 1.16.3 scipy: 1.2.1 Cython: None pandas: 0.24.2 matplotlib: 3.1.1 joblib: 0.16.0 threadpoolctl: 2.1.0
Built with OpenMP: True