 itsderek23
commented
6 years ago
itsderek23
commented
6 years ago @lmansur - agreed. Many performance issues are directly related to the size of the data being operated on. This is often correlated to the current user in the session, current account, etc.
We've started working on a POC for this. No ETA yet, but it's a focus for us.
 lmansur
lmansur


 nathansamson
nathansamson
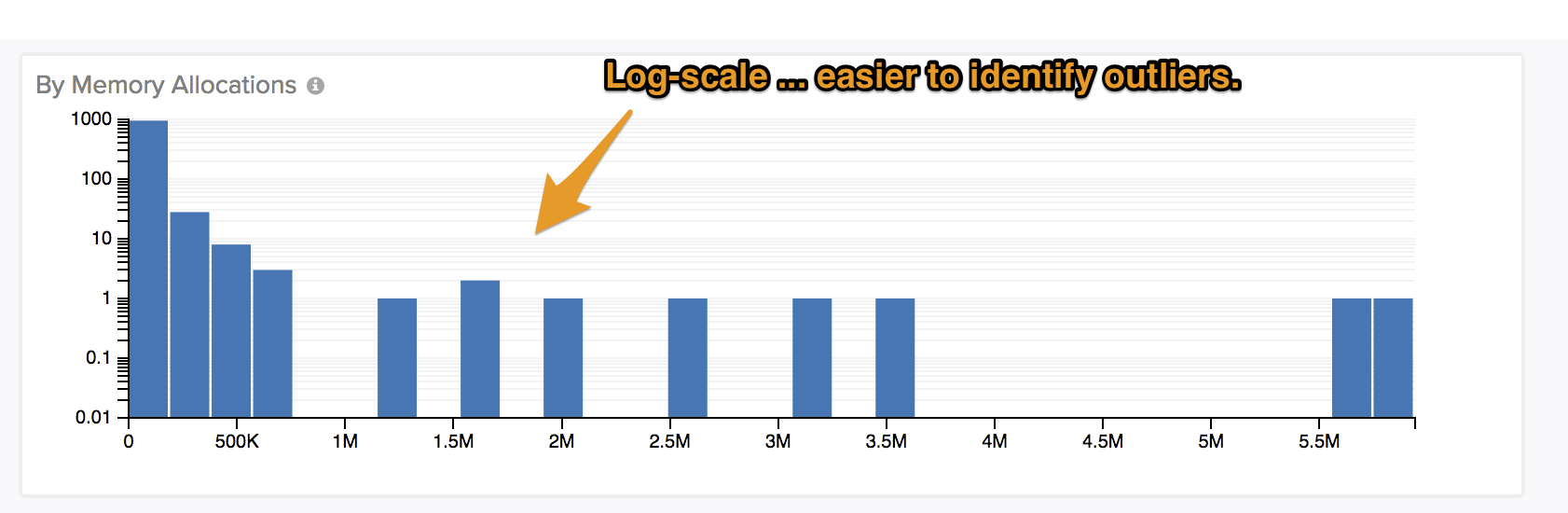
 doutatsu
doutatsu
I have a custom context to differentiate Web requests to API requests. It would be very useful if I could filter my traces by that specific context, since most of the time I want to focus on improving web-related issues first.
This would also be very useful when trying to find a performance issue for a specific User, since I also have a context with their information.