 senthilkumarm1901
commented
2 months ago
senthilkumarm1901
commented
2 months ago You can safely ignore to read this section :)
If you have time, checkout the reference links I used for this blog.
VII. Appendix — Section-wise References
I. LLM Project Workflow— Task, Model & Compute
- Inspiration: GenAI Project Life Cycle Diagram by Deeplearning.ai course in Coursera
- Interested in a debate between RAG vs Fine-tuned? AWS Blog
- Interesting discussion on why we instruct fine-tune a base model: Reddit; Similar discussion: Llama 3 vs Llama 3.1 Reddit Thread
{kind=link}
II. Gen AI vs. Traditional ML: Scoping the Right Approach
Do not use Generative AI for these usecases — Refer Article & this matrix of use cases
{kind=link}
III. A. Model Memory
A hugging-face transformer docs that clearly outlines what is inside a model memory: Anatomy of Model Memory
Memory for forward pass activation computation depends on the input batch size, sequence length of input tokens (for e.g.: BERT accpets 512 tokens and GPT 4o accepts 128K tokens) and size of the hidden layers in the architecture
Source: Anatomy of Model Memory
Additionally during training, a model’s memory could also include
- memory occupied by optimizer states
- memory taken up by Gradients
III. B. Model Quantization
- For a better read on the Math behind Quantizations: Refer Introduction to Post Training Quantization Medium Article
V. Next Steps
Questions for pondering:
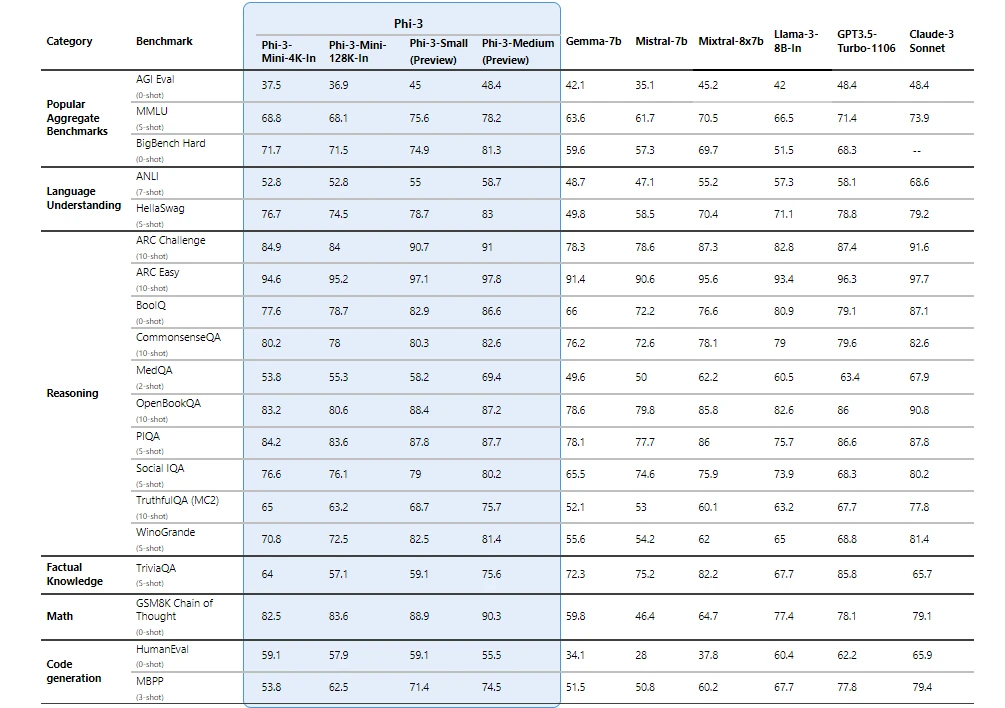
Phi3 Mini 4K model: Huggingface/Microsoft page
Phi3 Mini 128K model: Huggingface/Microsoft page1) Both the above Phi3-mini models have 3.8B parameters. How is the context size increased from 4K to 128K without affecting performance much?
Answer lies in the LongRoPE implemented in Phi3 models. Keeping aside the technical discussions, the LongRoPE method ensures that the performance of the model on shorter context lengths (like 4K tokens) is not compromisedSource for Performance: Microsoft Results comparing 128K and 4K phi3 mini
—
2) But how does the model memory size differ for the same LLM in 4K and 128K contexts?
Both occupy the same model parameter memory size. Refer to the models weights shared in the above huggingface links. Also refer to the source below for more interesting discussionsSources: Reddit discussion comparing Phi 3 mini 4K and 128K
—3) When to use Phi3 Mini 4K and when to use Phi3 mini 128K?
- 4K model best for tasks with shorter or moderately long contexts (obviously!)
- 128K model best for tasks that need longer contexts, like analyzing research papers, books or long customer interactions, where you do not want to truncate input documents
{kind=link}
Formats to store machine learning models for inferencing:
- ONNX (Open Neural Network Exchange) — this format for model storage provides interoperability between different ML frameworks like PyTorch and Tensorflow.
- GGUF (Generic Graph Update Format) — this format is particularly useful for smaller language models that can run effectively on CPUs with 4–8bit quantization.
Learn by Blogging - The Mental Model for Leveraging LLMs in Cloud
In this blog post, we are exploring the intersection of different sized LLMs and their optimal compute environments for deployment
https://senthilkumarm1901.quarto.pub/learn-by-blogging/posts/2024-06-17-how-to-host-open-source-llms-in-aws.html