 maxwill-max
commented
3 years ago
maxwill-max
commented
3 years ago I tried using proxies, residentail proxies, without proxies, changing headers but requests work and scrapy gets 403
Closed maxwill-max closed 3 years ago
maxwill-max
commented
3 years ago I tried using proxies, residentail proxies, without proxies, changing headers but requests work and scrapy gets 403
maxwill-max
commented
3 years ago It can be reproduced by sending a request to https://www.dnb.com/business-directory/industry-analysis.arts-entertainment-recreation-sector.html from both python-requests and scrapy with the headers mentioned above
maxwill-max
commented
3 years ago I setup a proxy in my localhost and scrapy gets 200 and returns correct data but if i remove the localhost proxy or use any direct proxies, scrapy gets 403.
maxwill-max
commented
3 years ago requests without proxies and requests with direct proxy are returned with 403 by scrapy. python-requests work fine on all cases but poor scrapy isn't :(
 wRAR
commented
3 years ago
wRAR
commented
3 years ago In [1]: h = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
...: 86.0.4240.193 Safari/537.36', 'accept-encoding': 'gzip, deflate, br', 'accept': 'text/html,application/xhtml
...: +xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9',
...: 'Connection': 'keep-alive', 'accept-language': 'en-US,en;q=0.9,de;q=0.8'}
In [3]: r = scrapy.Request('https://www.dnb.com/business-directory/industry-analysis.arts-entertainment-recreation-s
...: ector.html', headers=h)
In [4]: fetch(r)
2020-11-12 13:25:44 [scrapy.core.engine] INFO: Spider opened
2020-11-12 13:25:45 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.dnb.com/business-directory/industry-analysis.arts-entertainment-recreation-sector.html> (referer: None)Looks like it's not a Scrapy problem or you didn't provide necessary details to reproduce this.
maxwill-max
commented
3 years ago  I tried with and without proxy
I tried with and without proxy
maxwill-max
commented
3 years ago works on requests with and without proxy. I am setting up a new environment with fresh python and scrapy installationon
wRAR
commented
3 years ago Your IP may be banned (especially possible if you are setting the proxy incorrectly).
maxwill-max
commented
3 years ago I thought so too and I just changed the url and scraped this https://httpbin.org/ip it returned proxy ip. and python-requests without proxy works
maxwill-max
commented
3 years ago checked on new environment. scrapy still returns 403 just for this site
maxwill-max
commented
3 years ago 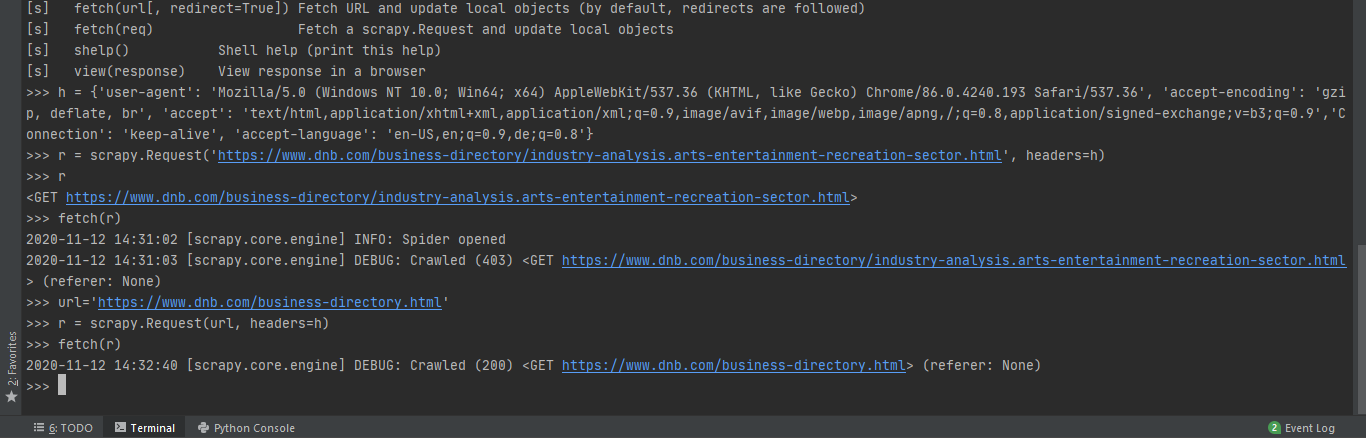 this page https://www.dnb.com/business-directory.html works but no other page works
this page https://www.dnb.com/business-directory.html works but no other page works
 Gallaecio
commented
3 years ago
Gallaecio
commented
3 years ago Have you compared https://httpbin.org/headers from each solution? If the IP is the same, I bet there are differences there.
maxwill-max
commented
3 years ago yes. I compared headers and even tried different headers including referer, host, etc.
Gallaecio
commented
3 years ago Can you share the headers that requests generates and the ones that Scrapy generates when you try to reproduce requests?
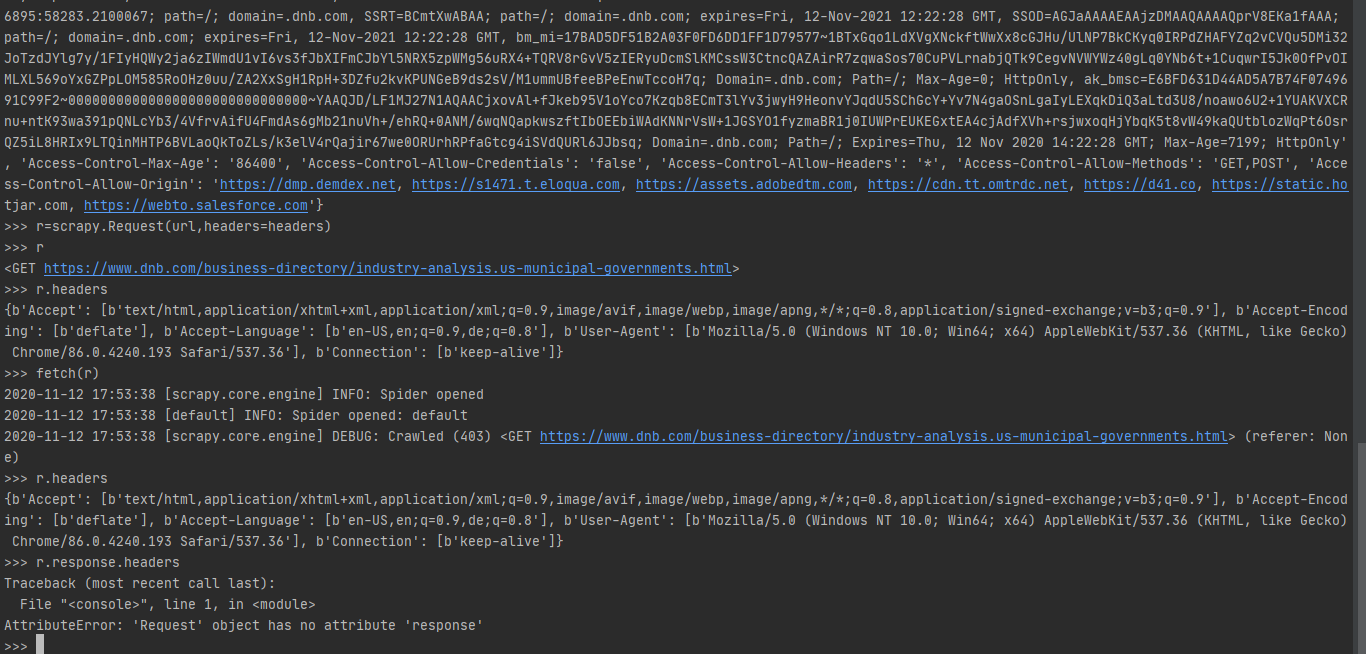
maxwill-max
commented
3 years ago yes
maxwill-max
commented
3 years ago 
wRAR
commented
3 years ago That's response headers, not request headers returned by https://httpbin.org/headers
maxwill-max
commented
3 years ago 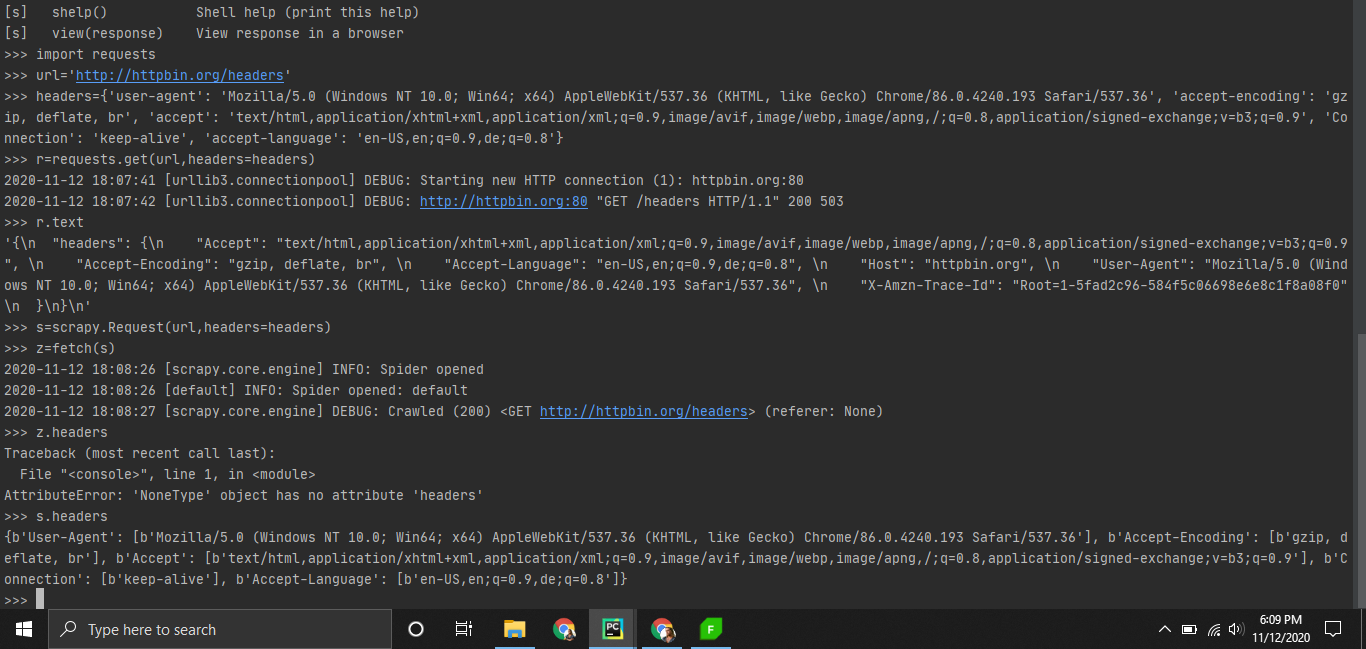
Gallaecio
commented
3 years ago s.headers is still the headers of the scrapy.Request object, not the response of httpbin.org/headers.maxwill-max
commented
3 years ago i am sorry. I dont know how to format code here thats why i posted screenshot. Will post text from now on scrapy returns 200 when fiddler is set as a proxy. I immediately removed it and tried, scrappy returned 403. let me send the response of httpbin.org/headers.
maxwill-max
commented
3 years ago >>> headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36', 'accept-encoding':
'gzip, deflate, br', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
', 'Connection': 'keep-alive', 'accept-language': 'en-US,en;q=0.9,de;q=0.8'}
>>> s=scrapy.Request(url,headers=headers)
>>> fetch(s)
2020-11-12 18:19:35 [scrapy.core.engine] INFO: Spider opened
2020-11-12 18:19:35 [default] INFO: Spider opened: default
2020-11-12 18:19:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://httpbin.org/headers> (referer: None)
>>> response.text
'{\n "headers": {\n "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=
0.9", \n "Accept-Encoding": "gzip, deflate, br", \n "Accept-Language": "en-US,en;q=0.9,de;q=0.8", \n "Host": "httpbin.org", \n "User-Agent": "Mozilla/5.0
(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36", \n "X-Amzn-Trace-Id": "Root=1-5fad2f60-3d15f67952307109
45146197"\n }\n}\n'
>>> import requests
>>> requests.get(url,headers=headers).text
2020-11-12 18:22:29 [urllib3.connectionpool] DEBUG: Starting new HTTP connection (1): httpbin.org:80
2020-11-12 18:22:30 [urllib3.connectionpool] DEBUG: http://httpbin.org:80 "GET /headers HTTP/1.1" 200 503
'{\n "headers": {\n "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=
0.9", \n "Accept-Encoding": "gzip, deflate, br", \n "Accept-Language": "en-US,en;q=0.9,de;q=0.8", \n "Host": "httpbin.org", \n "User-Agent": "Mozilla/5.0
(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36", \n "X-Amzn-Trace-Id": "Root=1-5fad300e-60f4056e258ce08f
1fde6284"\n }\n}\n'
>>>
it works. thank you very much @Gallaecio and @wRAR
wRAR
commented
3 years ago Proxies should forward your HTTPS traffic as is.
maxwill-max
commented
3 years ago Thank you. I changed the proxy from http to https and it works. Thank you again @Gallaecio @wRAR
heres it my headers for both python requests and scrapy {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36', 'accept-encoding': 'gzip, deflate, br', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Connection': 'keep-alive', 'accept-language': 'en-US,en;q=0.9,de;q=0.8'}
the response header i get from python requests(status code 200) {'Server': 'Apache', 'RTSS': '1-2-62', 'X-Frame-Options': 'SAMEORIGIN', 'X-Content-Type-Options': 'nosniff', 'X-Powered-By': 'Jetty(9.2.9.v20150224)', 'Vary': 'Accept-Encoding', 'Strict-Transport-Security': 'max-age=31536000; includeSubDomains; preload;', 'Content-Security-Policy': 'upgrade-insecure-requests;', 'Content-Type': 'text/html; charset=UTF-8', 'Cache-Control': 'private, max-age=0, proxy-revalidate, no-store, no-cache, must-revalidate', 'Expires': 'Fri, 15 May 2020 02:14:12 GMT', 'Pragma': 'no-cache', 'Content-Encoding': 'gzip', 'X-Akamai-Transformed': '9 49191 0 pmb=mTOE,2', 'Date': 'Wed, 11 Nov 2020 23:13:02 GMT', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive, Transfer-Encoding', 'Set-Cookie':actual_cookies}
the response header i get from scrapy(status code 403)
{b'Server': [b'AkamaiGHost'], b'Mime-Version': [b'1.0'], b'Content-Type': [b'text/html'], b'Expires': [b'Wed, 11 Nov 2020 23:09:30 GMT'], b'Date': [b'Wed, 11 Nov 202 0 23:09:30 GMT'], b'Access-Control-Max-Age': [b'86400'], b'Access-Control-Allow-Credentials': [b'false'], b'Access-Control-Allow-Headers': [b'*'], b'Access-Control-A llow-Methods': [b'GET,POST'], b'Access-Control-Allow-Origin': [b'https://dmp.demdex.net, https://s1471.t.eloqua.com, https://assets.adobedtm.com, https://cdn.tt.omtr dc.net, https://d41.co, https://static.hotjar.com, https://webto.salesforce.com']}