 cyrf0006
commented
8 years ago
cyrf0006
commented
8 years ago Here are examples of navigations files (.gli.) and science files (.dat.), together with the glider's configuration (*.cfg) file that is read by the glider. For the moment, I need to manually edit this file to add extra fields during post-processing. These files should be read by an eventual loadSeaexplorerData.m function. This method is in development and may change in the future.
 joanpau
joanpau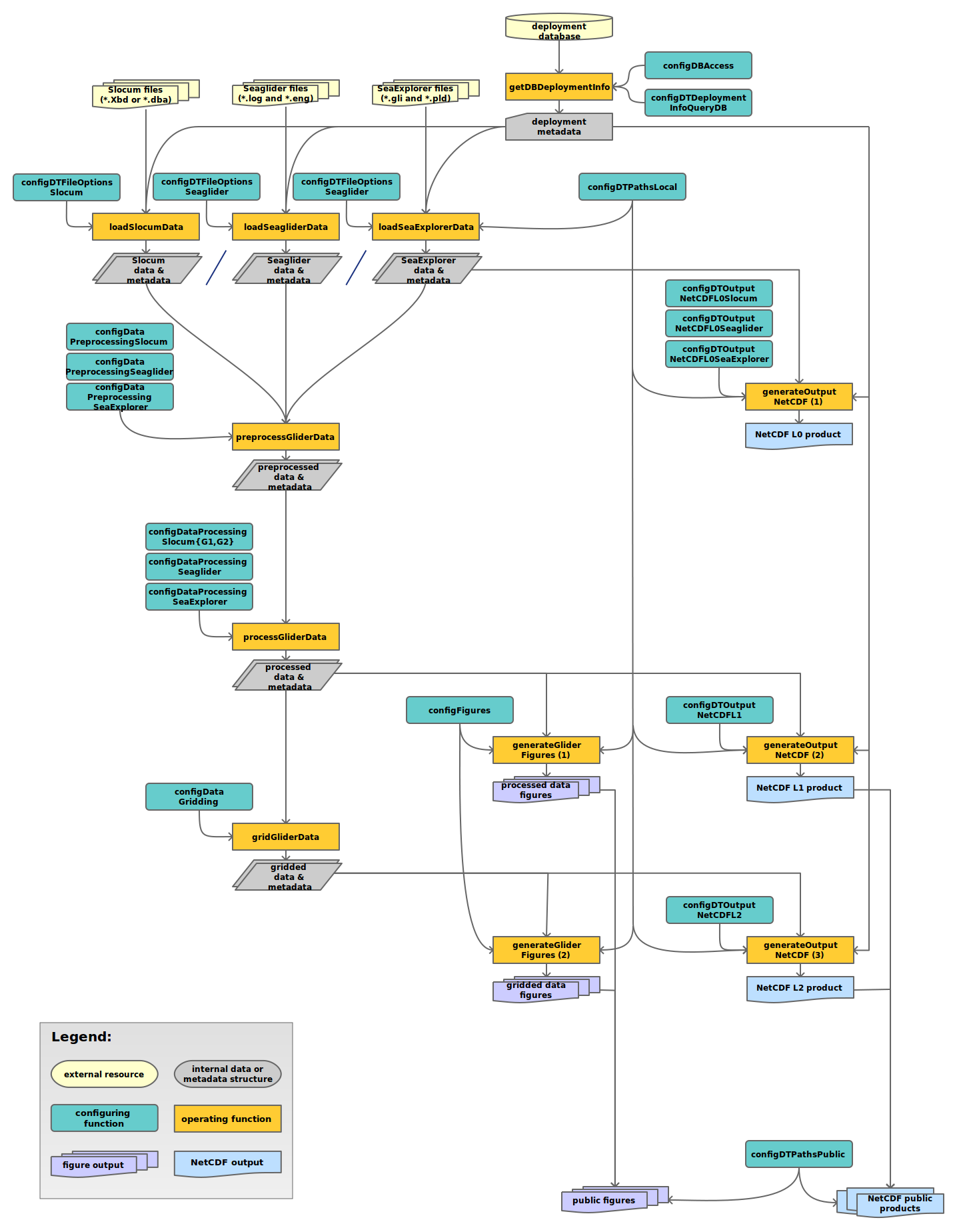{kind=link}
Attempt to include SeaExplorer gliders in the toolbox. Modifications to the toolbox would include functions such as:
Please refer any suggestion/questions to Frederic.cyr@mio.osupytheas.fr