 sezan92
commented
2 years ago
sezan92
commented
2 years ago Plan
- Video
- TLDR
- how to run
- previous RL blogs
- Why policy gradient method?
- What is reinforce?
- Intuition
- Code walk through (need to plan separately)
- conclusion
Closed sezan92 closed 1 year ago
sezan92
commented
2 years ago sezan92
commented
2 years ago sezan92
commented
2 years ago copy-paste. https://github.com/sezan92/RL_study#reinforce
sezan92
commented
2 years ago check the name if it is correct) we do not learn the policy directly.sezan92
commented
2 years ago sezan92
commented
2 years ago sezan92
commented
2 years ago Still thinking about good intuition.
sezan92
commented
2 years ago sezan92
commented
2 years ago let's think of a game if the action is 1 , you know you will get 10 points, and if 0 you will get -1 points. so our target will be to make the agent give more probability to have action 1.
sezan92
commented
2 years ago sezan92
commented
2 years ago sezan92
commented
2 years ago sezan92
commented
2 years ago the problem is the performance here didn't improve, actually became worse compared to that of DQN family. what are the reasons? Both have same policy. same epsilon greedy technique. I suspect the reason is in the DQN , we were correctly evaluating states. But in the case of reinforce method, we are not correctly getting values. Also reinforce method is known for high variance. so I think next best think is the upgrade to reinforce. Actor-critic methods. DDPG. Deep deterministic policy gradient. let us check it out
sezan92
commented
2 years ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago it is same as previous model , to make fair comparison. it is in RL_study/rl/rl/policy.py
simple architecture
def init(self, s_size=4, fc1_size=150, fc2_size=120, a_size=2): super(Policy, self).init() self.fc1 = nn.Linear(s_size, fc1_size) self.fc2 = nn.Linear(fc1_size, fc2_size) self.final = nn.Linear(fc2_size, a_size)
def forward(self, x): x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.final(x) return F.softmax(x, dim=1)
- Action is a bit different
```python
def act(self, state):
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
probs = self.forward(state).cpu()
m = Categorical(probs)
action = m.sample()
return action.item(), m.log_prob(action)not only returns the action, but also returns the log probability. Why? it is coming later.
sezan92
commented
1 year ago sezan92
commented
1 year ago def reinforce_discrete(
env,
policy,
model_weights_path,
n_episodes=1000,
max_t=1000,
gamma=1.0,
print_every=100,
learning_rate=1e-2
):
scores = []make an optimizer
optimizer = optim.Adam(policy.parameters(), lr=learning_rate)
for i_episode in range(1, n_episodes + 1):
saved_log_probs = []
rewards = []
state = env.reset()
states = [state]
for t in range(max_t):
Get the action and log probability, get the reward, and save the rewards with log probability
action, log_prob = policy.act(state)
saved_log_probs.append(log_prob)
state, reward, done, _ = env.step(action)
rewards.append(reward)
states.append(state)
if done:
break
scores.append(sum(rewards)) expected_rewards = get_expected_reward(rewards, gamma)
state_values = get_state_values(rewards)
policy_loss = []
for i, log_prob in enumerate(saved_log_probs):Advantage according to the equation, get the policy loss and backpropagate
A = expected_rewards[i] - np.mean(expected_rewards)
policy_loss.append((-log_prob * A).float())
policy_loss = torch.cat(policy_loss).sum()
optimizer.zero_grad()
policy_loss.backward()
optimizer.step()
if i_episode % print_every == 0:
print(
"INFO: Episode {}\tAverage Score: {:.2f}".format(
i_episode, np.mean(scores[-print_every:])
)
)
if np.mean(scores[-print_every:]) >= 195.0:
print(
"INFO: Environment solved in {:d} episodes!\tAverage Score: {:.2f}".format(
i_episode - 100, np.mean(scores[-print_every:])
)
)
break
print(f"INFO: Saving the weights in {model_weights_path}")
torch.save(policy.state_dict(), model_weights_path)
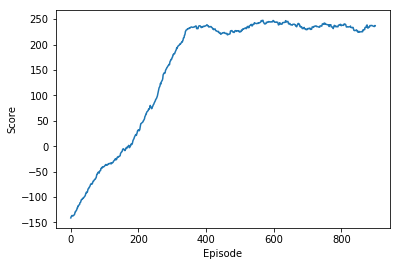
return scoresshow score plot with same number of epochs

sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago Previous models were more stable. Had better scores. Reinforce didnt improve the score. Why? [dont know myself. Need to learn]
sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago Also, there are some limitations associated with REINFORCE algorithm:
The update process is very inefficient. We run the policy once, update once, and then throw away the trajectory.
The gradient estimate is very noisy. There is a possibility that the collected trajectory may not be representative of the policy.
There is no clear credit assignment. A trajectory may contain many good/bad actions and whether or not these actions are reinforced depends only on the final total output.based on https://towardsdatascience.com/policy-gradient-methods-104c783251e0
sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92/rlsezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago sezan92
commented
1 year ago {kind=link}
{kind=link}
Objective
After discrete reinforce method of Reinforcement learning algorithm has been implemented. The next task is to make a blog about reinforce method. This issue is to work on that
Tasks