 slevin48
commented
1 year ago
slevin48
commented
1 year ago Open slevin48 opened 1 year ago
slevin48
commented
1 year ago slevin48
commented
1 year ago https://github.com/mobarski/ask-my-pdf https://ask-my-pdf.streamlit.app/
Debug enables to understand the breakdown of the approach in the function index_file

Extract text (pages) from pdf file (with PyPDF): https://github.com/mobarski/ask-my-pdf/blob/main/src/pdf.py
import pypdf
def pdf_to_pages(file):
"extract text (pages) from pdf file"
pages = []
pdf = pypdf.PdfReader(file)
for p in range(len(pdf.pages)):
page = pdf.pages[p]
text = page.extract_text()
pages += [text]
return pagessave doc and index on S3 https://github.com/emptycrown/llama-hub/tree/main/loader_hub/s3
from llama_index import download_loader
S3Reader = download_loader("S3Reader")
loader = S3Reader(bucket='scrabble-dictionary', key='dictionary.txt', aws_access_id='[ACCESS_KEY_ID]', aws_access_secret='[ACCESS_KEY_SECRET]')
documents = loader.load_data()Or manually:
import boto3
s3_client = boto3.client('s3',aws_access_key_id = st.secrets["aws"]["aws_access_key_id"],
aws_secret_access_key = st.secrets["aws"]["aws_secret_access_key"])
s3_client.download_file(s3_bucket, object_name,file_name)Change QA example to https://www.impromptubook.com/
slevin48
commented
1 year ago Ask questions about Teams meetings:

slevin48
commented
1 year ago slevin48
commented
1 year ago slevin48
commented
1 year ago slevin48
commented
1 year ago slevin48
commented
1 year ago 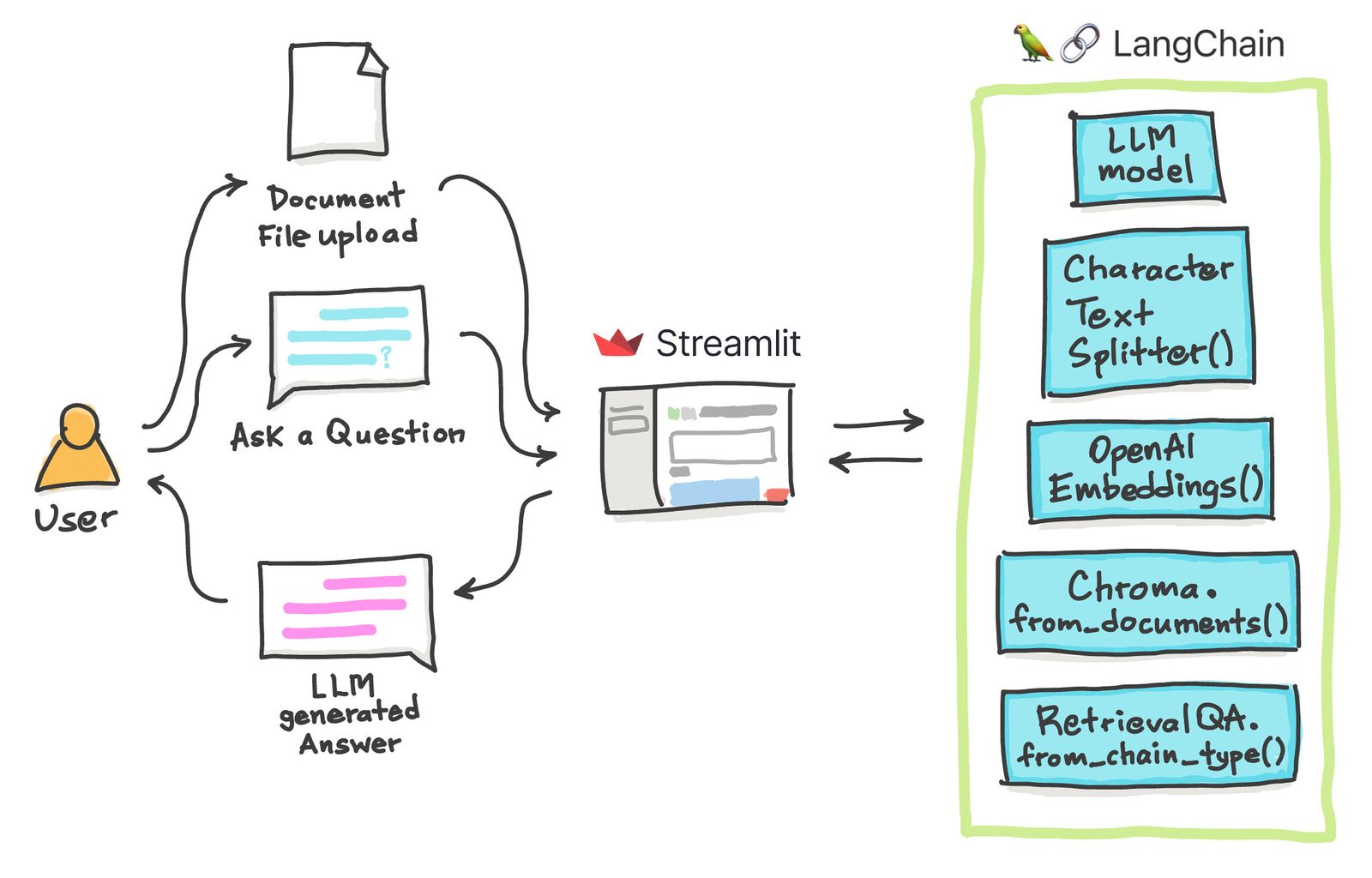
Like www.chatpdf.com