 shamangary
commented
6 years ago
shamangary
commented
6 years ago 啊,三個輸出是因為我之前在嘗試age estimation時有(classification loss, regression loss, center loss)的組合才有這樣的。另外我這個project是按照 https://kexue.fm/archives/4493 做出來的完整範例,要感謝蘇大。
根據你的error你的l2_loss是(?,?,?,?)還蠻奇怪的。四個維度都變成batchsize的感覺,先檢查一下吧。 至於fit_generator我記得要定義輸入的X和Y是多少
類似這樣
hist = model.fit_generator(generator=data_generator_centerloss(X=[x_train, y_train_a_class_value], Y=[y_train_a_class, random_y_train_a], batch_size=batch_size),
steps_per_epoch=train_num // batch_size,
validation_data=([x_test,y_test_a_class_value], [y_test_a_class, random_y_test_a]),
epochs=nb_epochs, verbose=1,
callbacks=callbacks)data generator例子:
def data_generator_centerloss(X,Y,batch_size):
X1 = X[0]
X2 = X[1]
Y1 = Y[0]
Y2 = Y[1]
while True:
idxs = np.random.permutation(len(X1))
X1 = X1[idxs] #images
X2 = X2[idxs] #labels for center loss
Y1 = Y1[idxs]
Y2 = Y2[idxs]
p1,p2,q1,q2 = [],[],[],[]
for i in range(len(X1)):
p1.append(X1[i])
p2.append(X2[i])
q1.append(Y1[i])
q2.append(Y2[i])
if len(p1) == batch_size:
yield [np.array(p1),np.array(p2)],[np.array(q1),np.array(q2)]
p1,p2,q1,q2 = [],[],[],[]
if p1:
yield [np.array(p1),np.array(p2)],[np.array(q1),np.array(q2)]
p1,p2,q1,q2 = [],[],[],[] tinazliu
tinazliu

 lily0101
lily0101 wangjue-wzq
wangjue-wzq
大大您好,謝謝你提供這麼棒的source code,讓我受益良多 :) 以下我有一些關於fit generator的問題,還望大大能夠解惑~
問題1:
以上是大大提供fit_generator的範本,我好奇的是為何
Y=[y_train_a_class,y_train_a, random_y_train_a]有3個輸出 ?y_train_a代表什麼意思? 會有這個好奇點是因為我看在TTY.mnist.py是用.fit實踐的 -->model_centerloss.fit([x_train,y_train_value], [y_train, random_y_train], batch_size=batch_size, epochs=epochs, verbose=1, validation_data=([x_test,y_test_value], [y_test,random_y_test]), callbacks=[histories]),照我的理解,其為雙輸入雙輸出的格式。故我覺得.fit_generator也要為雙輸入雙輸出~問題2
我依照雙輸入和雙輸出的想法建構自己的fit_generator,出現一個很奇怪的問題 以下是我輸入和輸出的 .shape,感覺大小是正確的
以下是我輸入和輸出的 .shape,感覺大小是正確的
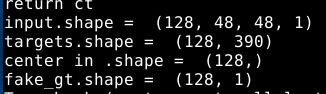
所以有點摸不著頭緒,是不是我的generator和l2_loss的格是不相符,不過我看l2_loss的型態都是?,感覺怪怪的QQ
補充
以下是我實作generator的方式:,我的generator會return這些東西 然後我的fit_generator是這樣實踐的
然後我的fit_generator是這樣實踐的
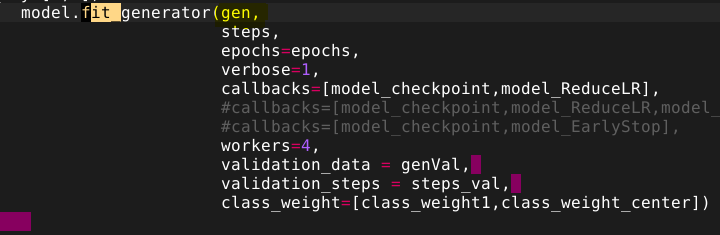
不好意思打擾您,真的很謝謝你提供那麼棒的程式,讓我在實踐center loss時有一個很棒的參考對象~謝謝
,Tina