 dblock
commented
6 years ago
dblock
commented
6 years ago I am seeing the same thing on larger production bots. I am going to guess this is slack-side, but it also looks like we're not seeing/handling the disconnect properly somehow. I would say first lets understand what we expect on a disconnect like this? An exception?
 Kyrremann
Kyrremann aoberoi
aoberoi alexagranov
alexagranov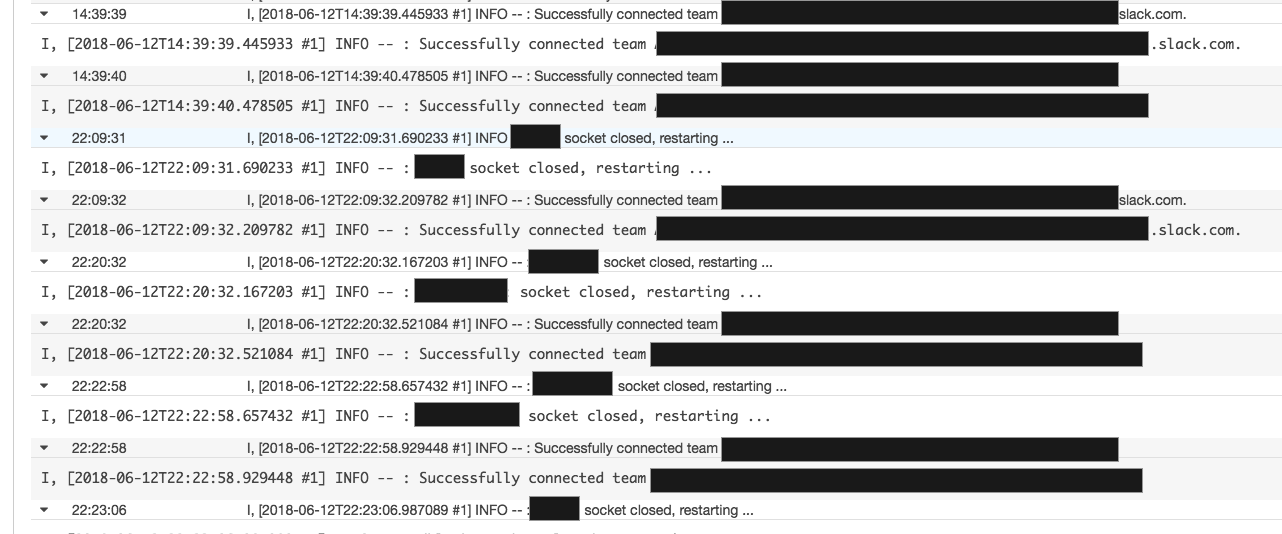
 andrewhood125
andrewhood125 jhawksley
jhawksley ioquatix
ioquatix olingern
olingern jonmchan
jonmchan gsmetal
gsmetal joegoggins
joegoggins

 mattbrictson
mattbrictson TallOrderDev
TallOrderDev schneidmaster
schneidmaster
In the last week my slack bot has started to disconnect from our Slack team. There are no logs of disconnect, or stack traces. I've started running the bot in debug-mode, and the last thing it logged before it disconnected was the following.
I'm not sure how to debug this my self, and I have no idea for what is wrong.
My setup is running on Google App Engine, with one process for a Sinatra web and a different process running the slackbot. Neither of the process stops, but the bot is offline in Slack.
The code for the project is available here: https://github.com/navikt/standbot
Any help would be welcoming!