 skvadrik
commented
2 years ago
skvadrik
commented
2 years ago You should use @@ instead of 0 in YYSETSTATE:
re2c:define:YYSETSTATE = "bufInfo->state = @@;";The point here is that only re2c knows what the correct state is, but not the user. Each time re2c generates YYSETSTATE, it substitutes @@ with the correct state. The actual state is different for different YYSETSTATE invocations in the lexer.
As for -1, it is always used as the default state in re2c. Maybe we should say this more explicitly in the docs.
See this example if you haven't already and the description of re2c:api:sigil condiguration.
 krishna116
krishna116
This is the code I sketched to get a list of tokens from a string using re-entry mode. I using this code for example.
the above code's output is: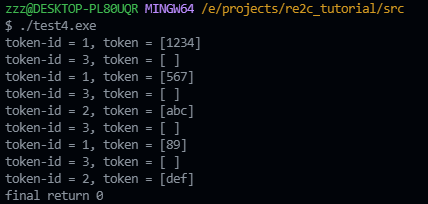
So the advice is:
1, in the main function the initial bufInfo.state = -1, it could be:
#define RE2C_STATE_INIT -12, in the lex function, I set "bufInfo->state = 0" to restore, because I guess it is always the begining/start/nothing-matched state, if so it could be:
#define RE2C_STATE_BEGIN 03, the code may be not good, if so I always like to listen the advice.
thank you.