 snarfed
commented
8 years ago
snarfed
commented
8 years ago the really annoying part is that we don't actually need more than one instance, but app engine's scheduler doesn't handle us well and thinks we do, so it usually keeps two or three around. from https://console.developers.google.com/appengine/instances?project=brid-gy&moduleId=default&versionId=7&duration=P1D :

this is the norm. one instance serves almost all of the requests; the remaining instance(s) serve almost none.
details on how app engine's request scheduler/auto scaler works in the links below. i've tried lots of different values (including default) for Max Idle Instances and Min Pending Latency, different instance classes, and other settings, but haven't managed to change this behavior. :/
- https://cloud.google.com/appengine/docs/python/scaling#scaling_dynamic_instances
- https://cloud.google.com/appengine/docs/python/console/managing-resources#change_auto_scaling_performance_settings
- https://cloud.google.com/appengine/docs/python/modules/#Python_Instance_scaling_and_class
basic and manual scaling are tempting, but only get 8 free instance hours per day, as opposed to automatic scaling's 28, so they're right out.
@kylewm and i talked a bit on IRC just now on profiling. our request volume is mostly poll and propagate (~87% and ~9% each, respectively), both of which i expect spend most of their time blocked on network I/O. good idea to check, though. app stats is great for that; we can turn it on here.
the poll task queue is currently configured to run up to 2 at a time, propagate up to 1 at a time, and we have threadsafe: yes in our app.yaml to allow instances to serve multiple requests concurrently. last time i checked with bridgy's instance info recording, this was indeed happening.








 kylewm
kylewm


















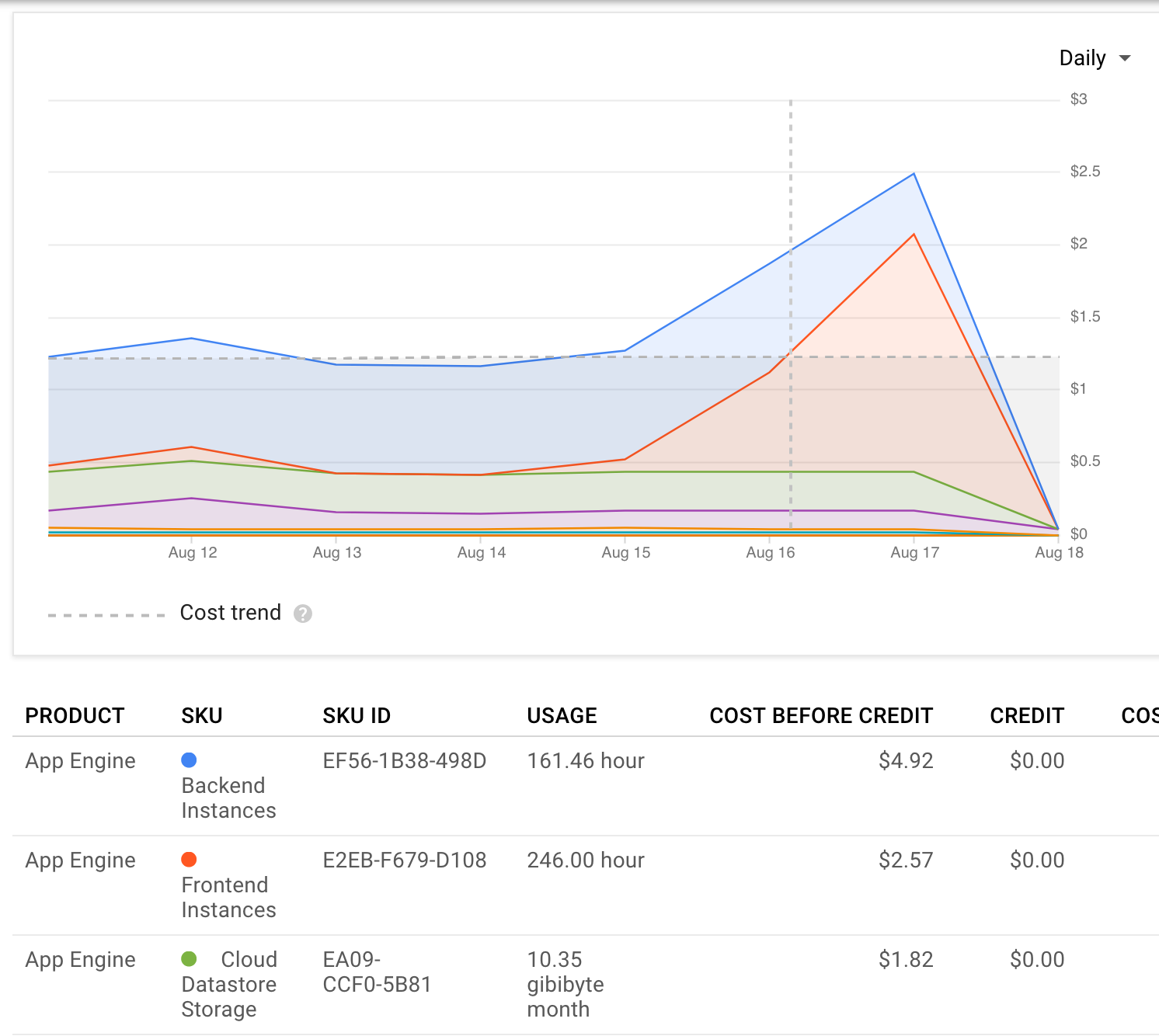
we average ~2 app engine frontend instances right now, and they cost money (at least above the first), so i've been experimenting with different tuning knobs to see if i can get that average down a bit. this isn't high priority, and i'm also not sure i can have much impact without making drastic changes, so this is mostly just for tracking.
directly related:
90 figure out why requests aren't running concurrently (enough)
110 optimize poll task
loosely related:
8 find an alternative to the resident backend for twitter streaming
53 get backend memory usage below cap
145 cache in instance memory as well as memcache
300 try dedicated memcache
here are a few things i've tried recently, and the results. tl;dr: none of them had a meaningful effect on instance count.