 furkanmustafa
commented
6 years ago
furkanmustafa
commented
6 years ago - adding or removing (or crashing) gateway only nodes are also resetting recovery process. I believe there is no reason for any gateway node to affect recovery/reweight process.
 vtolstov
vtolstov
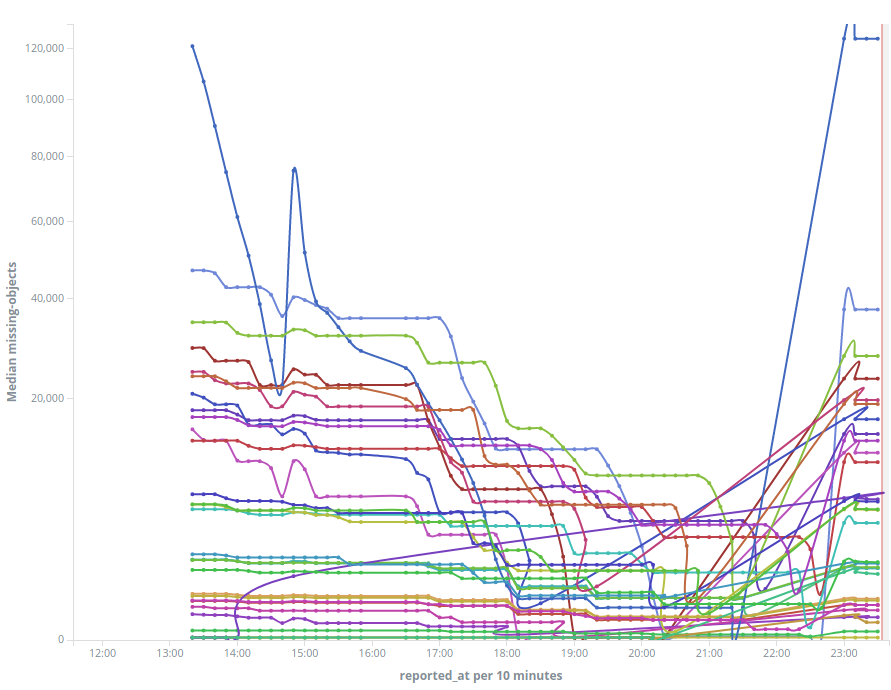
I am using v1.0.1, compiled from github tag, on ubuntu14.04, with corosync. 7~10 TB total md size.
I had 7 nodes on my experimental setup. One of the nodes suddenly failed, and automatic-recovery (reweight) kicked in, which caused lots of IO on other nodes. And that caused some other nodes to crash. My nodes are set to restart after crash. But now my cluster is in recovery loop that never succeeds.
Also it continuously increases disk usage until disk is full on some nodes (in .stall folder). If the disk is full, the node cannot start again, and other nodes cannot see the objects those nodes have, and cannot properly recover.
Lot's of points could be suggested to improve at this point, like;
dog cluster recovery disabledoes not work until the cluster is healthy. An option to disable recovery on init would be helpful. Otherwise everytime a node dies/comes-back, the whole operation is restarting, which takes hours and hours to recover each node.I'm currently still trying to recover the cluster (for the last 30~40 hours).
Any suggestions would be really helpful.