 GeorgeA92
commented
4 years ago
GeorgeA92
commented
4 years ago @ejulio, @Gallaecio
ScrapyAgent._cb_bodydone method.. chooses response class:
https://github.com/scrapy/scrapy/blob/e22a8c8c36e34ffaf12ef9e330624df654582605/scrapy/core/downloader/handlers/http11.py#L395-L400
responsetypes.from_args method performs several checks with following logic:
- default response type is plain
Response, - if scrapy identify something that require another response class instead if plain
Response- another response class will be returned ignoring results of previous checks.
In this case:
.from_headers and .from_filename methods return plain Response class.
method .from_body identified content of this pdf file as text.
As result <class 'scrapy.http.response.text.TextResponse'> will be returned despite results of response headers and url checks:
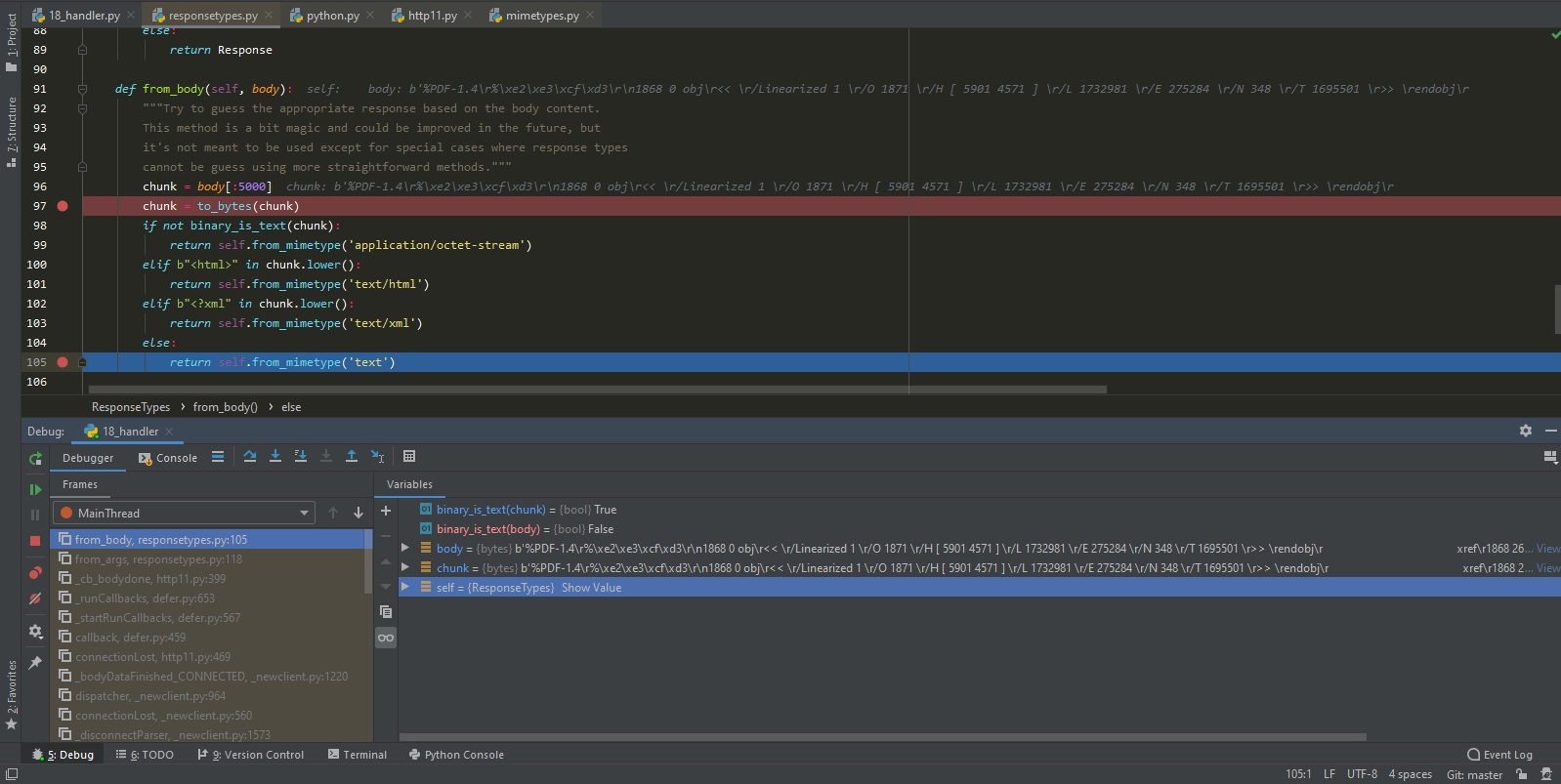 As You can see on the debugger screenshot: this result of
As You can see on the debugger screenshot: this result of .from_body method based on checking only first 5000 bytes of response body while the same check on the whole response body clearly indicate that response is binary.
 kmike
kmike Gallaecio
Gallaecio OmarFarrag
OmarFarrag bchao1
bchao1 nyov
nyov gigatesseract
gigatesseract sakshamb2113
sakshamb2113 deepakdinesh1123
deepakdinesh1123 dukkee
dukkee akshaysharmajs
akshaysharmajs
Description
Binary (file) responses are identified as
TextResponseinstead of a plainResponseinspider.parse.Steps to Reproduce
From this URL https://www.ecb.europa.eu/press/pr/date/2004/html/pr040702.en.html We can get this link https://www.ecb.europa.eu/pub/redirect/pub_5874_en.html (text is
pdf 1692 kB). It redirects to https://www.ecb.europa.eu/pub/pdf/other/developmentstatisticsemu200406en.pdfExpected behavior: [What you expect to happen]
In the spider,
isinstance(response, TextResponse)should beFalse.Actual behavior: [What actually happens]
In the spider,
isinstance(response, TextResponse)isTrue, even though theContent-Typeheader isapplication/pdf.Versions
Extra info
Probably we should handle known binary types in
Content-Typehere https://github.com/scrapy/scrapy/blob/master/scrapy/responsetypes.py At least,application/pdfshould be in the list. It would be nice to add some mechanism to allow developers to extend the mapping on the fly, as we can get new types in a project basis and it would be easier update the desired behavior.