 simonw
commented
3 years ago
simonw
commented
3 years ago I've done various pieces of research into this over the past few years. Capturing what I've discovered in this ticket.
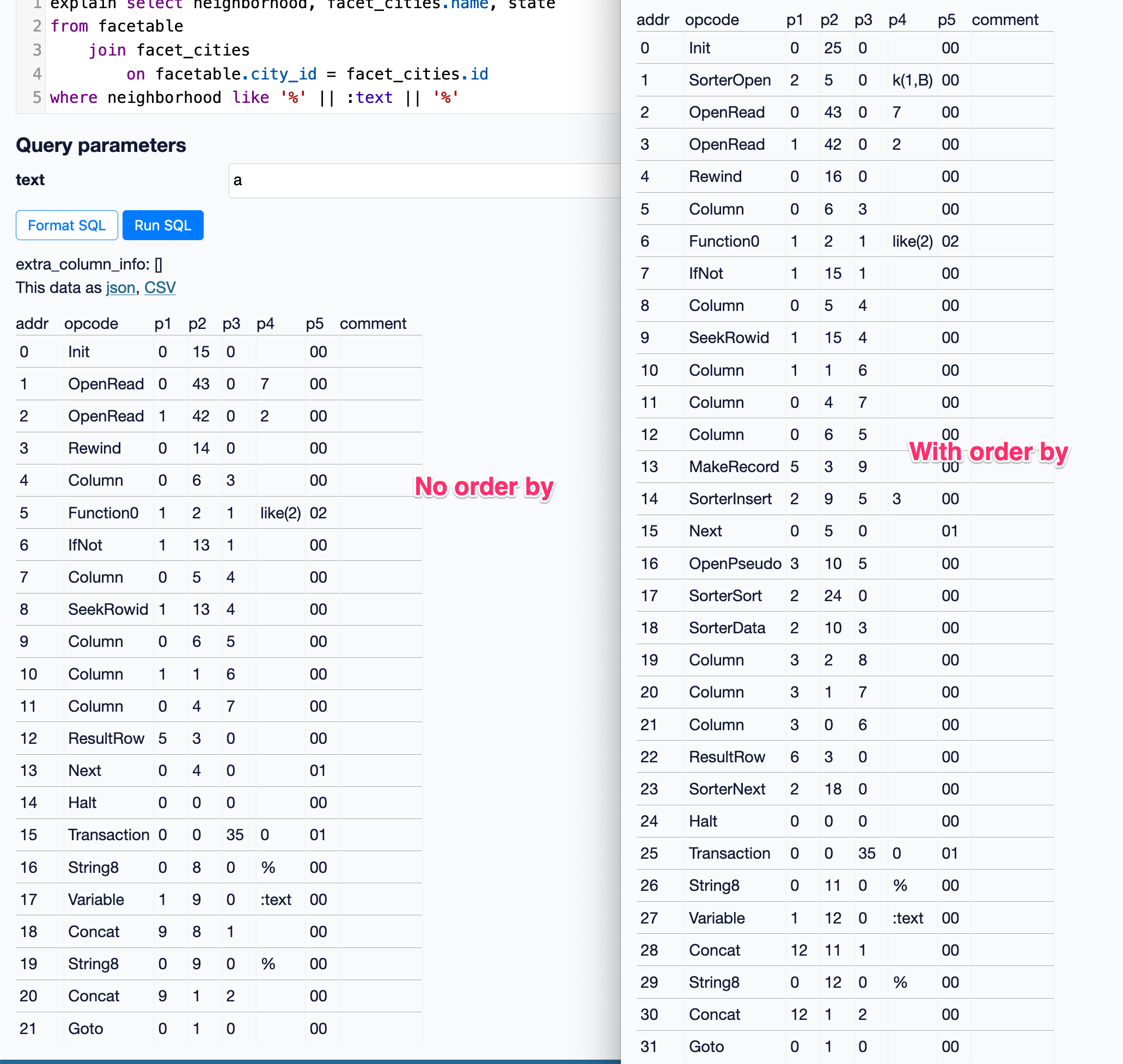
The SQLite C API has functions that can help with this: https://www.sqlite.org/c3ref/column_database_name.html details those. But they're not exposed in the Python SQLite library.
Maybe it would be possible to use them via ctypes? My hunch is that I would have to re-implement the full sqlite3 module with ctypes, which sounds daunting.

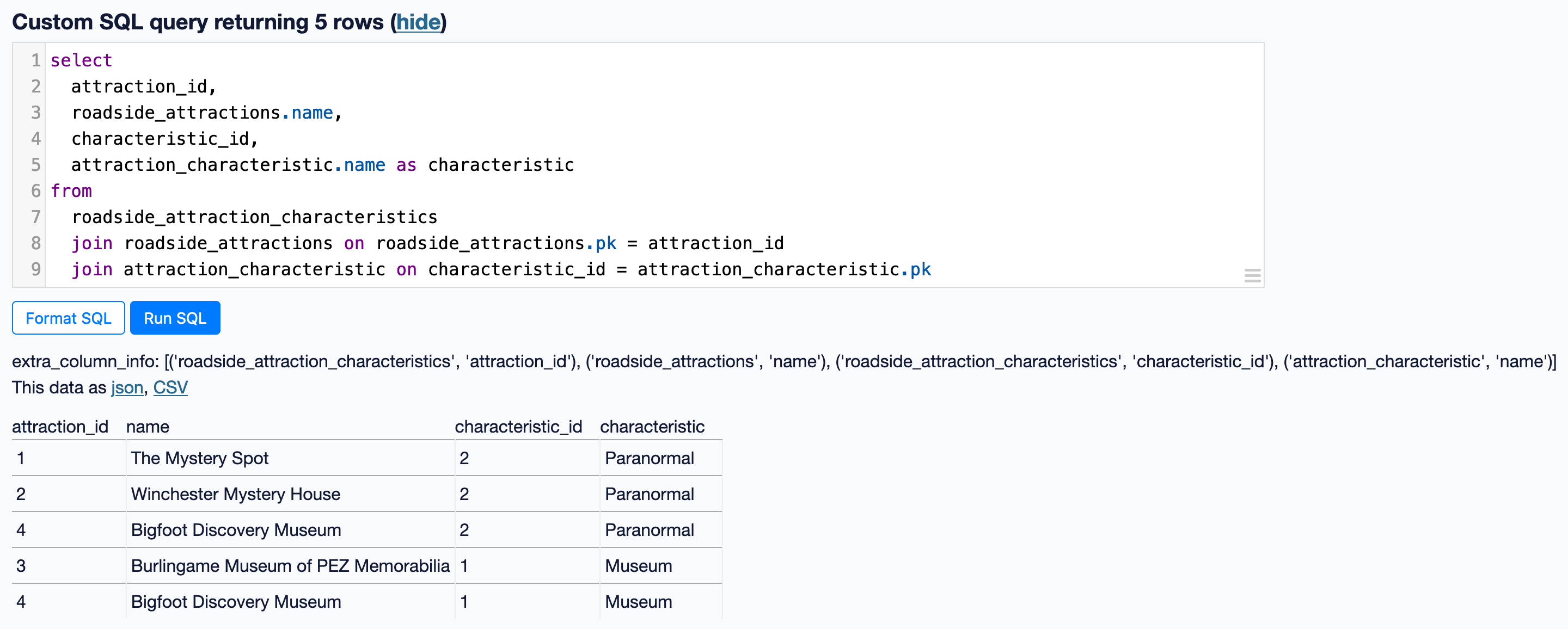



Related to #620. It would be really cool if Datasette could magically detect the source of the data displayed in an arbitrary query and, if that data represents a foreign key, display it as a hyperlink.
Compare https://latest.datasette.io/fixtures/facetable
To https://latest.datasette.io/fixtures?sql=select+pk%2C+created%2C+planet_int%2C+on_earth%2C+state%2C+city_id%2C+neighborhood%2C+tags%2C+complex_array%2C+distinct_some_null+from+facetable+order+by+pk+limit+101