 iperov
commented
6 years ago
iperov
commented
6 years ago paper will be released in august. I dont think it is easy to implement from scratch without a bunch of pretrained estimator models, which not exists in free access. Also I think minimum GPU vram req for such result is 16GB.
 Jack29913
Jack29913 Neltherion
Neltherion shaoanlu
shaoanlu mrgloom
mrgloom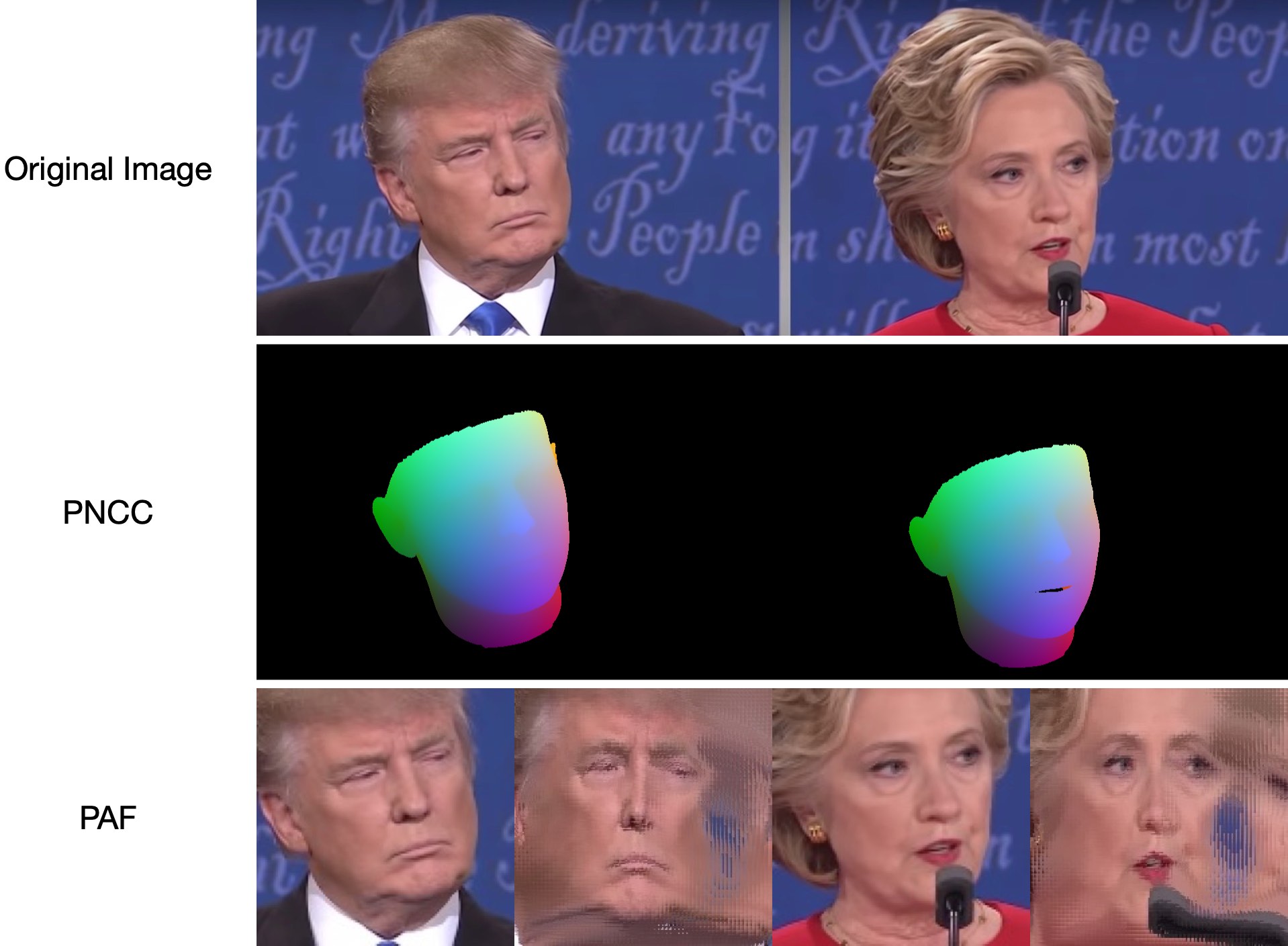{kind=link}
I was wondering what your opinion is about Deep Video Portraits?