 fruch
commented
3 years ago
fruch
commented
3 years ago issue is reproduced where running a single decommission only + using a smaller db instance type. thus there are less SMPs and less Stream shards.
Installation details Kernel version:
5.11.6-1.el7.elrepo.x86_64Scylla version (or git commit hash):4.5.dev-0.20210319.abab1d906c with build-id c60f1de6f6a94a2b9a6219edd82727f66aaf8c83Cluster size: 6 nodes (i3.large) OS (RHEL/CentOS/Ubuntu/AWS AMI):ami-0c8a8490cf80a53a0(aws: eu-west-1)Test:
longevity-alternator-streams-with-nemesisTest name:longevity_test.LongevityTest.test_custom_timeTest config file(s):Issue description
====================================
PUT ISSUE DESCRIPTION HERE
====================================
Restore Monitor Stack command:
$ hydra investigate show-monitor a7453f7c-eddb-4777-9cfa-c7931bbcc2f5Show all stored logs command:$ hydra investigate show-logs a7453f7c-eddb-4777-9cfa-c7931bbcc2f5Test id:
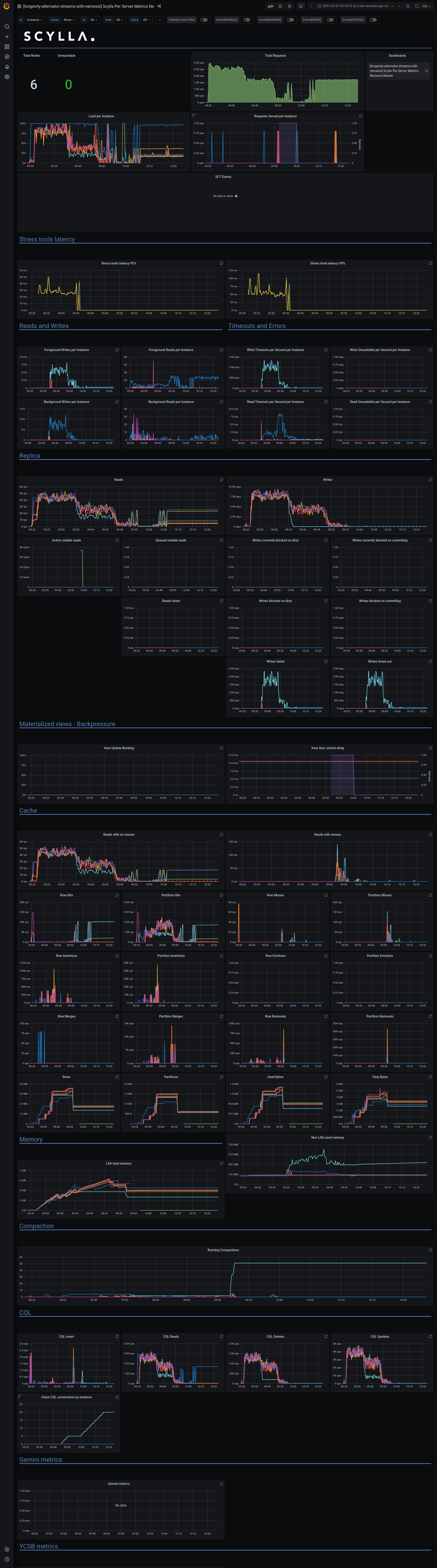
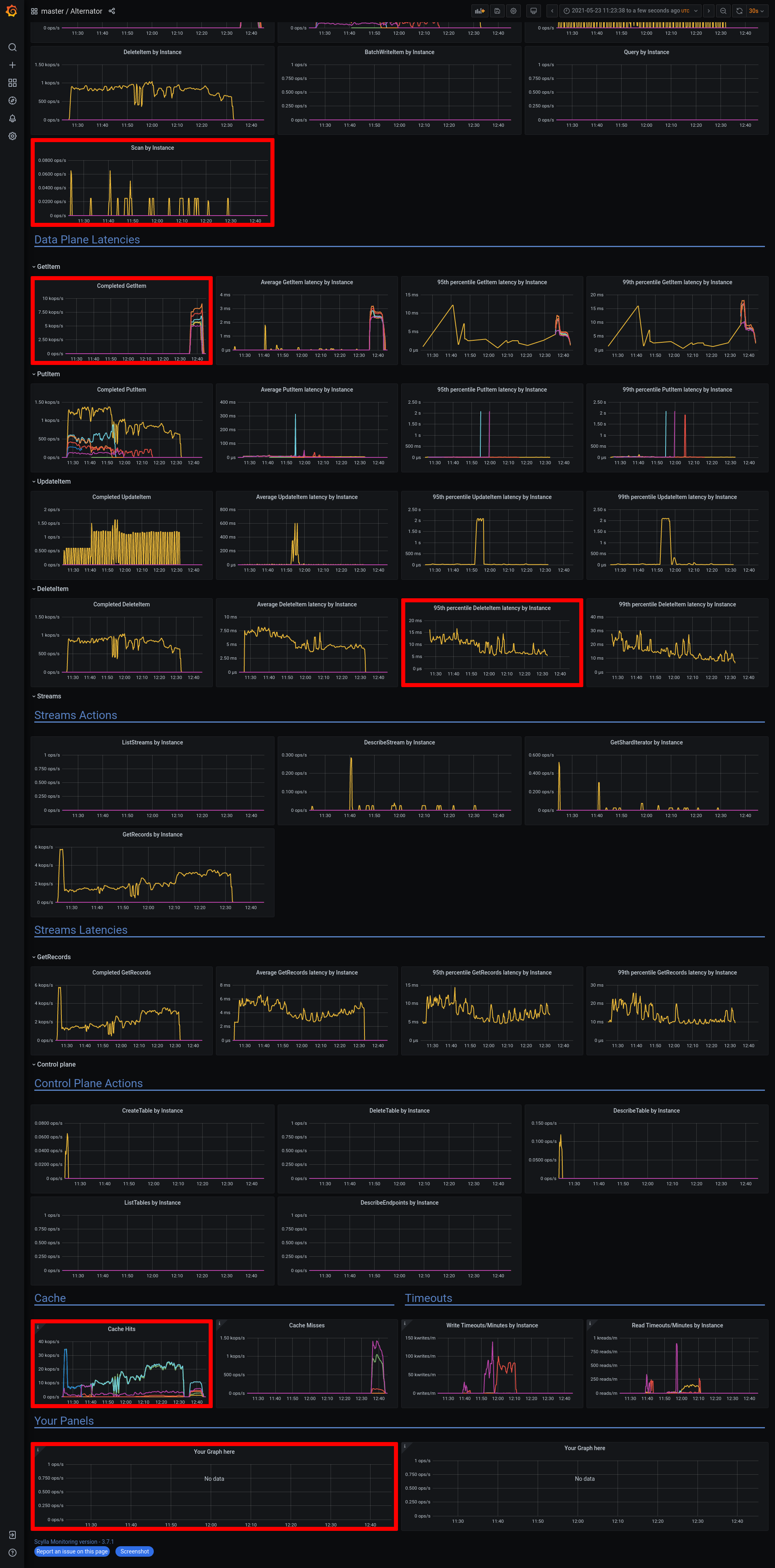
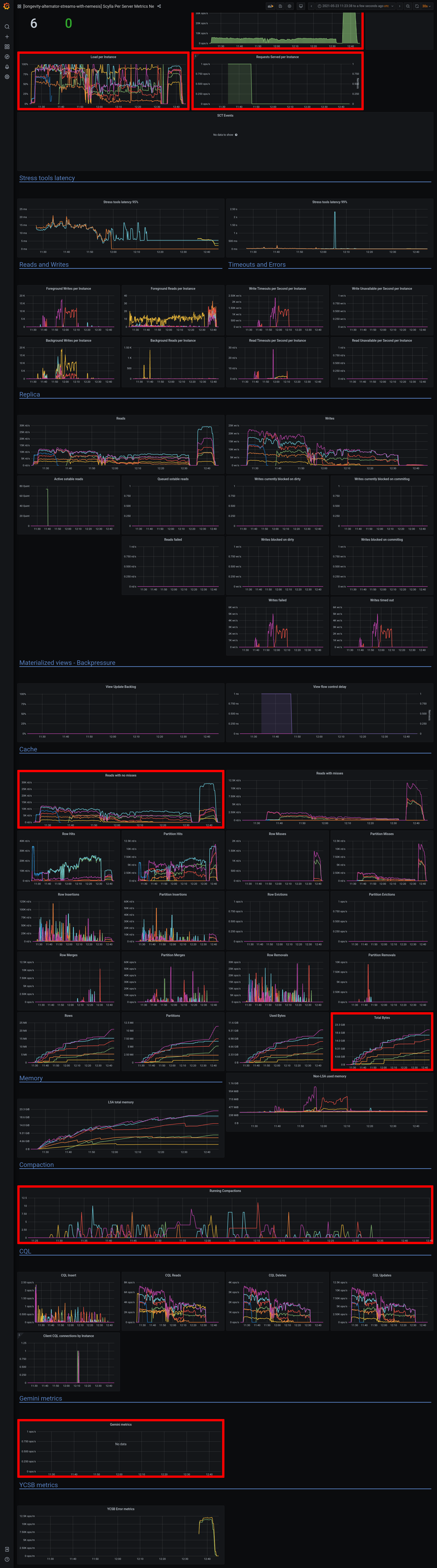
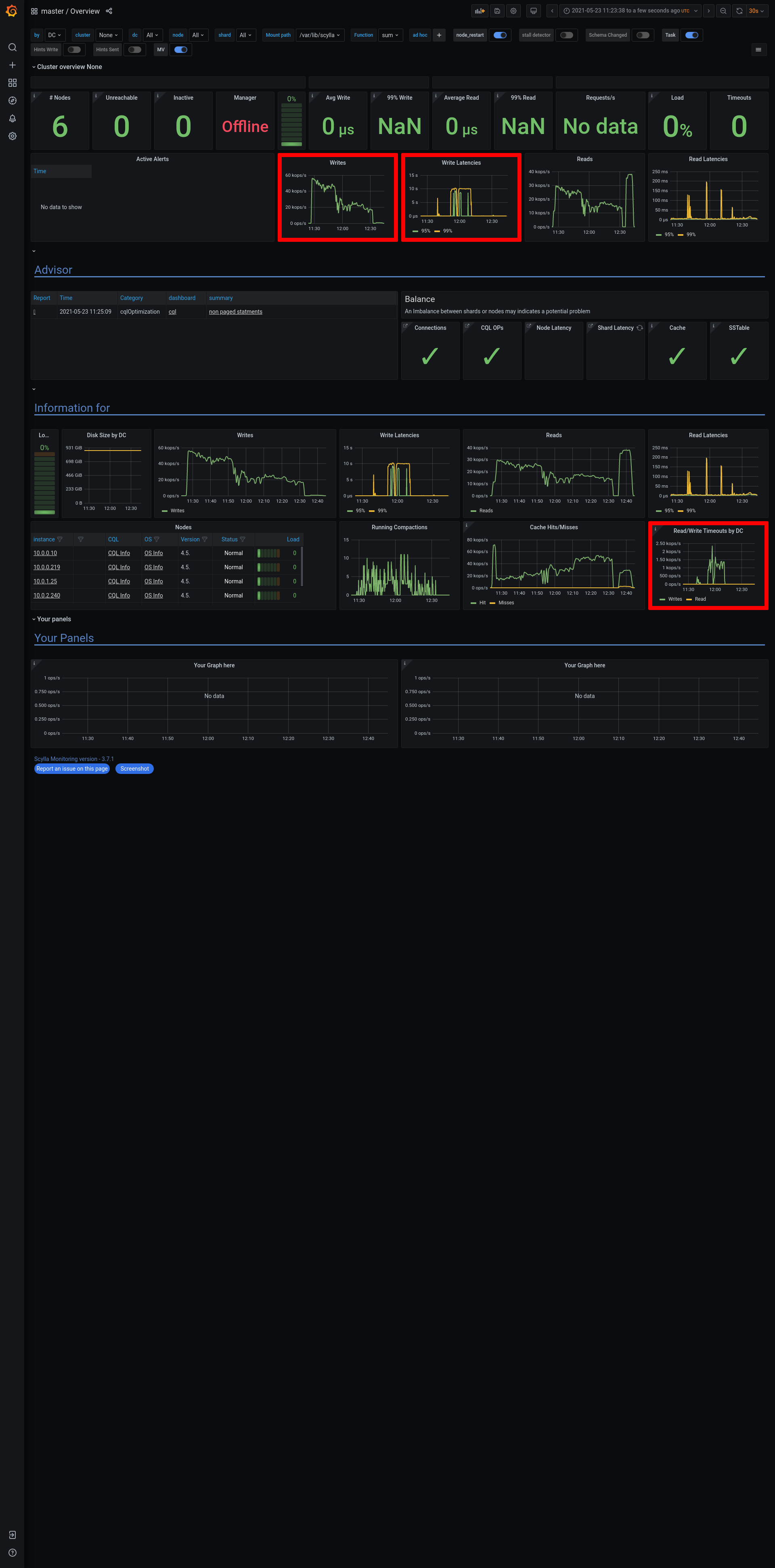
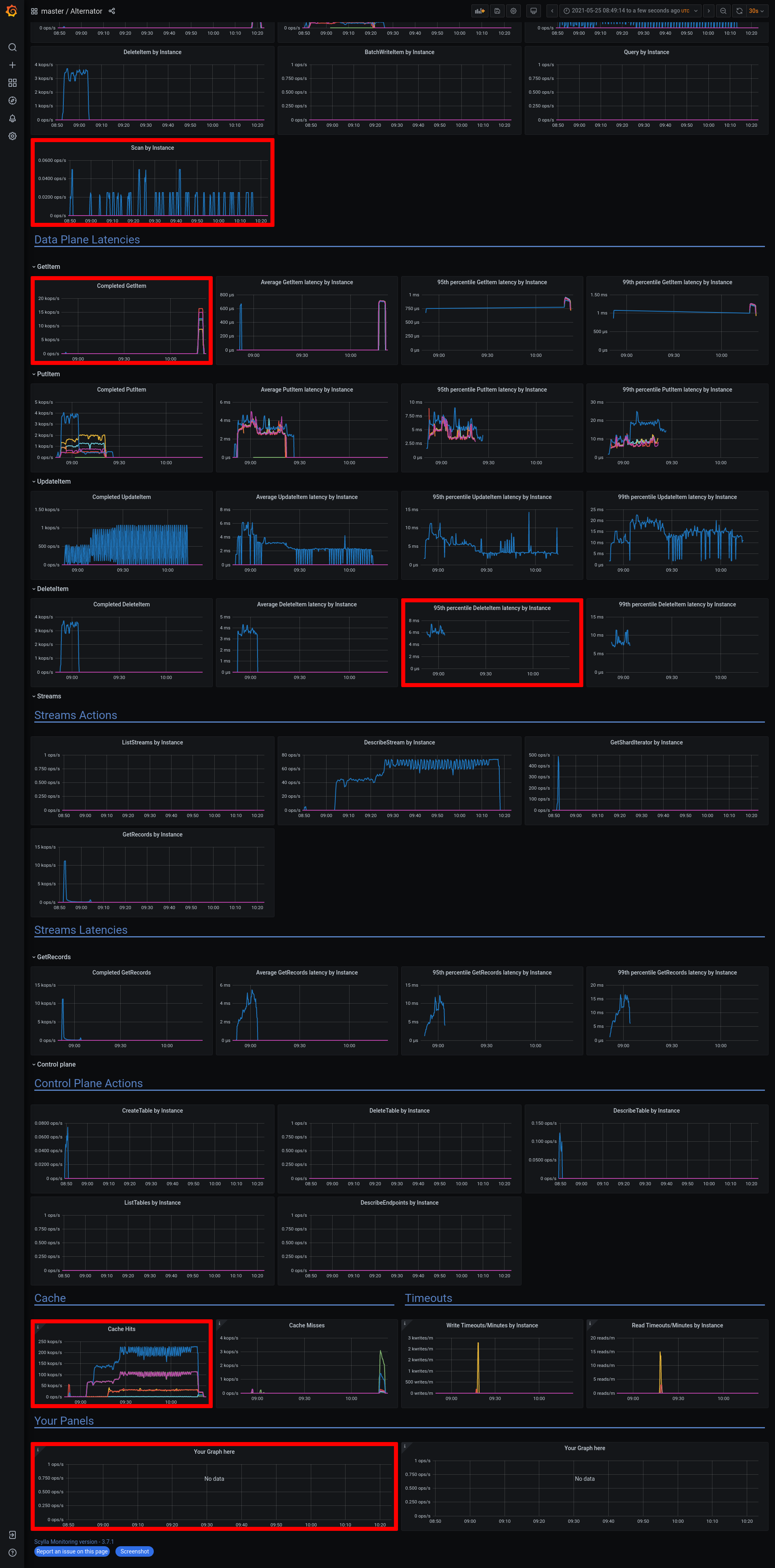
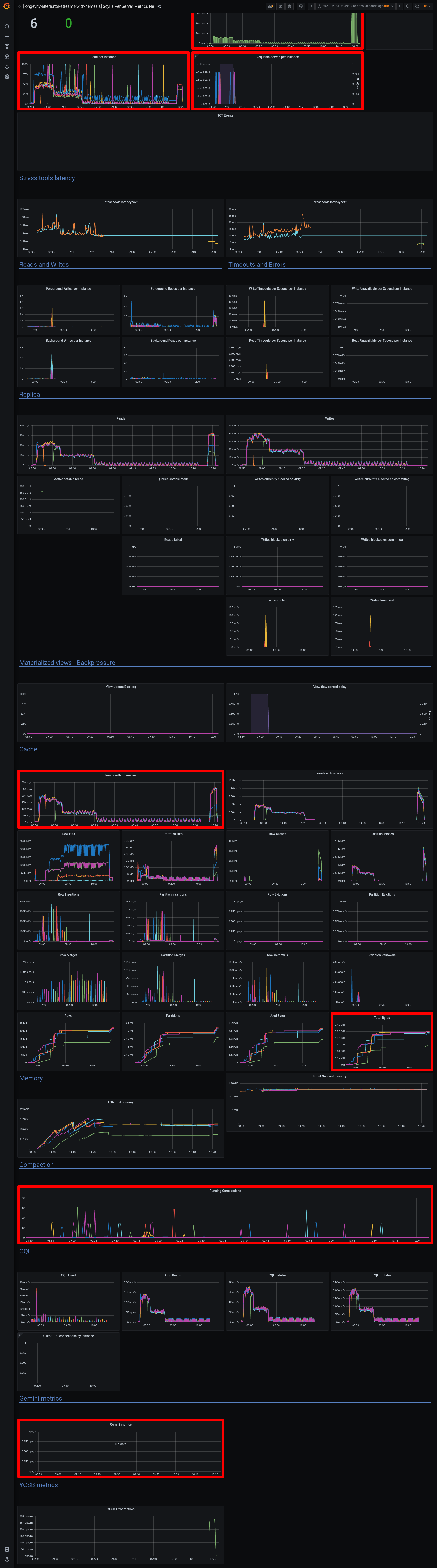
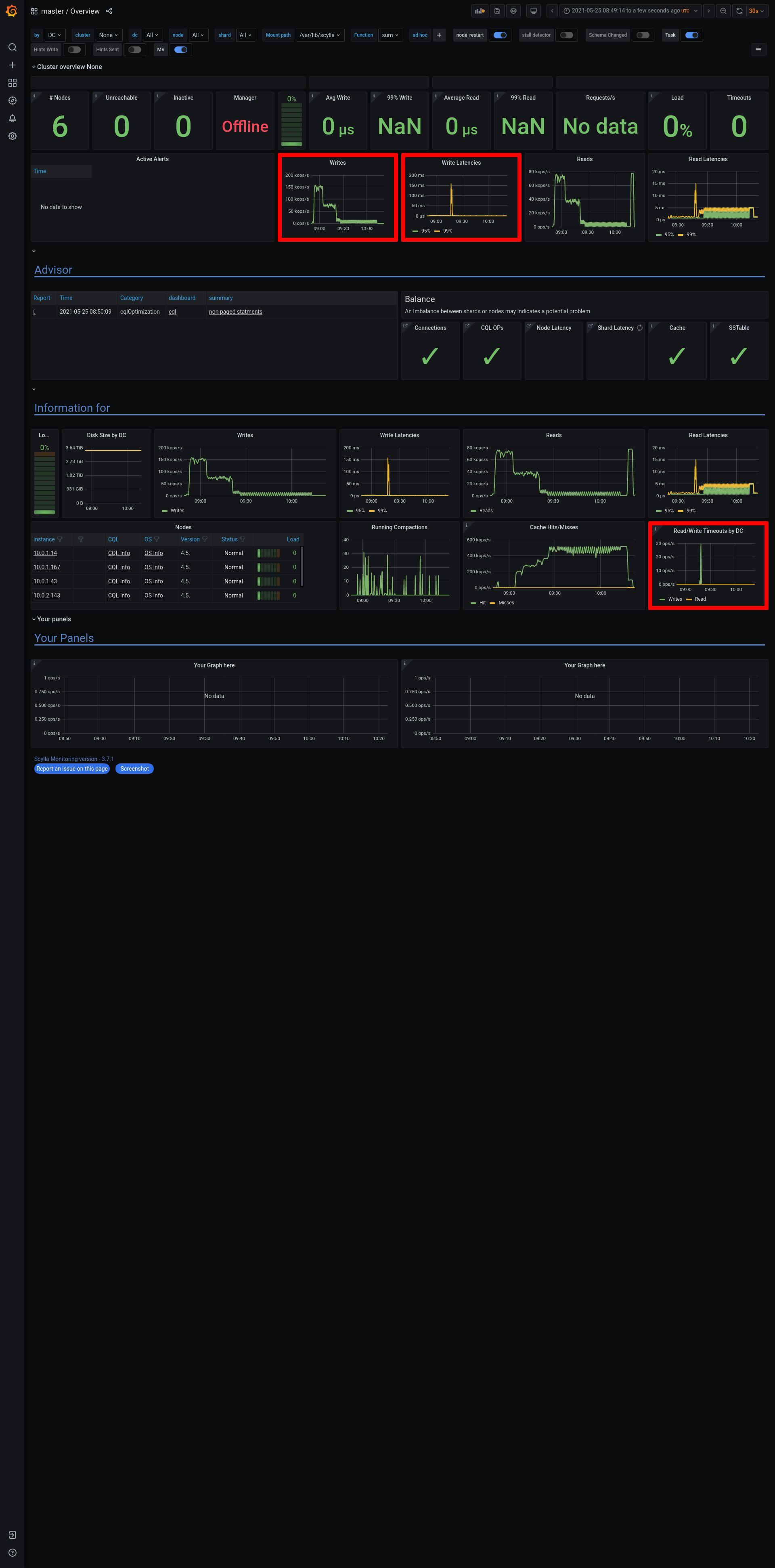
a7453f7c-eddb-4777-9cfa-c7931bbcc2f5Logs: grafana - https://cloudius-jenkins-test.s3.amazonaws.com/a7453f7c-eddb-4777-9cfa-c7931bbcc2f5/20210321_101815/grafana-screenshot-alternator-20210321_102430-alternator-streams-nemesis-stream-w-monitor-node-a7453f7c-1.png grafana - https://cloudius-jenkins-test.s3.amazonaws.com/a7453f7c-eddb-4777-9cfa-c7931bbcc2f5/20210321_101815/grafana-screenshot-longevity-alternator-streams-with-nemesis-scylla-per-server-metrics-nemesis-20210321_102155-alternator-streams-nemesis-stream-w-monitor-node-a7453f7c-1.png grafana - https://cloudius-jenkins-test.s3.amazonaws.com/a7453f7c-eddb-4777-9cfa-c7931bbcc2f5/20210321_101815/grafana-screenshot-overview-20210321_101815-alternator-streams-nemesis-stream-w-monitor-node-a7453f7c-1.png db-cluster - https://cloudius-jenkins-test.s3.amazonaws.com/a7453f7c-eddb-4777-9cfa-c7931bbcc2f5/20210321_150530/db-cluster-a7453f7c.zip loader-set - https://cloudius-jenkins-test.s3.amazonaws.com/a7453f7c-eddb-4777-9cfa-c7931bbcc2f5/20210321_150530/loader-set-a7453f7c.zip monitor-set - https://cloudius-jenkins-test.s3.amazonaws.com/a7453f7c-eddb-4777-9cfa-c7931bbcc2f5/20210321_150530/monitor-set-a7453f7c.zip sct-runner - https://cloudius-jenkins-test.s3.amazonaws.com/a7453f7c-eddb-4777-9cfa-c7931bbcc2f5/20210321_150530/sct-runner-a7453f7c.zip
@yarongilor can you share the logs from hydra-kcl ? i.e. so we see what it's stuck on, and confirm the suspect issue is what we are seeing ?
 slivne
slivne yarongilor
yarongilor nyh
nyh elcallio
elcallio


 roydahan
roydahan DoronArazii
DoronArazii{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Installation details Scylla version (or git commit hash):
4.4.dev-0.20210104.d5da455d9 with build-id 56ab4a808a56049c86c5af7a0f4a680dc37f36d1Cluster size: 6 nodes (i3.4xlarge) OS (RHEL/CentOS/Ubuntu/AWS AMI):ami-018ec229a4231314c(aws: eu-west-1)Test:
longevity-alternator-streams-with-nemesisTest name:longevity_test.LongevityTest.test_custom_timeTest config file(s):Issue description
====================================
scenario:
==> result: YCSB reported verification errors as below.
====================================
Restore Monitor Stack command:
$ hydra investigate show-monitor b71161a4-182a-4447-8a35-9e9c63e89b16Show all stored logs command:$ hydra investigate show-logs b71161a4-182a-4447-8a35-9e9c63e89b16Test id:
b71161a4-182a-4447-8a35-9e9c63e89b16Logs: db-cluster - https://cloudius-jenkins-test.s3.amazonaws.com/b71161a4-182a-4447-8a35-9e9c63e89b16/20210105_233028/db-cluster-b71161a4.zip loader-set - https://cloudius-jenkins-test.s3.amazonaws.com/b71161a4-182a-4447-8a35-9e9c63e89b16/20210105_233028/loader-set-b71161a4.zip monitor-set - https://cloudius-jenkins-test.s3.amazonaws.com/b71161a4-182a-4447-8a35-9e9c63e89b16/20210105_233028/monitor-set-b71161a4.zip sct-runner - https://cloudius-jenkins-test.s3.amazonaws.com/b71161a4-182a-4447-8a35-9e9c63e89b16/20210105_233028/sct-runner-b71161a4.zip
Jenkins job URL
YCSB verification error:
the YCSB insert and read commands as found on SCT yaml file are:
some YCSB write temporary connection issues noticed during test, probably due to decommissions, but overall it reported successful run:
the second YCSB thread running the second range part of inserts, reported successful writing as well:
the issue was also reproduced on another run, using ChaosMonkey of multiple nemesis instead of Decommission nemesis: