 kizuner-bonely
commented
4 years ago
kizuner-bonely
commented
4 years ago 大致思路:
- 新建一个变量 result 用于存储重叠部分
- 对传入数组进行遍历
- 第一次遍历时变量 result 即为第一个元素
- 之后每次遍历都找出开头重叠部分,重叠部分只能保持不变或变少,当有一次为空时停止遍历 (arr.some())
比较字符串方法:
- 将字符串转换为数组
- 通过字符串下标进行比较
function overlap(arr) {
var result = '';
var firstTime = true;
arr.some(function (item) {
if( typeof item !== 'string') return false;
if( firstTime ) { // 考虑了数组第一个元素可能不是字符串的情况
result = item;
firstTime = false;
return false; // 第一次填充字符串的话后面的代码就不用执行了
}
// 筛选出当前遍历字符串与 result 的交集
result = filterString(result, item);
// 每次遍历后都判断当前重叠部分是否为空,若为空直接返回
if( !result ) return true;
})
return result;
}
// 比较字符串方法一:将字符串转为数组
function filterString(str1, str2) {
var result = '';
var arr1 = str1.trim().split(''),
arr2 = str2.trim().split('');
arr1.some(function (item, index) {
if( item === arr2[index] ){
result += item;
return false;
}
return true;
});
return result;
}
// 比较字符串方法二:通过字符串下标比较
function filterString(str1, str2) {
var result = '';
for( var i = 0; i < str1.length; i++ ){
if( str1[i] === str2[i] ){
result += str1[i];
continue;
}
return result;
}
return result; // 当两个比较的字符串一模一样的时候就会走到这里
} fanefanes
fanefanes lokewei
lokewei sisterAn
sisterAn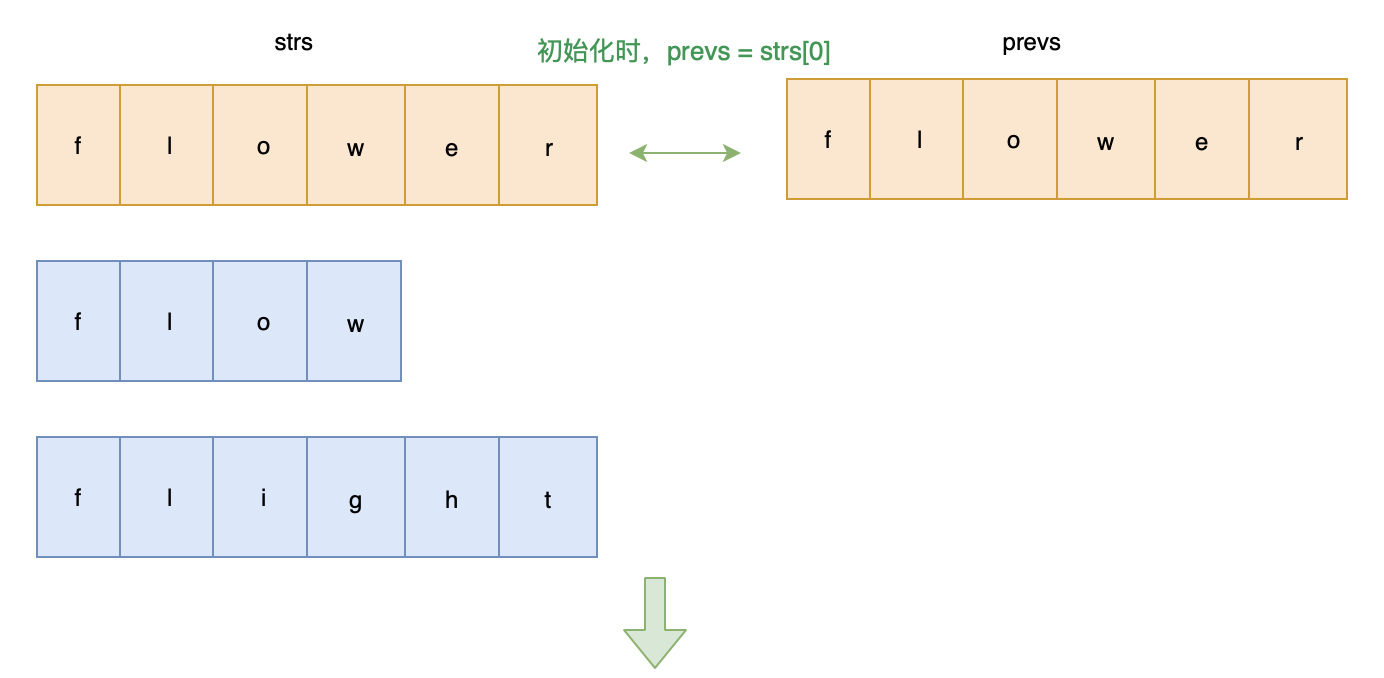

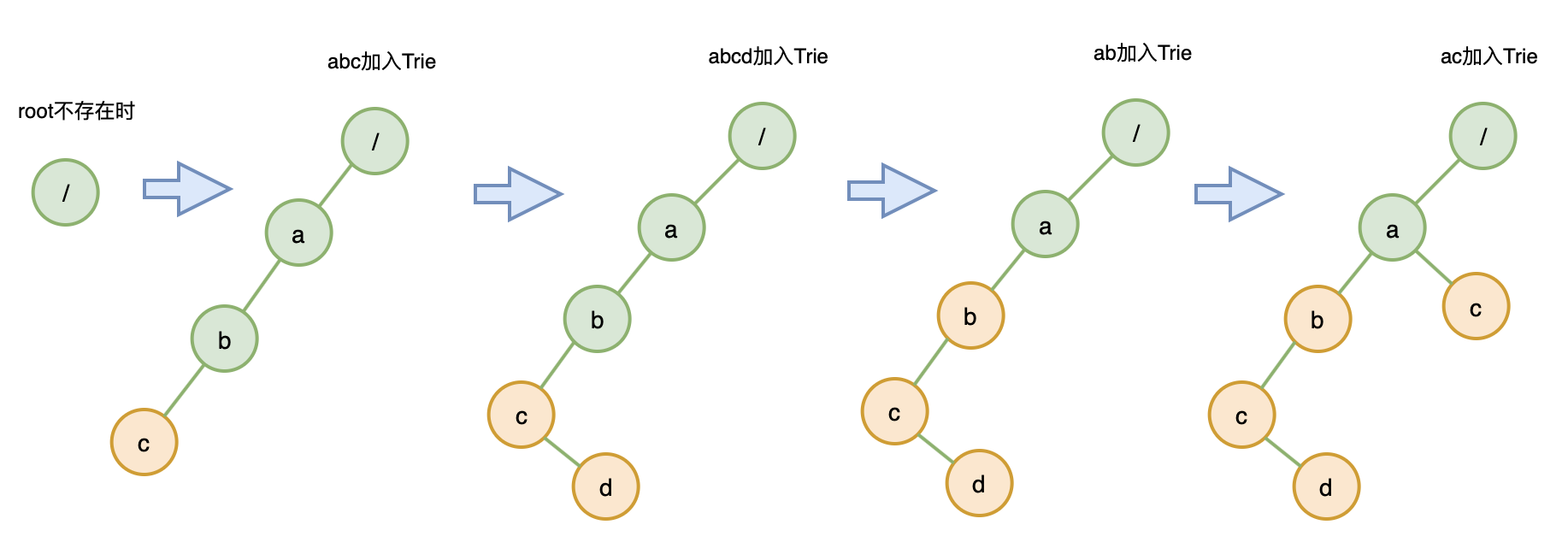
 thxiami
thxiami
 zero9527
zero9527 zhaojinzhao
zhaojinzhao xiaohaifengke
xiaohaifengke shufei021
shufei021 guanping1210
guanping1210 ajaxlinux1234
ajaxlinux1234 Aaminly
Aaminly Been101
Been101 CarberryChai
CarberryChai qianlongo
qianlongo python-D
python-D XW666
XW666 JackTam1993
JackTam1993 AlexZhang11
AlexZhang11
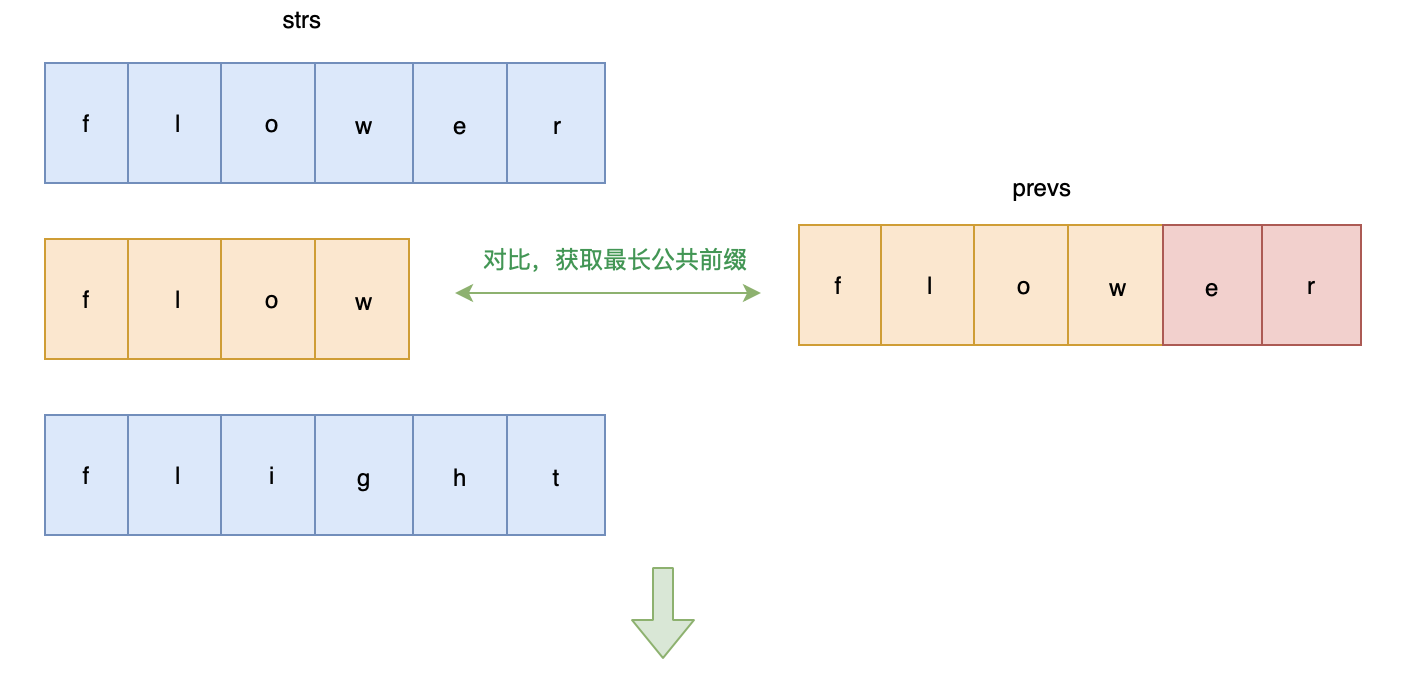
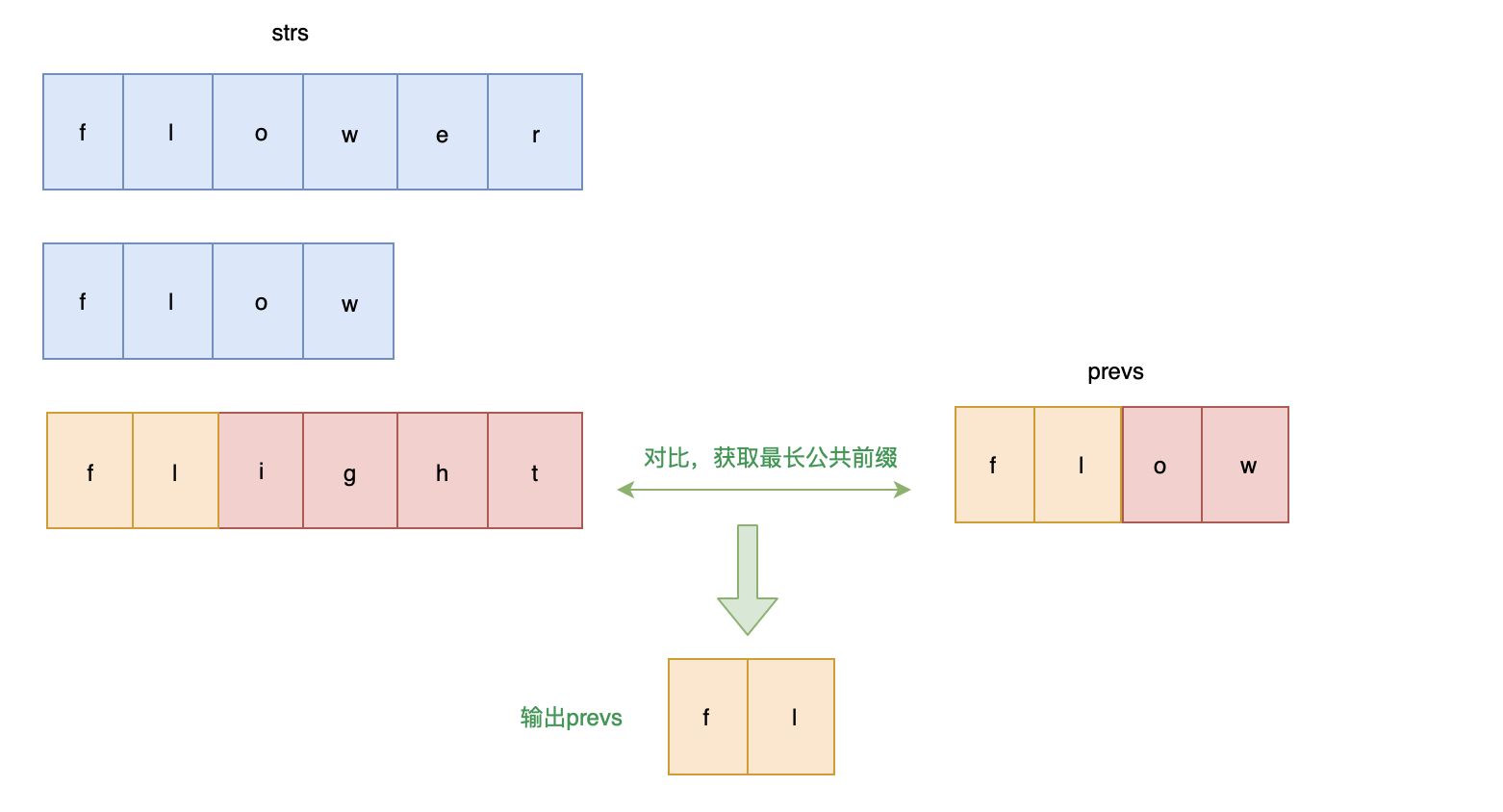
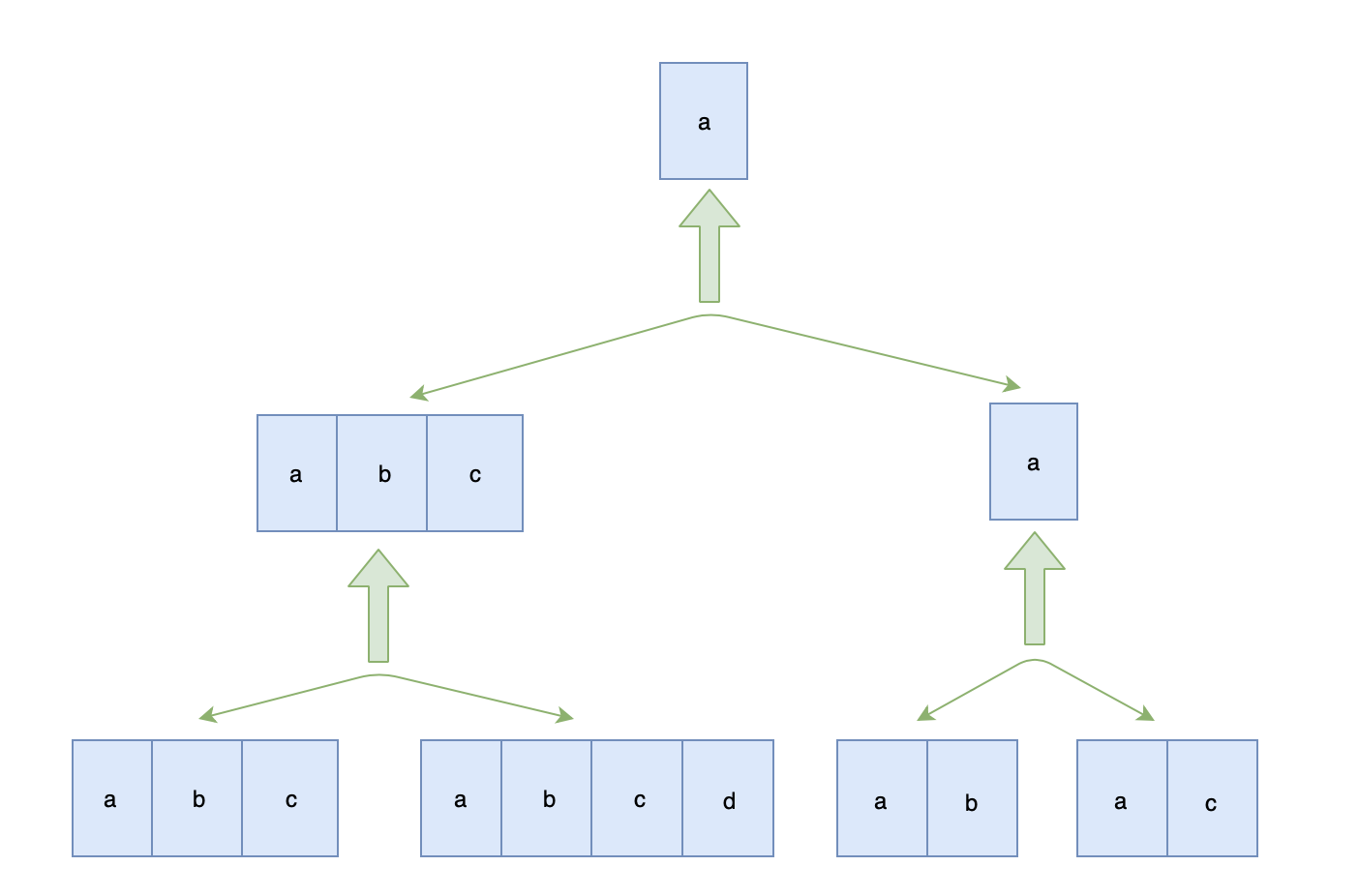
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串
""。示例 1:
示例 2:
附leetcode:leetcode
场景案例【网易】: 有一个场景,在一个输入框输入内容,怎么更加高效的去提示用户你输入的信息,举个例子,你输入天猫,那么对应的提示信息是天猫商城,天猫集团,这个信息如何最快的获取,有没有不需要发请求的方式来实现?
提示: